











 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
1. Introducción
El incremento en el uso de la tecnología en los procesos organizativos ha venido generando un crecimiento en la demanda de los servicios de las áreas de infraestructura tecnológica (TI), específicamente los relacionados con la gestión de incidentes. De acuerdo con la Biblioteca de Infraestructura de Tecnología de la Información (ITIL), tal proceso busca resolver, rápida y eficazmente los problemas que causen interrupción en el servicio [1].
Uno de los tópicos de investigación con mayor popularidad al respecto es la clasificación de incidentes, la cual busca asignarlos de forma correcta a los equipos técnicos encargados de dar solución a cada incidente [2]. La clasificación adecuada de un incidente es esencial para dirigirlo rápidamente al equipo correcto y, así, evitar reprocesos por devoluciones y minimizar su tiempo de solución [1]. De hecho, una mala clasificación genera ineficiencias en el recurso humano, aumenta el tiempo de resolución y disminuye la satisfacción del usuario final [1].
A pesar de la importancia de dicho proceso de clasificación, su desempeio en las organizaciones amerita intervenciones de mejora, debido, entre otros aspectos, a la alta dependencia de actividades humanas que derivan en sesgos interpretativos del agente clasificador [2]. Ello puede corroborarse en estudios recientes, en ámbitos como los de servicios de tecnología [3] y aviación [4].
Uno de los principales recursos hoy en día para reducir la subjetividad humana en la clasificación de incidentes corresponde a los métodos de aprendizaje automático (machine learning, en inglés). A pesar de ello, su desempeio no debe asumirse desde un enfoque universalista, ya que no existe un único método que siempre conduzca al mejor resultado en todo tipo de contexto. Tal desempeio depende de variedad de factores, entre ellos: el conjunto y la naturaleza de los datos, las tareas de preprocesamiento (ej., en la descripción narrativa del incidente) y los parámetros del algoritmo [1]. De ahí la sugerencia de estudios como [4,5] de entender las particularidades de cada escenario y realizar una comparativa entre varios métodos y tipos de características (predictores), en busca de la alternativa más adecuada a cada escenario de estudio.
Esta necesidad es aún mayor, al considerar el escenario de compaiías de seguros, cuya supervivencia y éxito son altamente sensibles a riesgos reputacionales derivados de la insatisfacción del usuario, a causa de los reprocesos y el incremento de tiempos/costos que traen consigo la clasificación de incidentes tecnológicos [7]. Adicionalmente, la literatura científica poco ha discutido sobre el abordaje de este problema en escenarios de seguros, desde un enfoque de aprendizaje automático. La mayoría de las aplicaciones al respecto se han realizado en ámbitos de servicios de compaiías de aviación [4], tecnología [6] y salud [7]. Este hecho limita la comprensión acerca de qué método presenta mejores niveles de desempeio en el ámbito de pólizas de seguros. Asimismo, se hace necesario validar si en tal escenario las variables de texto, alusivas a la descripción del incidente tecnológico, son suficientes para entrenar/validar modelos altamente precisos, como lo reportó [5]; o, por el contrario, valdría la pena combinarlas con datos estructurados, como sucedió en [2].
Con miras a una mejor claridad del tema, este artículo analiza datos de una compaiía de seguros en Colombia desde un enfoque de aprendizaje automático para dar respuestas a dos interrogantes:
P1 ¿Qué método, entre áiboles de clasificación, máquinas de vectores de soporte, random forest, regresión logística y análisis lineal discriminante, presenta las mejores tasas de clasificación de incidentes para la suscripción de pólizas de seguros?
P2 ¿Qué implicaciones prácticas pueden atribuírsele al modelo con el mejor desempeio en el escenario de seguros observado, considerando la clasificación actual del agente humano?
Mediante el abordaje de las preguntas expuestas, este artículo contribuye con lo siguiente:
Provee información sobre las particularidades del escenario de clasificación de incidentes en el ámbito de seguros, desde un enfoque de aprendizaje automático. Por tanto, sirve de guía para investigaciones futuras al respecto, en lo que concierne al método de aprendizaje y la naturaleza de los datos que resultaron más útiles en tal contexto.
