











 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink1. INTRODUCTION
The human-dog bond has various theories in relation to its origin, the most representative being when humans were hunter-gatherers, due to the ease with which the dogs could have food, participating in activities together with humans, such as hunting and transportation. Which leads to the link being part of the history of both species [1]. The dogs that after the bond were separated from the humans to continue on their own, were called stray dogs. By instinct, these dogs can survive without the human bond, but without some type of education or upbringing that allows them to have good health, it can be harmful to humans, because these dogs are one of the main causes affecting public health [2].
Investigations show that the number of stray dogs is increasing in different locations. Such is the case of the Affinity Foundation [3], which in its last report in 2016, estimated that approximately 138 thousand animals, between dogs and cats, were collected in the streets of Spain. The reason why they were abandoned was 15% due to unnecessary litters, 13% because of behavior problems, 8% due to loss of interest in the animal, and 12% for economic factors. Also, according to the Ecuador Animal Protection Foundation, in 2014 there were 600,000 pets in Quito alone, 20% of which were found abandoned, another 20% were owned, and the remaining 60% lived on the streets. That's why different authors are looking for the reason why the number of stray dogs is increasing, in order to propose solutions that allow to decrease these amounts.
"Stray Animal Mobile App" [4] was among the various solutions that were proposed, which was based on the interaction between owners and people to search for a dog through reports, using a mobile application which provides either a good or bad result after a decent interval of time; this may be very useful to some owners. Furthermore, applications that use external tools to provide information regarding the location of the dog, like "Book Meow" [5], an application that allows us, via the use of GPS, to track the location of the dog, and at the same time look, for places where the dog can be found, were created. This type of GPS is very useful for those owners who can, and wish to, opt for this type of complementary device to their application. In addition, applications such as "A Mobile App Engaging Citizens and Officials in Addressing the Stray Dog Crisis" [6], allows for communication between citizens, responsible officials, and animal control personnel, through reports of the location and agglomeration of street dogs, to have a better mapping and, then, taking the corresponding actions against public health, which at the same time is a way of finding dogs, if the owner gets in contact with these people.
What is remarkable about these investigations is the technological contribution that allows for the identification of a dog in different ways. However, they do not consider aspects such as accessibility and response time in detail, for example, the Stray Animal Mobile App requires the information of the dog for identification, as this information is later reviewed among the thousands of reports, it takes a long time in some cases, while the use of Book Meow, which uses a GPS device, turns out to be very expensive for some, preventing it from being accessible to everyone. For this reason, we propose a mobile application that makes use of a machine learning model with Google Cloud AutoML Vision for the recognition and classification of images of lost dogs, in order to help the public user obtain the most accurate and fast identification possible. In addition, to provide them with better accessibility, in terms of cost and use.
The proposal has been organized by sections. In section 2, the methodology used for the review of the studies related to street dogs is explained. Based on this, section 3 includes the methodology implemented for the development of the proposal, and the description of the phases. Subsequently, in section 4, the application is validated, the results are shown and discussed. Finally, the conclusions are indicated in section 5.
2. RELATED STUDIES
A review of the literature was carried out, applying the "A systematic literature review about software requirements elicitation" [7] methodology, which is composed of 3 phases: planning, development, and results.
In planning the review, the established research questions were the following ones: (1) What are the consequences of the large number of stray dogs on human well-being? (2) What are the main technological and legislative measures to reduce the number of street dogs? and (3) What factors cause the rise in street dogs? Additionally, the keywords, database, and inclusion or exclusion criteria were defined.
After developing the review, we proceeded to choose the studies, thus, the next steps were followed: we searched for studies in different databases, collections of potential studies, the application of exclusion criteria, followed by the selection criteria in the abstract, the introduction, and conclusions; in order to obtain the studies used in the results phase.
A taxonomy was proposed for the analysis of the selected studies, composed of 3 categories (consequences, measures, and factors) related to each research question, according to Table 1.
The category "consequences" shows us those dangers in public health that are caused by street dogs towards people. Among these we find attacks, parasites, and infections due to the closeness between people and dogs. Articles about attacks were found more frequently, so identifying these is useful to the public wellness, including the "Stray Dogs Behavior Detection in Urban Area Video Surveillance Stream"[8], developed by its authors as an intelligent solution which can identify and report street dogs attacks through the automatic detection of public surveillance videos; in this way, it can extract basic characteristics of sequences within the videos to classify it according to the type of action, both for dogs or people, to finally interpret it with a behavior classifier.
These consequences are due to various "factors" that are largely, as the main cause, abandonment, irresponsible tendency, and the availability of food or shelter. Therefore, Fatjo et al. in "Epidemiology of Dog and Cat Abandonment in Spain" concluded that the reasons why owners tend to abandon their dogs is due to loss of work, lack of time or space, animal behavior, unexpected litters, financial issues, hospital admissions, or death.

