











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
PermalinkIntroducción
Los estudiantes de inglés como L2 enfrentan a menudo el problema de que en esta lengua como en otras, un morfema derivativo acepta diferentes significados. Por ejemplo, el sufijo -er produce agentes como en teach -> teacher, pero también genera una forma comparativa como en big-> bigger. Asimismo, los estudiantes deben distinguir que un mismo significado puede lograrse con varios morfemas; por ejemplo, el valor agentivo puede construirse con el sufijo -er (worker) o el sufijo -ist (pianist).
Existe una gran variedad de sufijos que pueden añadirse a bases verbales para formar sustantivos deverbales en inglés, pero algunos cumplen funciones gramaticales adicionales. Por ejemplo, -ment tiene la función gramatical primordial de formar nombres a partir de verbos (agree (v) -> agreement (n)), mientras el sufijo -y muestra una diversidad de funciones: puede formar adjetivos a partir de nombres (cloud (n) -> cloudy (adj)), nombres a partir de adjetivos (difficult (adj) -> difficulty (n)), nombres a partir de nombres (burglar (n) -> burglary (n)) y nombres a partir de verbos (deliver (v) -> delivery (n)), entre otros.
La pluralidad de significados de un solo sufijo se ha abordado anteriormente por otros investigadores, quienes sugieren que la función principal del morfema es la primera en adquirirse. Sin embargo, un aspecto de naturaleza empírica que se ha dejado de lado es la coincidencia en el significado de varios sufijos. Por ello, en este trabajo tratamos este último problema estudiando sustantivos deverbales con valor de resultado, mediante el conocimiento distribucional de cuatro sufijos nominalizadores: -ation, -ment, -al e -y.
En este artículo presentamos los resultados de una muestra de errores en una tarea de completar oraciones que resolvieron 130 universitarios mexicanos estudiantes de inglés como L2 que se ubican en tres distintos niveles de proficiencia de acuerdo con el Marco Común Europeo de Referencia para las Lenguas (MCER). El objetivo de este análisis es identificar diferencias porcentuales y tipológicas de errores entre participantes mexicanos con diferente proficiencia en inglés. El trabajo se organiza de la siguiente manera: primero tratamos algunas nociones teóricas en cuanto a los niveles de dificultad de los morfemas, los aspectos del conocimiento derivacional y la categorización de errores. En la sección de metodología mostramos el procedimiento para la selección de los sufijos experimentales y las palabras meta, el diseño de la prueba experimental y la descripción de los participantes y el corpus que se utilizó para el análisis de errores. Posteriormente, se presenta la sección de resultados y finalmente, la discusión y conclusiones.
1. Consideraciones teóricas para la elección y el análisis de los sufijos experimentales
1.1 El nivel de dificultad de los sufijos
Debido a que una de nuestras variables de estudio es el nivel de dificultad de los sufijos, retomamos el trabajo de Bauer y Nation (1993), quienes proponen un conjunto graduado de siete niveles de afijos que consideran útil para la enseñanza de inglés como L2. Dicha propuesta está basada en la frecuencia, productividad, regularidad y predictibilidad de los afijos flexivos y derivativos más útiles en inglés. Los autores definen frecuencia como el número de palabras en las que ocurre un afijo y productividad como la probabilidad de que el afijo sea usado para formar nuevas palabras. La regularidad se refiere al hecho de que la base no sufra modificaciones ortográficas o fonológicas cuando se le añade un afijo y que el afijo no tenga alomorfos ni múltiples funciones gramaticales. Por último, la predictibilidad es el conocimiento del significado del afijo aun cuando esté descontextualizado (ejemplo: el sufijo -ed solamente marca la forma regular del pasado). Los autores clasifican los afijos de acuerdo con estas características y sugieren que los más frecuentes, productivos, regulares y predecibles son los primeros en adquirirse1.
