











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
1. INTRODUCCIÓN
Los entornos educativos virtuales actuales, carecen de herramientas que permitan incluir la experiencia emocional de los aprendices con el fin de identificar aquellos casos en los cuales la emocionalidad y falta de atención afectan el proceso de aprendizaje. Algunos estudios [1]-[3] han constatado que la disposición emocional de los alumnos facilita el aprendizaje. En [4] se analiza la influencia de la atención en el desempeño escolar, encontrando que las dificultades en este componente generan deficiencias en el procesamiento de la información, lo cual influye negativamente en la adquisición de nuevos aprendizajes y, por lo tanto, en el rendimiento académico. Adicionalmente, en [5] se encontró que los estudiantes con deficiencia de atención presentan dificultad en la adquisición del código lector, así como en el componente de aprendizaje de lógica matemática [6].
El uso de aplicaciones con detección de rostros en tiempo real para el reconocimiento de emociones ha ganado un papel importante en estudios de visión e inteligencia artificial [7].
Cada día surgen nuevos usos para este tipo de técnicas, debido al acceso que tienen las personas a dispositivos que están conectados a internet y tienen cámara que permite la recolección e identificación de los rostros humanos. El desarrollo de métodos para la detección automática de emociones ha estado fuertemente ligado al conocimiento que se tiene sobre los cambios que estas generan en la fisiología de las personas [8], [9].
La unión de estas dos tendencias lleva a incorporar la detección de rostros en tiempo real en ambientes educativos mediados por las tecnologías de la información y la comunicación (TIC), analizando el nivel de compromiso de los estudiantes a través de sus expresiones faciales [10]-[13], donde se hace evidente la necesidad de los docentes de tener un encuentro cercano con sus estudiantes al poder detectar en ellos su atención o falta de atención [13], así como la emoción que el estudiante puede presentar en un momento determinado de la clase sincrónica, esto con el objetivo de obtener un aprendizaje significativo que lleve al estudiante a la adquisición y comprensión de nuevos conocimientos.
A pesar de que algunos trabajos en el estado del arte consideran la detección de emociones en ambientes educativos a través de modelos en los cuales se encasillan las emociones experimentadas por los aprendices [14], es importante considerar su medición teniendo en cuenta factores como la positividad o negatividad de estas como su nivel de atención, ya que esto determina el estímulo recibido por la herramienta de enseñanza para el aprendizaje [15], [16].
Para el desarrollo de una aplicación web que permita el monitoreo constante de los estudiantes, se seleccionó el lenguaje de programación de Python por ser un lenguaje de alto nivel, adecuado para código científico y de ingeniería, que es rápido y flexible [17].
Adicionalmente, Python tiene gran cantidad de librerías que hacen de este un lenguaje versátil para todo tipo de proyectos como la integración de modelos de inteligencia artificial con aprendizaje profundo. Cuenta con facilidades para la programación orientada a objetos, imperativa y funcional, por lo que se considera un lenguaje multiparadigmas [18].
En este artículo, se describe el desarrollo de una aplicación web, la cual permite el monitoreo de los estudiantes en un entorno virtual. Entre las librerías utilizadas se encuentra Pandas para análisis de datos; OpenCV, para procesamiento de imágenes; Torch, para generar algoritmos de aprendizaje de máquina e inteligencia artificial; Flask, para el desarrollo web [18], [19], entre otras. La aplicación propuesta se divide en dos módulos de software. El primero detecta los rostros de los sujetos y, a partir de sus microexpresiones, realiza el reconocimiento de tres emociones inducidas por la actividad que se está realizando en el ambiente virtual (felicidad, neutro y enojo). El segundo módulo detecta el estado de atención que presenta el sujeto (atención, no atención y ausencia de rostro). Este reconocimiento se realiza en tiempo real. Para esto, se utilizó el paradigma de programación Modelo Vista Controlador (MVC), con el objetivo de separar el modelo de datos de la vista que presenta la información al usuario final y el controlador que gestiona las peticiones de la aplicación y se encarga de la comunicación.