Based on the factors and consequences, the "measures" are the way in which these problems can be counteracted, so research that provides any software is very supportive. Such is the case of Dog Tracker, in "A Mobile App Engaging Citizens and Officials in Addressing the Stray Dog Crisis" [6], it allows citizens and animal control officials to be connected by an application that records information on the sighting of a stray dog, based on its behavior. With "Book Meow: A Mobile Application for Finding and Tracking Pets" [5], a mobile application to locate and track your pets by GPS, and "Where is my puppy? Retrieving lost dogs by facial features" [10], an easy recognition software through convolutional neural networks to compare the effectiveness of techniques used for humans in animals.
3. METHODOLOGY
This section presents the research methodology applied in the study, which is composed of 4 phases (see Figure 1). In phase 1 the following research questions were asked:
RQ1: Is it possible to build a mobile application applying image recognition to identify or report stray dogs efficiently?
RQ2: Is it possible to have better accessibility with a mobile application for image recognition to identify street dogs?

In phase 2, the model that is generated will carry out the labeling of the breed of the dogs according to the photo obtained. This phase consists of 3 parts: (1) Collection of photos for training (Database), (2) Training of the model, and (3) export of the model by generating a file (.tflite).
Thus, in phase 3, the mobile application is developed, based on a proposed architecture, whose input is the file of the trained model. The functionalities that the application has are: loss module and identification module.
Finally, in phase 4, two case studies will be carried out to corroborate the validity of the proposal. The first was done with the usual search through web portals for lost dogs, and, the second, by using our mobile application.
Phase 2: Model
The model phase begins with the generation of the dataset to enter the training, using Google Cloud AutoML Vision, a software that makes use of search technology with neural architecture and transfer learning, facilitates the creation of custom vision models for image recognition use cases, instead of a custom handcrafted CNN architecture [29]. AutoML Vision combines transfer learning with neural architecture search (NAS) to achieve model optimization and automation [30]. After training, the model was exported in an accessible format for integration in the next phase. Figure 2 shows the entire process carried out to obtain the model file in .tflite format.

Dataset generation
Images of dogs from different platforms were collected, starting with the Kaggle platform, where two datasets, with a total of 1600 images, were found, when conducting a review, that the photos were not very useful for our model, and then, we proceeded to search in Google Images with the name of the breed where data was missing. From that search, 800 images were obtained. However, of all that was found, only the amounts presented in Table 2 were used. The 1000 images to be used were divided into sets by breeds. A total of 10 groups (breeds of dogs) were obtained for image labeling: Pug, Doberman, Beagle, Toy terrier, Siberian husky, Cardigan, Shih Tzu, Redbone, Gordon setter and Pembroke.