1.2 Aspectos del conocimiento derivacional
De acuerdo con Tyler y Nagy (1989), se pueden distinguir diferentes aspectos del conocimiento de la morfología derivativa. El primero de ellos es el conocimiento relacional o semántico, que se refiere al conocimiento o percepción de que dos palabras están relacionadas como argue-argument en oposición a off-offer. La relación semántica se reconoce como un prerrequisito para pensar que dos palabras guardan una relación de derivación. Al segundo aspecto se le conoce como conocimiento sintáctico y consiste en saber que los sufijos derivativos marcan la categoría sintáctica de las palabras en inglés (por ejemplo el sufijo -ize genera verbos mientras el sufijo -(a)tion forma sustantivos). Se piensa que el sufijo derivativo provee información confiable acerca de la categoría sintáctica de la palabra aun cuando no se conozca el significado de la base, dejándonos saber que ambiguity es un sustantivo y ambiguous es un adjetivo, incluso sin saber el significado de ambigu-. Por último está el conocimiento distribucional, que es el conocimiento de las restricciones en la concatenación entre bases y afijos. Por ejemplo, en el caso de los nominalizadores, el sufijo -ness se añade a adjetivos y a sustantivos pero no a verbos (quietness, childness versus *playness). Tyler y Nagy (1989) afirman que este es el último aspecto en la adquisición de la morfología derivativa del inglés como L1.
1.3 Categorización de errores
Dado que en esta investigación analizamos la producción escrita controlada de universitarios nativos hablantes de español usando inglés como L2, nos basamos en la descripción de errores de Marín (2013). Las semejanzas entre ambos estudios se encuentran en el tipo de población y tarea (aunque su tarea fue de producción más libre) y la diferencia principal es que nuestra investigación se enfoca únicamente en errores de morfología derivativa, mientras que el autor analiza otros tipos de errores en la composición escrita que no son relevantes para el presente estudio.
Marín (2013) reconoce tres tipos de errores: i) errores de adición, ii) de omisión y iii) de forma errónea. Los primeros se subdividen en regularización, doble marca y adición simple. Debido a que los errores de adición se dan en el ámbito oracional y no léxico, no los tomamos en cuenta, pero se pueden consultar en Marín (2013). El error de omisión consiste en no añadir el morfema requerido, ya sea intencionalmente (proceso conocido como derivación cero, por ejemplo: cook (v) y cook (n)) o por desconocimiento. Y el error de forma errónea, fundamental para nuestra investigación, que se refiere a que el aprendiz use un morfema o una estructura en lugar de otra, se subdividió en cinco categorías. Una de ellas se refiere al uso de un sufijo flexivo en lugar de un derivativo; y las cuatro restantes, al uso de un sufijo derivativo con función gramatical o valor semántico diferente al requerido o que no se puede añadir a bases verbales (ver Tabla 1).
Tabla 1 Clasificación de errores para una tarea de derivación deverbal

Fuente: elaboración propia basada en Marín (2013).
Marín (2013) propone una serie de niveles de errores que retomamos para dar cuenta de la totalidad de errores cometidos por los participantes. Nuestro interés radica en el nivel que los autores denominan error de texto, ya que este opera dentro del sistema léxico-gramatical de la lengua meta. Este nivel se compone de errores formales de léxico y errores gramaticales; y estos últimos se subdividen en errores morfológicos y de sintaxis. Debido a que el autor solamente considera los morfemas flexivos dentro de los errores morfológicos, nuestro análisis se ubica en los errores de léxico, específicamente en tres: i) uso de un sufijo erróneo, ii) uso de una palabra similar y iii) uso de una palabra creada por el estudiante (palabras de nuevo cuño), dejando de lado el error léxico de "uso de un falso cognado"2. El uso de un sufijo erróneo se subdividió en cinco categorías: a) sufijo derivativo con la misma función gramatical y el mismo valor semántico, b) sufijo derivativo con misma función gramatical pero diferente valor semántico, c) sufijo derivativo no nominalizador, d) sufijo derivativo que no se añade a bases verbales y e) sufijo flexivo. El error de uso de una palabra similar lo tomamos como aproximaciones a una palabra conocida en la L1 o la L2 y consideramos que las palabras de nuevo cuño son aquellas que usan un sufijo correcto pero sin modificar la base. Esto debido a que de manera estricta, la adición de cualquier sufijo erróneo resultaría en una palabra de nuevo cuño. De esta manera, los errores de nuestros participantes se clasificaron como se muestra en la Tabla 1, que si bien está basada en Marín (2013), presenta modificaciones para atender las necesidades de la investigación3.