Asiste la toma de decisiones en el ámbito estudiado, respecto a cómo mejorar el desempeio del proceso de clasificación de incidentes para la suscripción de pólizas de seguros, a través de métodos intensivos en computación. De hecho, en el escenario observado, cerca del 34% de los incidentes tecnológicos reportados por sus expedidores de pólizas son clasificados erróneamente por el agente humano, lo cual deriva en ineficiencias internas e insatisfacción del usuario final, debido a reprocesos y largos tiempos de espera (cerca de 12 días por cada incidente mal clasificado).
El artículo cuenta con las siguientes secciones: La sección 1 expuso la introducción, en la cual se justificó el estudio. La sección 2 aporta la revisión de literatura llevada a cabo. La sección 3 describe los materiales y métodos orientados al entrenamiento de cinco modelos de aprendizaje automático, así como a la validación y comparación con el agente humano. La sección 4 aporta los resultados obtenidos para las dos preguntas expuestas, considerando tres escenarios de análisis (datos estructurados, textos y ambos). La sección 5 provee las conclusiones y el trabajo futuro.
2. Revisión de literatura
Esta sección se apoyó en lineamientos de alfabetización informacional, sin ser alcance del presente manuscrito realizar una revisión sistemática. Iniciamente, la búsqueda se realizó por medio de las bases de datos Scopus y Web de la Ciencia, empleando el término "aprendizaje automático" en conjunto con expresiones alusivas a dominios de incidentes tecnológicos bajo mesas de ayuda. Tales consultas arrojaron pocos trabajos al respecto (ej., en Scopus nueve documentos fueron reportados usando TITLE ("machine learning") AND TITLE ("help desk" OR "service desk systems" OR "IT incidents" OR "IT service delivery" OR "ticket classification" OR "incident ticket" OR "IT Tickets" OR "IT Service"). Esto llevó a extender la consulta a la sección de referencias citadas por tales trabajos, así como a explorar otras fuentes por medio de Google Académico. A medida que se fueron recuperando documentos al respecto, se verificaba el título/resumen y luego el texto completo, con el fin de corroborar el tema y dominio de acción, así como el hecho de que correspondieran a trabajos empíricos. Finalmente, considerando la afinidad (desde la óptica de los autores) entre los propósitos del presente estudio y los documentos localizados, catorce trabajos fueron tomados como base para el desarrollo de la presente sección. A continuación, se describen los principales elementos de soporte.
La Tabla 1 muestra la preponderancia de los servicios de infraestructura de TI para la clasificación de incidentes usando un enfoque de aprendizaje automático, con una participación en 12 (86%) de los 14 trabajos de referencia.


Asimismo, emerge la necesidad de comprender el tema en otros dominios, encontrándose, en esta oportunidad, experiencias en ámbitos de salud y aviación.
Por otro lado, la Tabla 2 provee una síntesis de los atributos que los trabajos revisados emplearon para entrenar los modelos de clasificación de incidentes.
La Tabla 2 muestra que el 79% de los estudios ha utilizado como atributo de entrada la descripción (o cuerpo del incidente). En segundo lugar, se encuentra el título (o asunto) del incidente, con participación en el 36% de los estudios revisados. Otros atributos, como el equipo de solución, la fecha, la criticidad, la prioridad y el texto de solución o cierre, son utilizados en menor medida por estudios que se interesan no solo por la clasificación del incidente sino también en la predicción de fallas de equipos. Cabe resaltar que solo uno de los estudios revisados utilizó todos los atributos del incidente para la clasificación automática.
En general, los mejores resultados reportados por los trabajos previos han sido atribuidos al uso del título (o asunto) y la descripción del incidente. Es decir, datos en formato texto, los cuales son complejos de abordar dada la diversidad de agentes, conocimientos/capacidades, estilos de escritura y conocimientos previos del productor del texto. De ahí la importancia de considerar recursos de minería de textos dentro de los modelos de aprendizaje automático [4].