Training with. Google Cloud AutoML Vision
It began with the import of the groups of images to the Google Cloud AutoML Vision, reviewing the labels of the images, and correcting some of them. Then, the model was trained with the configuration requested by the software: type of model to be carried out, type of model optimization, and budget per node processing hour. Our model was made with the Edge type, which is the one available for subsequent export to Android, the best compensation optimization was selected, and it was performed with training of four nodes per hour. At the end of the training, a specification of three nodes was implemented in order to obtain a better prediction for the model.
Exporting the model
For the export of the model, Tensor Flow Lite was used, which is a tool that is optimized for cell phones and ARM devices, then the only the option to export in TF Lite package was selected and a destination location in Google Cloud Storage was also chosen from this export, to finally get a package containing a. tflite file, a dictionary file, and metadata file.
Phase 3: Proposed Mobile Application
The development of the mobile application was carried out using the PDSM development methodology proposed by the authors Maria Florencia et al. [31]. The authors decided to take the best concepts from the RUP methodology and the SCRUM agile methodology to define a new process in software development. Besides the used software methodology, for our requirements to capture activity, the guidelines indicated in the research "Qualities that the activities of the elicitation process must meet to obtain a good requirement" [32] were followed.
The implemented proposal is an Android application developed with the Java programming language, various free libraries were used for the applications functionalities, such as Tensor Flow Lite, used for the integration of the recognition model. In addition, this proposal is made up of two modules: (1) the loss module, which is where the dog loss reports will be recorded and displayed, and (2) the identification module, which will search for matches between the lost dogs with a photo taken of a stray dog. Figure 3 shows the architecture of the proposal.

Figure 4 briefly explains the flow of the mobile application operation. The flow begins by sending of the most current photo of the lost dog, through the mobile application of the owner of the dog, at the time that the loss is registered, then, the model places a label on the photo that is saved as additional data. After a dog is lost, it becomes one of the many street dogs that exists, therefore, if a person finds it, they only have to send a photo of the street dog through their mobile application, this photo will be sent to the recognition model that will classify it with a label. Once this is done, the database will perform a search in real time, it will match the tag with respect to the tags of the lost dogs, to finally show all the dogs it finds.

Phase 4: Validation
The validation is carried out with two case studies, the first making use of the usual search through web platforms for lost dogs, and, the second, using our proposal. Each case study is made up of 3 dog owners, in these case studies two activities were carried out: (1) report of the loss of their dog (each owner had an attempt with a maximum time of five minutes) and, (2) identifying a dog through a photo (each owner had 3 attempts with a maximum time of five minutes).
During the second activity of the case studies, each identification attempt was made in a different way than the previous one. For the case study 1, in each of the three attempts they were told to look for different dogs, and therefore, different photos. In case 2, each attempt was differentiated by the environment in which the owner had to obtain a photo of his dog. These scenarios are presented in Table 3.

4. RESULTS AND DISCUSSION
In each of the case studies, four main indicators were taken into account, which are: user errors, failed attempts, whether the owner managed to identify at least one dog, and the total time of the test. It is important to note that the total time of the test refers to the sum of the times invested in activities 1 and 2, as defined in the validation process.
It should be noted that it was considered a user error every time the owner pressed an option that diverted him from the function he had to perform, this, in order to see the levels of usability or ease of use of the web platforms and the application proposal. The number of unsuccessful attempts was taken as the total number of attempts given during the identification activity, where the owner could not find the dog. Then, if this amount became equal to three, the identification of a dog is considered a "No" at least once, otherwise, it is considered as a "Yes".
Case of study 1
From the results obtained in this case study, it can be seen that owner 1 is the only one who managed to identify a dog on the assigned platform, he is also the one who obtained the least user failures, since his portal was understandable. In contrast, owner 3, who also obtained a web portal, but had all his information out of order. Facebook was the simplest platfrom during the report, but less accessible in identification since it presents a lot of information on mixed dogs and cats (see Table 4).

Case of study 2
In this case study, using the tool proposed in this article, is shown in Figures 5 and 6, with evidence of when there are no coincidences with the photo sent to search, and a sample of when the search was successful.
In Figure 5 (a), the photo captured by attempt 1 of owner 1, where he captured the image of his dog in a dark place, can be seen; and in Figure 5 (b), the wrong result when he did not find matching results, because of the model when obtaining the image with a little view of the dog's factions, chose at random and found no lost dogs with that label.

In Figure 6 (a), you can see the photo of owner 3, which he obtained in his third attempt, in which he captured his dog with another dog of a different breed and size. Despite having two dogs of different breeds, the application focused on one and looked for the matching dogs to it, and in Figure 6 (b), you can see the result, in which it shows the searched dog as a match.