Este documento está organizado de la siguiente manera: primero se presenta la metodología, que consta de la selección de algoritmos para la detección de emociones y atención, seguido del proceso de adquisición de la base de datos para el entrenamiento de los modelos y, finalmente, el desarrollo del aplicativo web. En la sección 3 se presentan los resultados y la discusión, mostrando cómo los algoritmos seleccionados para la detección de emociones y rostros es promisorio para el uso en ambientes virtuales de aprendizaje. Por último, se encuentran las conclusiones.
2. METODOLOGÍA
En este capítulo explicamos el desarrollo de los módulos que componen la plataforma web y se presentan los resultados obtenidos.
La aplicación web propuesta consta de dos módulos luego del reconocimiento del rostro en la cámara. El primero es el reconocimiento de emociones, el cual tiene tres clases: felicidad, neutral y enojo (modelo 1). El segundo permite identificar si una persona está prestando atención o no a la pantalla del computador, para esto se cuenta con dos clases: atención y no atención (modelo 2). Para el desarrollo del aplicativo se siguieron las fases de selección de la metodología, adquisición de las bases de datos con el entrenamiento y el desarrollo del aplicativo web que integra los modelos propuestos. A continuación, se detalla cada uno de estos procesos:
2.1 Adquisición de la base de datos
Se adquirieron dos bases de datos para realizar el entrenamiento de los modelos. Estos datos fueron obtenidos con la ayuda de los miembros del Semillero de Inteligencia Artificial del Instituto Tecnológico Metropolitano de Medellín, Colombia (ITM).
Base de datos 1: se registró en video el comportamiento de 9 estudiantes mientras observaban videos diseñados para generar tres emociones: felicidad, neutral o enojo. De los registros de video, tomado a 30 fotogramas por segundo (fps), se almacenaron cada uno de los frames en formato de imagen. Como resultado, se obtuvieron 9873 imágenes repartidas en las tres emociones, para la categoría Neutral 2425, para Felicidad 3907 y para Enojo 3539.
Base de datos 2: se registró en video el comportamiento de 15 estudiantes mientras atendían conferencias virtuales. Cada estudiante se instruyó para atender dos conferencias, una de su interés y otra con un tema de libre elección. Los participantes fueron instruidos para atender la primera videoconferencia y desatender la segunda, con el fin de tener datos suficientes de ambas clases. Como resultado se almacenaron secuencias de video de 1 segundo tomadas a 30 fps, con una distribución entre clase atención de 1228 muestras y clase no atención de 438 muestras.
2.2 Metodologías para el reconocimiento de rostros
Para la selección de las metodologías que permiten el reconocimiento de rostros, se estudiaron los métodos de visión artificial propuestas en [19]-[25] analizando sus pros y sus contras. Se concluyó que las metodologías presentadas en [23], [24] se adaptan mejor al problema que se quiere resolver y presentan, además, un bajo costo computacional. Consecuentemente, se implementaron los siguientes modelos:
Modelo 1: este modelo se basa en el algoritmo Haar-cascade, propuesto por [25] y que fue diseñado para reconocer objetos en una imagen. En este trabajo se utilizó la implementación de Haar-cascade de la librería OpenCV para reconocer los rostros en una escena. Inicialmente, el algoritmo se alimenta de imágenes con rostros (muestras positivas) e imágenes sin rostros (muestras negativas) para entrenar el clasificador. El algoritmo convierte la imagen a escala de grises, luego obtiene características Haar (bordes, líneas y rectángulos). Estas características son utilizadas como kernels para realizar la convolución con las imágenes. Para cada característica encuentra el mejor umbral que clasifica las imágenes positivas de las negativas. Luego se seleccionan las características que presentan la menor tasa de error. Al principio de la clasificación, cada característica presenta el mismo peso; luego de cada clasificación, los pesos de las imágenes mal clasificadas son incrementados, se repite el proceso y se calculan las tasas de error y los nuevos pesos.
El proceso se continúa hasta que la precisión requerida o la tasa de error calculada sean adecuadas o el número de características requeridas sean encontradas. Una vez reconocido el rostro con Haar-cascade, se procede a hacer el reconocimiento de la emoción utilizando el algoritmo Histograma de Patrones Binarios Locales (LPBH, por sus siglas en inglés).
El algoritmo LPBH es un operador de texturas, el cual etiqueta los pixeles de una imagen umbralizando el vecindario de cada pixel y considerando el resultado como un número binario. Este proceso se explica en la Figura 1. La clasificación se realiza mediante el cálculo de la similitud entre los histogramas [26].