Debido a que los errores de nuestro estudio surgen de una tarea que evalúa el conocimiento distribucional de sufijos nominalizadores, el error de sufijo erróneo que más nos interesa es el tipo 1.1.a derivativo con misma función gramatical y valor semántico. Para claridad del análisis, entenderemos que este error muestra un conocimiento semántico y sintáctico del sufijo, mas no derivacional; y el tipo de error 1.1.e uso de un sufijo flexivo muestra el uso de un sufijo de menor nivel de dificultad. Sin embargo, no podemos sacar conclusiones definitivas de los errores tipo 1.1.b, 1.1.c y 1.1.d, ya que la elección de esos sufijos pudo estar motivada únicamente porque los estudiantes reconocen el sufijo y lo añaden (tal vez al azar) a la base que se les presenta.
Por otro lado, el error 1.2 palabra similar (tax (v) -> taxi en lugar de taxation) muestra ausencia del conocimiento semántico, sintáctico y morfológico de los sufijos. Esto es porque la palabra generada por el estudiante no guarda relación semántica con la base y, por lo tanto, no hay evidencia de ninguno de los otros dos tipos de conocimiento. El error 1.3 palabra creada por el estudiante (increase -> increasement en lugar de increment) demuestra conocimiento semántico y sintáctico del sufijo, aunque no así de la familia de palabras; y con el error 2.1 omisión del sufijo (defer en lugar de deferal), no podemos concluir nada, pues desconocemos el proceso que atendió el participante (derivación cero o desconocimiento). Con este razonamiento y tomando en consideración el nivel de proficiencia de los participantes, se plantean las siguientes hipótesis:
H1. El porcentaje de aciertos aumentará conforme se incremente el nivel de pro-ficiencia de los participantes.
H2. Los estudiantes menos proficientes harán mayor uso de sufijos de baja dificultad (Bauer & Nation, 1993).
H3. Los participantes más proficientes mostrarán un conocimiento más avanzado de la morfología derivacional (Tyler & Nagy, 1989).
2. Metodología
2.1 Selección de los sufijos experimentales
Los cuatro sufijos de la prueba experimental son nominalizadores deverbales con significado de resultado; sin embargo, varían en su nivel de dificultad y de productividad4. Dos de los sufijos experimentales pertenecen al nivel 4, uno al nivel 5 y el último al nivel 6 de la lista de afijos propuesta por Bauer y Nation (1993). En este trabajo se consideran de baja dificultad los morfemas del nivel 4, porque los sufijos que elegimos de este nivel (-ation y -ment) únicamente tienen la función gramatical de nominalizar. De alta dificultad elegimos sufijos del nivel 5 (-al) y del nivel 6 (-y) porque, a pesar de que en esta investigación solo estudiamos la nominalización deverbal, estos dos últimos sufijos tienen diversas funciones gramaticales. Calculamos la productividad de los cuatro sufijos experimentales con base en el corpus Morphoquantics (MQ, en adelante, por Laws & Ryder, 2014) y la fórmula expuesta en Lowie (2005): donde p= productividad, Ntipo es tipo morfológico5 y Ntoken es el número de ocurrencias con ese tipo morfológico. Con la combinación de la productividad y la dificultad, creamos las condiciones experimentales expuestas en la Tabla 2, para estudiar cuáles propiedades morfológicas facilitan la adquisición.