En la Tabla 3 se describe la variable objeto de clasificación, reportada por los trabajos revisados. En dicha tabla se observa que la variable respuesta de mayor interés por los trabajos de referencia fue el tipo de problema (ej., apagado inesperado, reinicio, hardware defectuoso), con una participación del 71%, seguido del àrea de solución (ej., equipo de bases de datos, administradores de red y servidores), con un 21%. La variable respuesta identificada como servidor que presentó fallos representa el 14%. Con respecto a las etapas empleadas para abordar la clasificación de incidentes, los trabajos de referencia suelen coincidir en el siguiente derrotero: recolección de datos, preprocesamiento de los datos, construcción del vector de características, selección del método de clasificación, entrenamiento del modelo, clasificación y validación comparativa entre métodos seleccionados. Al considerar datos de textos, es fundamental emplear tareas como "tokenización", remoción de palabras vacías (ej., stopwords), de expresiones poco relevantes (ej., con uso de la frecuencia de términos - frecuencia inversa de documentos TF-IDF) y, en casos, de operaciones de lematización y/o reducción de expresiones a su raíz [7]. Es así como [9] senalan que un modelo de aprendizaje automàtico adecuado para la clasificación del servicio de incidentes depende de los datos de entrenamiento, del preprocesamiento del texto, de la vectorización de características, del algoritmo de aprendizaje automàtico y de los paràmetros del algoritmo.

Con respecto a la fase de construcción del vector de características, [6] senalan que, para implementar los modelos de clasificación, los datos que se han de utilizar en la fase de entrenamiento deben ser convertidos a representación vectorial. Para la construcción del vector de características, [12] sugiriere aplicar la ponderación booleana o la frecuencia de palabras.
Para entrenar los modelos de clasificación, autores como [6] recomiendan dividir los datos objeto de estudio, así: 80% para entrenar y 20% para la fase de validación. Sin embargo, [2] sugiere conservar 70% para entrenar y 30% para validar. Màs aún, [7] indicaron que el 90% debía ser para entrenamiento y el 10% para validar. Con relación a la validación de los modelos, ademàs del uso del 10% - 30% de los datos para tal fin, se encuentra otra alternativa, alusiva a la validación cruzada (véase, por ejemplo, [4 y 9])
En la Tabla 4 se presentan los métodos de clasificación empleados por los trabajos previos.

En la Tabla 4 se muestra que los métodos de aprendizaje automático más utilizados para la clasificación de incidentes fueron Naive Bayes y Maquinas de Soporte Vectorial, ambos con un 50% de participación en los estudios de referencia. Seguido, están regresión logística, K vecinos más cercanos y máquinas de aumento de gradiente (GBM), cada uno con uso en el 21% de los estudios. Árboles de clasificación participa en el 14% y otros métodos de menor uso, son random forest, adaboot, redes neuronales, CRF y FastTxt con un 7% cada uno.
3. Métodos
Con el fin de cubrir un amplio espectro de los métodos en mención, el presente estudio toma en consideración representantes de los grupos de alta (SVM), media (regresión logística) y baja participación (árboles de clasificación) en los trabajos previos sobre clasificación de incidentes tecnológicos (véase Tabla 4). Adicionalmente, para complementar la comparativa por llevar a cabo, se incluyen análisis lineal discriminante y random forest, los cuales han resultado útiles en otras experiencias de los autores (ej., precios inmobiliarios). Así, el presente trabajo considera un total de cinco métodos de aprendizaje automático, cuyos desempenos serán comparados en tres tipologias de escenarios: solo atributos estructurados, solo atributos de texto, y ambos tipos de atributos.
A continuación, se resumen los pasos seguidos para preparar y desplegar la comparativa entre los cinco métodos en consideración:
3.1 Reconocimiento del proceso
Esta etapa abarca un primer acercamiento con los analistas y directivos involucrados en el proceso de gestión de incidentes. Además, profundiza en el procedimiento actual de clasificación de incidentes desde la óptica del analista de seguros generales, con lo que también se contemplan posibles criterios que los llevan a tomar determinadas decisiones de clasificación.
3.2 Recolección y preparación de datos
A partir del software utilizado en la gestión de incidentes en la compania aseguradora, se extrae un informe que corresponde a los incidentes relacionados con las fallas en los aplicativos. El rango de observación comprende nueve meses (desde julio de 2019 hasta abril de 2020). Durante este periodo de tiempo, se asignaron 2816 incidentes a los grupos solucionadores "0" y "1", lo que se configura como la variable respuesta.