Modelo 2: el segundo modelo toma como entradas secuencias de video de un segundo tomadas a 30 fps. Cada uno de los cuadros de esta secuencia se pasa por el modelo red neuronal convolucional multitarea (MTCNN, por sus siglas en inglés) [27], [28] del que se obtienen 5 puntos fiduciales del rostro de la persona: el centro de los ojos, la nariz y las comisuras de la boca. Adicionalmente, se obtienen los puntos superior izquierdo e inferior derecho del cuadro que enmarca el rostro (bounding box). Después, los puntos fiduciales se normalizan con respecto al bounding box, generando una secuencia para cada uno de los puntos fiduciales. Esta secuencia multivariada se utiliza para entrenar una red recurrente con arquitectura Long Short Term Memory (LSTM) con dimensión oculta h = 100, que clasifica entre las secuencias donde los sujetos prestan atención y las secuencias en las que no se presta atención. El procedimiento se puede ver en la Figura 2.

2.3 Entrenamiento y prueba de los modelos
Los modelos se entrenaron dividiendo los datos en 80 % para entrenamiento y 20 % para prueba. De los datos de entrenamiento, se deja un 20 % adicional para validación con el fin de sintonizar los parámetros de los modelos. En el modelo 2, se utilizó Adam como algoritmo de optimización con una tasa de aprendizaje de 0.01. El tamaño del batch se ajustó en 16, se utilizó entropía cruzada como función de costo, y se entrenó durante 100 épocas. Los porcentajes de tasa de acierto de clasificación para cada uno de los modelos se muestran en la Tabla 1.

Finalmente, los modelos se probaron en tiempo real por parte de los miembros del semillero mientras realizaban las tareas que generaran emociones o requirieran atención. Si el modelo fallaba, se adquirían más imágenes de más participantes y se reentrenaba repitiendo nuevamente el proceso (ver Figura 3).