La Tabla 2 muestra los cuatro sufijos experimentales con las variables morfológicas controladas. El sufijo -ation nos permite estudiar el efecto de dos propiedades facilitadoras: baja dificultad y alta productividad, mientras que el sufijo -y representa un sufijo sin ninguna propiedad facilitadora, puesto que es de alta dificultad y baja productividad, y los sufijos -al y -ment nos permiten estudiar la incidencia de solo una propiedad facilitadora: con el sufijo -al se detecta el efecto de la alta productividad, en cambio con -ment se estudia el efecto de la baja dificultad.
2.2 Selección de palabras meta para el estudio
Las palabras para este estudio fueron extraídas del corpus en línea de palabras complejas Morphoquantics (MQ) que contiene 17 943 tipos de palabras complejas derivadas de 835 morfemas derivacionales (554 prefijos y 281 sufijos). El corpus cuenta con 1 008 280 tokens recuperados de la parte oral del British National Corpus (BNC, en adelante) y nos ofrece la categoría gramatical tanto de las bases a la que se añade el morfema, como de las palabras derivadas que generan. También provee la clasificación del afijo (prefijo o sufijo), las diferentes palabras formadas con el morfema (types) y el total de palabras en el corpus con el morfema en cuestión (tokens).
Una vez elegida la función en MQ, descargamos la lista de sustantivos derivados con cada sufijo experimental y corroboramos su categoría gramatical y su valor semántico con varios diccionarios como el Online Etymology Dictionary, Merriam-Webster Dictionary o el Cambridge English Dictionary6. De esta lista de palabras depurada, seleccionamos sustantivos de alta y baja frecuencia con cada sufijo, que fueran cognados y no cognados con el español. No se incluyeron falsos cognados7. Para asegurarnos de que hubiera diferencia de frecuencia entre los sustantivos derivados, consultamos el BNC en su sección escrita, no académica, que cuenta con 16.5 millones de palabras. Finalmente, revisamos el COCA (Corpus of Contemporary American English) en la parte oral, que cuenta con 109 millones de palabras, para sondear la frecuencia de las bases de los sustantivos derivados. Si la frecuencia de la palabra derivada era mayor que la frecuencia de la base de la palabra, esta no se incluía para evitar que los participantes atendieran a un procesamiento léxico y no morfológico en la resolución de la prueba.
El control del efecto de frecuencia de palabra y de la lengua materna resultó en cuatro condiciones léxicas: 1) palabras cognadas de alta frecuencia, 2) palabras no cognadas de alta frecuencia, 3) palabras cognadas de baja frecuencia y 4) palabras no cognadas de baja frecuencia (ver ejemplo con -ment en la Tabla 3). La prueba incluye cuatro palabras por cada condición léxica para cada sufijo experimental.
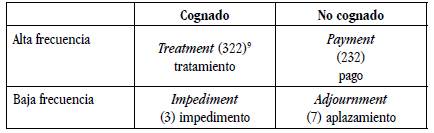
Al igual que con las propiedades morfológicas de los sufijos, pensamos que una palabra cognada de alta frecuencia tiene dos propiedades facilitadoras para la adquisición, que una palabra no cognada de baja frecuencia no tiene ninguna propiedad facilitadora y que los otros tipos de palabras solo tienen una propiedad facilitadora: su alta frecuencia o ser cognada con el español.
2.3 Diseño de la prueba experimental
Elaboramos una prueba de producción controlada basada en la prueba de estructura morfológica de Carlisle (2000), que ha sido ampliamente usada tanto en estudios de la L1 (Muse, 2005; Stanfa, 2010) como en la L2 (Kieffer & Lesaux, 2008; Ramírez, Chen, Geva & Luo, 2011; Curinga, 2013). Esta prueba se divide en dos partes, una tarea de descomposición y otra de derivación. Nuestra prueba solo cuenta con la parte de derivación, debido a que nuestro objetivo era diseñar una prueba de producción y no de reconocimiento de morfemas. Construimos oraciones con una longitud máxima de diez palabras para evitar el cansancio de los participantes. Para inducir la respuesta, proporcionamos un verbo entre paréntesis al principio de la oración que los participantes debían nomina-lizar para completar correctamente la oración (ver 1). No incluimos alomorfos, porque este fenómeno puede afectar los niveles de dificultad del sufijo y, por esta misma razón, también evitamos bases verbales derivadas (disappointment= dis+appoint+ment), a menos que fueran obscuras; i.e. que ya tengan entrada como verbo en inglés (amendment -> amend+ ment).