Adicionalmente, se construye el diccionario de variables que se configuran como relevantes de acuerdo con la literatura y la profundización en el contexto de la compania aseguradora; estas han de ser la base para el diseno de los modelos de clasificación, a través de los cinco métodos de aprendizaje supervisado seleccionados. En la presente fase también se realizan actividades como homologación de datos y creación de variables adicionales, a partir de las existentes. Luego, se procede con la partición de la muestra, conservando el 70% de los datos para entrenamiento y el 30% restante para validación.
3.3 Entrenamiento y validación de los modelos
A través del paquete Caret [15,16], en R, se programan funciones especificas para que permitan entrenar la clasificación de los incidentes de interés, a través de los cinco métodos en comparación (SVM, random forest, regresión logistica, árboles de clasificación y análisis lineal discriminante). Asimismo, se procede con el análisis de parámetros de refinamiento (ej., poda de los árboles de clasificación), hasta dejar a punto los modelos, lo cual es guiado por la observación del desempeno de cada uno en la muestra de entrenamiento y el uso de métricas de la matriz de confusión.
La validación de los modelos se ejecuta considerando principalmente la "exactitud", derivada de los resultados obtenidos para el 30% de las instancias separadas para ello. Dicha métrica es obtenida a partir de los datos de la matriz de confusión, asi: suma de la diagonal (verdaderos positivos y verdaderos negativos), divida entre el total de casos.
La Fig. 1 resume el diseno de los modelos en consideración. Alli se muestran los siete predictores por incluir en el diseno de los modelos, seis de los cuales son de naturaleza estructurada y, el restante ("descripción"), es tipo texto. Estos predictores permiten examinar tres escenarios de entrenamiento/validación (solo variables estructuradas, solo texto, y ambos tipos de variables). [17] explica que para realizar la clasificación a partir de texto se suele comenzar con el análisis textual (o caracterización), proceso en el que el documento se divide en caracteristicas (palabras o frases) y se le aplican una serie de métodos como la normalización y la eliminación de palabras vacias, con el fin de generar el conjunto de caracteristicas.

Fuente: Los autores
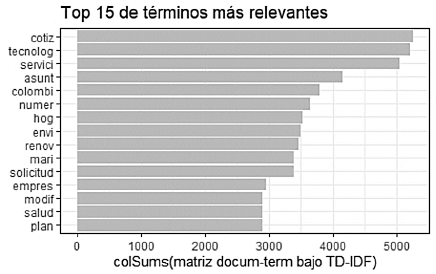
Figura 2 Top 10 de expresiones (previa limpieza de datos) más relevantes de la descripción del incidente
Respecto a la variable de texto, se optó por extraer los vectores de las 50 expresiones más relevantes (suma de TF-IDF) en las descripciones del incidente, previas operaciones de normalización a minúsculas, eliminación de números y caracteres especiales, tokenización, remoción de palabras no semánticas (stopwords), stemming (raiz de las palabras) y construcción de la matriz.
A modo de evidencia, en la Fig. 2 se presenta el diagrama de barras de las 15 expresiones más relevantes extraidas de la descripción del incidente, previa elaboración de la matriz de documentos (filas)-términos (columnas) con TF-IDF. De este modo, cada vector representa una variable predictora por examinar usando TF-IDF.
Con los modelos objeto de estudio, enmarcados en cinco métodos de aprendizaje automático, se busca clasificar el equipo de trabajo más adecuado para dar solución al incidente, el cual presenta categorias "1" (automatización) y "0" (soporte general).
4. Resultados
En la Tabla 5 se presentan los resultados consolidados de la exactitud de los modelos construidos bajo los cinco métodos en competencia, tanto para la muestra de entrenamiento como de validación, considerando los tres escenarios de análisis (atributos estructurados, textos y ambos).
En la Tabla 5 se observa que bajo el escenario 1 (solo variables estructuradas), el método que arroja el modelo con el mejor desempeno en los datos de entrenamiento y validación es random forest, con una clasificación correcta del 67.9% y 70.9% de las instancias, respectivamente.