The results from the three attempts of the owners were different, the owner obtained only one failure when identifying his dog in his attempt 1, where he performed it in the dark environment, owner 2 only obtained success in his second attempt, in which he tested in the bright environment, and owner 3 managed to identify his dog in three attempts, this is most likely due to the high resolution of his mobile camera. Given the obtained results, the camera resolution of the owners mobiles was considered important data to be analyzed (see Table 5).

DISCUSSION
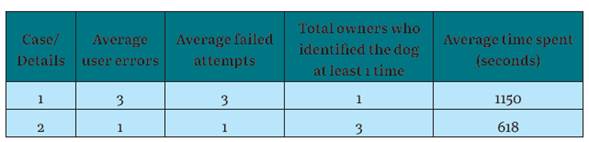
The results of both study cases are analyzed, the summary of the results are presented in Table 6, where the average of user errors, the average of failed attempts, and the average of time invested in the identification are shown, as is the total number of owners who managed to identify their lost dogs.
RQ1: Is it possible to build a mobile application applying image recognition to identify or report stray dogs efficiently?
Regarding the number of erroneous attempts made by the owner, almost three times many erroneous attempts were obtained in case study 1, compared to the other case study 2. This is due to the platforms carrying out a massive sample of all reports, which makes identification very difficult (see Table 6). Therefore, only 1 of the owners could identify a dog during the first case, while in the second, all could identify a dog at least once.
Consequently, the research question RQ1 can be answered: "Yes, it is possible to build a mobile application applying image recognition to identify or report stray dogs efficiently, given that the use of the machine learning model for labeling the breeds of dogs, was very useful at the time of identification, since it significantly reduces the number of lost dogs. The results showed that the average time and failed attempts using our proposal is way more efficient compared to the traditional web platforms that are usually used".
RQ2: Is it possible to have better accessibility with a mobile application for image recognition to identify street dogs?
As can be seen in Table 6, in the average number of user errors, the case study 1 was higher than case study 2, where the mobile application was used, because web platforms used contained mixed information, making the owner bored during the research. With this, we demonstrate that our application has a higher level of usability.
According to the times used during the tests, it can be seen that the time used in case study 1 (1150 s) is almost twice the time used with the mobile application (618 s). Consequently, the RQ2 research question can be answered: "Yes, it is possible to have better accessibility with a mobile application for image recognition to identify street dogs, since the use of a mobile application has a higher degree of usability compared to applications web, and this also influences time".
Finally, it is important to highlight that in the image recognition, it was observed that "lighting is an important factor for image recognition, as is the "camera resolution" that the mobile phone has. Given that owner 3 had a high-resolution camera he was successful in all the indicated scenarios. While owner 1, who had a camera with regular resolution, the lighting of the environment acted as an important factor, because in a dark environment the identification attempt failed.
5. CONCLUSIONS
In this research, a mobile application was developed applying machine learning for recognition and classification of images of stray dogs, in order to optimize their search, and make it accessible to all users.
To carry out the research, each phase of the proposed methodology was applied: posing the research questions, generation of the model, development of the mobile application, and finally the validation of the proposal.
Two research questions were proposed: (RQi) is it possible to build a mobile application applying image recognition to identify or report stray dogs efficiently? And (RQ2) is it possible to have better accessibility with a mobile application for image recognition to identify street dogs?
In the generation of the model, the dataset was collected, then the model was trained, and the results generated were exported using AutoML Vision. Sequently, the application was developed, using mainly Google services, both for saving data and for the consumption of the model. Afterward, the proposal was validated dividing it into two case studies, where the first case used different web platforms and in the second case our proposal was used.
From the results of the validation, the following statements were obtained: (i) the use of the mobile application achieved better results, since the average number of user errors and failed attempts were one third of those obtained with traditional web platforms. This is due to the use of image recognition with the machine learning model. For instance, this model efficiently reduced the information of lost dogs to review and ensured that owners can identify their dogs. (ii) The average times showed that the use of our application significantly reduces the time used to search a dog, since the average time with web platforms was the double amount. Finally, (iii) better accessibility in terms of the scope that anyone needs to use the mobile application to identify their dog or report lost dogs. Therefore, the two research questions posed were answered with our investigation.