2.4 Planificación y desarrollo del aplicativo web
Para el desarrollo y la implementación de la aplicación web, encargada de la integración de los dos modelos, se siguió con la arquitectura de programación MVC [29], que permite desarrollar aplicativos webs de forma más organizada y sencilla por capas. Además, se trabajó con Flask en un proyecto, utilizando dicha arquitectura y otro que no, encontrando que si se trabaja con base en el MVC se pueden obtener mayores velocidades en la carga de información sin afectar el tamaño o peso total de los archivos utilizados para la aplicación.
En el MVC, la capa vista almacena las diferentes vistas de la aplicación con las que interactúa el usuario, que son por lo general archivos HTML con estéticas y funcionalidades agregadas gracias a CSS y Javascript, respectivamente. La capa modelo contiene la información y códigos necesarios para el funcionamiento de los 2 modelos de visión artificial, y finalmente el controlador, aquel que regula la relación entre los modelos y las vistas será llevado por Flask (ver Figura 4), sirviendo como intermediario con rutas que adquieren la información mediante protocolos HTTP (Hypertext Transfer Protocol) y métodos GET.
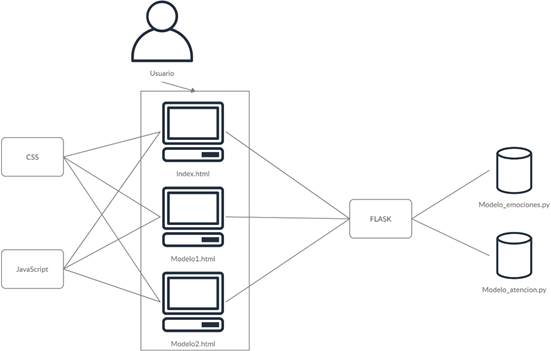
Adicionalmente, se seleccionó Flask, por ser un microframework que cuenta con una estructura sencilla, su curva de aprendizaje es baja y no utiliza estructuras complejas para el manejo de los objetos. Flask tiene ventajas frente a otros frameworks como Django, debido a su optimización en las tareas sencillas, siendo una buena alternativa para este tipo de proyectos.
Para el proyecto se realizaron 3 vistas:
-Index.html, la cual muestra la página principal del proyecto con información acerca del mismo y las opciones para acceder a las otras 2 vistas.
-Modelo1.html, muestra información sobre el proyecto de detección de emociones y al final de esta se mostrará en tiempo real el frame capturado por la cámara y su respectiva clasificación de emoción.
-Modelo2.html, muestra la información sobre el proyecto de detección de atención y al final de esta se mostrará en tiempo real el frame capturado por la cámara y su respectiva clasificación de atención.
El entorno de desarrollo integrado (IDE, por sus siglas en inglés) utilizado para la programación fue Visual Studio Code debido a su poco peso y fácil instalación de plug-in o lenguajes de programación dentro del mismo, además, cuenta con un panel de control integrado que facilita el trabajo al momento de ejecutar la aplicación. Flask, internamente, utiliza el motor de plantillas Jinja y el kit de herramientas Werkzeug WSGI [30]. Es necesario almacenar los archivos HTML en una carpeta llamada templates, la cual posteriormente, sirve para que Flask pueda renderizar los archivos para su visualización dentro del buscador web al momento de ser llamados por alguna de las rutas.
Continuando con las vistas Flask, dentro de su estructura establece que archivos de CSS, JavaScript e imágenes que dan estilo a los archivos de HTML, se deben almacenar dentro de una carpeta llamada ‘static’.
Una vez realizadas las vistas, sus estilos y funcionalidades se prosiguió a hacer la capa de controlador y el enrutamiento del servidor a las diferentes instancias de la aplicación. Se creó la carpeta llamada ‘Controlador’, donde se almacena el archivo camera.py encargado de prender la cámara del computador del usuario y extraer información frame a frame. También están los archivos Load_data_Atencion.py y Load_data_emociones.py encargados de obtener los frames de camera.py, compararlos con el entrenamiento de los modelos y procesarlos para devolver una predicción pertinente al modelo que se esté utilizando.
Seguido de lo anterior, se creó una carpeta llamada Modelo que contenía en su interior 2 carpetas que almacenan el modelo de detección de emociones y el modelo de detección de atención, a su vez cada una contiene archivos necesarios para su funcionamiento como XML, imágenes de comparación, código de arquitectura de la red neuronal convolucional, entre otros.
Para el enrutamiento se creó el archivo llamado servidor.py, el cual debe ir afuera de las carpetas del MVC y será el encargado de obtener los requerimientos del usuario y enrutar ese requerimiento a través de las diferentes instancias de la aplicación para devolverle una vista con dicho requerimiento.
En las Figuras 5 y 6 se presentan los diagramas de secuencia diseñados para cada uno de los modelos, detección de emociones y detección de atención, presentando la interacción entre los frames desde que el usuario entra a la vista del modelo hasta mostrarle el resultado dentro de esa misma vista.


3. RESULTADOS Y DISCUSIÓN
En esta sección se presenta el funcionamiento de la aplicación web y la interacción con los dos modelos propuestos.
En la aplicación web se implementaron dos modelos de visión artificial, específicamente de reconocimiento de rostros en tipo real para el monitoreo de estudiantes. El primer modelo clasifica la emoción (neutro, enojo y felicidad) que tiene el estudiante, el segundo identifica si el estudiante está o no está prestando atención, asimismo si el estudiante abandonó o está presente.
La aplicación se desarrolló en Flask con la arquitectura MVC. Al ingresar a la aplicación el usuario entra a la vista index.html, donde se encuentra una pantalla de inicio (Figura 7a), un apartado mostrando los desarrolladores del aplicativo que se realizó en Javascript con la librería Swiper (Figura 7b), permitiendo mejorar el diseño y aplicar dinamismo a las imágenes, un apartado con 2 botones (Figura 7c) para que el usuario vaya al modelo que desee y, finalmente, un apartado de características descritas con texto y algunos iconos (Figura 7d).