Asimismo, en el escenario solo con variables de texto, se obtiene lo siguiente: Random forest presenta el mejor desempeno en la muestra de entrenamiento (99.5% de exactitud), lo cual refleja sobreajuste a los datos, dado que en la muestra de validación dicha exactitud se reduce a 88.1%. Sin embargo, este valor aún forma parte de los resultados más favorables en tal conjunto de datos de validación, compartiendo la supremacia con regresión logistica (88.1%) y SVM (88.4%).
Ahora bien, al combinar los predictores en mención (escenario 3, véase Tabla 5), random forest sigue presentando la mayor exactitud en las instancias de entrenamiento (88.7%), pero a costa de sobreajuste que luego deriva en 77.5% de clasificaciones correctas en la muestra de validación. Sin embargo, sorprende que los árboles de clasificación, los cuales no consideran los beneficios del ensamble (como si ocurre en random forest), muestran estabilidad en el desempeno (entrenamiento: 84.9%; validación: 85%). Además, dicho modelo (bajo árboles de clasificación) arroja el mejor desempeno en este último conjunto de datos. Asimismo, el desempeno en ambas muestras por parte de regresión logistica y SVM son cercanos al arrojado por árboles de clasificación (84% y 83.2%, respectivamente).

Otro aspecto por considerar es que los resultados arrojados por la combinación de variables estructuradas y de texto en un mismo modelo, no están mostrando un incremento en la exactitud de los modelos. De hecho, en el escenario 2 (solo datos de texto), ninguno de los métodos proporcionó un modelo que superase el 88.1% que produjo random forest o regresión logística, y menos el 88.4% arrojado por SVM. En otras palabras, la complejidad y el consumo de recursos que implica el hecho de combinar variables estructuradas y de texto, no están siendo justificados por los resultados obtenidos.
Por consiguiente, siendo conscientes de la mejoría que produce el escenario de predictores de texto (véase escenario 2, Tabla 5) y tomando en cuenta la exactitud en la muestra de entrenamiento y en la de validación, cualquiera de los modelos de random forest, SVM o regresión logística resultan útiles para el uso en la organización observada, con tasas de acierto del 88%.
Para examinar las implicaciones prácticas al respecto, se tomó una muestra adicional de 50 incidentes ya cerrados (conociendo el equipo solucionador correcto). Luego, se indagò en la comparila la trazabilidad de cada incidente, con el fin de identificar si este había sido transferido una o más veces a otros equipos antes de ser solucionado por el equipo correcto. Asimismo, se extrajo la fecha de creación y cierre de cada incidente, para calcular los dlas que estuvo en tránsito. Esto posibilitó dar cuenta del promedio de dlas transcurridos desde la primera clasificación que recibió el incidente reportado a la mesa de ayuda.
Con estas estimaciones, se recurrió a una representación del tiempo estimado de resolución de un incidente tlpico desde que este se clasifica la primera vez. Dicho indicador considera (a) la exactitud de la clasificación (humano vs modelo elegido), usando la nueva muestra (50 instancias), y (b) dos tipologias de tiempos de resolución del incidente: cuando este se clasifica correcta o incorrectamente en el primer contacto. Asl, la representación del indicador de interés se plasma en la ec. 1.

Siendo:
t it = tiempo estimado de resolución de un incidente típico desde que este se clasifica la primera vez.
p 1 = probabilidad de clasificar correctamente cuando se reporta el incidente (a la primera ocasión).
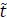 1
= tiempo medio de resolución de un incidente cuando éste es correctamente clasificado al primer contacto con él.
1
= tiempo medio de resolución de un incidente cuando éste es correctamente clasificado al primer contacto con él.
2= tiempo medio de resolución de un incidente cuando éste es clasificado incorrectamente al primer contacto con él (considera el tiempo de tránsito por reclasificaciones hasta que el incidente llega al equipo correcto de trabajo y se le brinda solución).
En la Tabla 6 se plasman los resultados de la ecuación 1 y sus componentes.
Tabla 6 Comparativo humano vs máquina con relación al desempero práctico de la clasificación de incidentes

Fuente: Los autores
La Tabla 6 muestra que al llevar a cabo la clasificación de incidentes mediante alguno de los modelos de aprendizaje automático (Random Forest, SVM o regresión logistica, cada uno con 88% de exactitud, Tabla 5, validación), el ahorro en tiempo es de cerca de 30 horas de consumo/uso de recursos (ej., equipo humano, tecnologia, espacios fisicos) por incidente (1.23 dias; 29.6 horas) en comparación con la tasa de exactitud del humano. Ahora bien, una determinada mesa de ayuda en la organización observada suele recibir en promedio 30 incidentes diarios en época de baja demanda y 200 en temporada de alta demanda. Por tanto, la clasificación mediante alguno de los modelos sugeridos (Random Forest, SVM o regresión logistica) representaria, en cada mesa de ayuda, un ahorro diario de entre 888 horas y 5920 horas de consumo/uso de recursos. De ahi que los 22 puntos porcentuales de más exactitud por parte de la máquina (88%) en comparación con el humano (66%), constituyen una importante implicación práctica para la organización observada.
5. Conclusiones
Este articulo demuestra que la utilización de modelos de aprendizaje automático para la clasificación de incidentes tecnológicos en una comparia aseguradora es una alternativa prometedora, considerando la comprensión de un nuevo dominio y uso, asi como sus implicaciones prácticas.
Con relación al método con mejor exactitud, el estudio encuentra supremacia de Random Forest en el escenario del mero uso de predictores estructurados. Asimismo, aunque dicho método también resulta prometedor en el escenario de predictores tipo texto (0.881), los resultados de los modelos diserados bajo los demás métodos no son notablemente diferentes, oscilando entre 0.85 (árbol de clasificación y 0.884 SVM). Esto da flexibilidad a la elección del método en cuanto a exactitud y, además, posibilita tomar en cuenta otras variables como criterios de elección, entre ellas, eficiencia computacional de las alternativas (ej., tiempo de entrenamiento).
En referencia al escenario de observación, el uso de variables no estructuradas representa una considerable mejoria de la capacidad de predicción de los modelos, pasando Random Forest, en la muestra de validación, de 0.709 en datos estructurados a 0.881 en el escenario de datos de texto. De igual forma ocurre con los demás métodos, siendo superiores los resultados en el escenario de datos de texto en más de 20 puntos porcentuales, en comparación con el de datos estructurados. Asi, las 50 de expresiones más relevantes (bajo suma de TF-IDF) en la descripción narrativa del incidente (ej., "cotiz", "tecnolog", "servici", "asunt"), representan predictores esenciales para mejorar la exactitud de los modelos. Este último hallazgo es consistente con la importancia que [3] le atribuye a la descripción del incidente para favorecer el desempero de los modelos de clasificación.
Al considerar las implicaciones prácticas de la tasa de clasificación correcta humano (66%) vs máquina (88%, Random Forest, SVM o regresión logistica, véase Tabla 5, escenario 2), la máquina representa una mejoria importante desde el punto de vista práctico, posibilitando ahorros anuales de 10656 horas de consumo de recursos humanos, fisicos y tecnológicos en condiciones de temporada baja y de 71040 horas en temporada de alta demanda.
Este articulo constituye un caso de éxito del aprendizaje automático en el sector de seguros. Por consiguiente, sirve de base para la preparación de la organización observada y de otras organizaciones, en cuanto al afrontamiento del paradigma de la industria 4.0, centrado en el uso de tecnologias emergentes (ej., Big Data, inteligencia artificial, robótica) y en su integración con las personas para transformar el entorno de trabajo.
Si bien este estudio examina la mayoria de los datos disponibles sobre el incidente enviado via correo electrónico, como lo es la descripción narrativa, las imágenes de pantallazos de errores alusivos al incidente no fueron consideradas. El procesamiento de dichas imágenes, en futuros trabajos, podria generar nuevo conocimiento al respecto y favorecer el desempero de los modelos aqui entrenados/validados. De igual forma, otros futuros estudios podrian abordar también datos de voz, generados al momento de realizar el reporte del incidente a través de llamada telefónica.