Fuente: elaboración propia.
Figura 7 Vistas de la aplicación web (a)Inicio, (b) Desarrolladores, (c) Modelos y (d) Características
Al ejecutar la aplicación y abrirla en el navegador de Google Chrome no se observaron problemas de visualización, ni de velocidad de ejecución al navegar por los diferentes apartados de esta pestaña. Se realizaron 4 pruebas tomando el tiempo de carga para la visualización de la aplicación y se encontró un promedio de 9.47 segundos. Tampoco presentó problemas de enrutamiento pudiendo abrir alguna otra pestaña de los modelos como si fueran la pestaña principal.
3.1 Modelo 1: Detección de emociones
Para la pestaña del modelo de emociones, Modelo1.html, se observa un apartado de bienvenida (Figura 8a), un apartado de galería con algunas imágenes de ejemplo utilizadas para el entrenamiento del modelo (Figura 8b) y finalmente un apartado con un recuadro que muestra la captura que hace la cámara en tiempo real y la identificación de emociones.

Fuente: elaboración propia.
Figura 8 Vista del Modelo 1: detección de emociones de los estudiantes (a) Bienvenida, (b) Imágenes
Al momento de acceder a esta pestaña desde la página principal anteriormente vista, se observó la rápida carga de la información visual (imágenes) y de texto. Sin embargo, en el apartado de la pestaña donde se muestra en tiempo real la captura de la cámara y su clasificación de emociones, se nota un pequeño retraso de 1 a 3 segundos para que se encienda la cámara y empiece a procesar los primeros frames. Se evidencia el buen funcionamiento del modelo, siendo este capaz de reconocer las expresiones faciales neutral, feliz y enojado para las que fue inicialmente programado; sin embargo, al ser un modelo con implementación simple, suele tener algunos problemas en entornos de iluminación deficiente. El enrutamiento desde la página principal hacia la página del modelo de emociones se realizó de manera satisfactoria sin ningún fallo o código de HTTP que pudiera indicar algún problema. En la Figura 9a se presenta la emoción neutral, en la Figura 9b la emoción de felicidad y finalmente en la Figura 9c la emoción de enojo.

3.2 Modelo 2: Detección de atención
Igualmente, en la pestaña del modelo de atención, Modelo2.html, se observa la página de bienvenida, como se muestra en la Figura 10.

Asimismo, como el modelo 1, el funcionamiento del modelo 2 presenta buenos resultados de clasificación (como se presentó en la Tabla 1). En la Figura 11 se presenta el funcionamiento del modelo para cada una de las etiquetas utilizadas, en la Figura 11a, el estado de atención, en la Figura 11b el estado de no atención y finalmente en la Figura 11c el estado cuando No está presente.

Fuente: elaboración propia
Figura 11 Funcionamiento del Modelo 2: detección de atención de los estudiantes (a) Atención, (b) No atención y (c) No presente
Esta aplicación web, que integra los dos modelos, permite su utilización en ambientes virtuales para hacer seguimiento a los estudiantes en sus niveles de atención y la emoción que les causa la presentación de algunos materiales de aprendizaje.
4. CONCLUSIONES
En este trabajo se presenta el desarrollo de una aplicación web que integra dos modelos de reconocimiento de rostros; el primero de ellos para la detección de emociones expresadas ante la cámara; el otro, para la detección de atención a la pantalla del computador aplicables a entornos virtuales de aprendizaje. Para la composición de los modelos se utilizó el framework Flask y se puede concluir que su uso permite la integración de algoritmos de inteligencia artificial ofreciendo gran rendimiento. Además, Flask permite diseñar una interfaz agradable con características de usabilidad que integra los algoritmos y así el usuario final no tiene que estar en contacto ni tener conocimientos de Python, sino que consume la aplicación final. Por otro lado, se evidenciaron las ventajas de Flask al manejar el MVC, lo que permite un desarrollo más ágil y la reutilización de código. En este trabajo se separaron las capas así: en el Modelo se desarrollaron los algoritmos de detección de rostros, el controlador se encargó de la comunicación entre el modelo y la vista y en la capa de vista se desarrolló la interfaz o el frontend de la aplicación. Cuando se realizaban cambios en el modelo, por ejemplo, la actualización de los algoritmos de reconocimiento de rostros, la vista no se modificaba, lo que permitió que varios desarrolladores trabajaran en el mismo proyecto diferente capa, sin afectar el trabajo del otro.
Como trabajo futuro se plantea el uso de la aplicación web en un ambiente virtual de aprendizaje real, para ayudar al profesor a tomar acciones que mejoren la experiencia y el proceso de enseñanza-aprendizaje.