(1) (betray) Accepting the money would be a betrayal of his principles.
Para evitar que el valor semántico de los derivados influyera en las respuestas de los participantes, optamos por el significado de resultado de los sustantivos deverbales, eliminando así todas aquellas palabras derivadas cuyos significados fueran objeto o parte de un objeto (equipment, instrument), lugar o parte de un lugar (department, pavement) o personas o grupo de personas (regiment). Siguiendo a Sleeman y Brito (2010) con relación al continuo semántico eventivo -> resultativo - > objeto, consideramos que un reactivo tendría una lectura resultativa cuando contara con una o más de las siguientes características: i) la capacidad de pluralización del derivado, ii) que los determinantes que lo acompañen sean indefinidos, demostrativos o cuantificadores y iii) que el derivado aparezca con adjetivos relacionales (derivados generalmente de un sustantivo: intelecto-> intelectual) (Peris & Delor, 2009; Mondoñedo, 2011). Además, se corroboró el significado con la revisión de dos nativos hablantes del inglés.
Colocamos la mitad de las palabras en posición preverbal y la otra mitad en posición posverbal, con la finalidad de que los participantes leyeran los reactivos completos. En total fueron 80 reactivos divididos en 64 de nominalización deverbal (16 para cada sufijo experimental), 16 distractores (ocho para cada sufijo distractor) y seis reactivos de familiarización (ejemplos). Los seis ejemplos fueron con los sufijos -y, -al, -ation, -ment, -ure y -ance, todos usados en su función de nominalizadores deverbales, siendo los cuatro primeros sufijos experimentales. Los sufijos distractores fueron el nominalizador deverbal con valor agentivo -er y el adjetivador deverbal -able. Para llegar a esta versión de la prueba, elaboramos y aplicamos previamente dos pruebas piloto que sometimos a revisión: un experto en diseño de pruebas, un revisor de estadística y un nativo hablante del inglés que juzgó la naturalidad de las oraciones, el significado de las palabras en contexto y los contextos que aceptaban más de una respuesta correcta.
2.4 Aplicación de la prueba experimental
La prueba experimental fue aplicada en una plataforma llamada Class Marker (2018). Las instrucciones estaban en español e inmediatamente después se mostraban los ejemplos. La prueba comenzó con siete preguntas de información personal (nombre, sexo, correo electrónico, rango de edad, nivel -A2, B1, B2-, profesor y facultad) en orden fijo; las siguientes 80 preguntas, correspondientes a los reactivos experimentales, estaban en inglés y las recibían todos los participantes en un orden de presentación distinto y aparecían en sus pantallas una a la vez. Las pruebas se aplicaron en el horario de la clase de inglés, ya sea en el salón de clase de los participantes o bien en un laboratorio de cómputo, y los profesores podían estar presentes. No se les dio límite de tiempo para resolver la prueba y no se penalizaron errores ortográficos o de concordancia. El orden aleatorio permitió inhibir el efecto de orden de presentación de los reactivos. Vale anotar que la plataforma también tiene la ventaja de enviar los resultados de manera inmediata al correo electrónico tanto de los participantes como de las investigadoras.
2.5 Participantes
El grupo experimental se conformó de 130 participantes, 52 hombres y 78 mujeres, estudiantes de de dos diferentes facultades de una universidad pública de la ciudad de Querétaro, México. El nivel de inglés de los participantes estaba previamente establecido por la institución conforme al Marco Común Europeo de Referencia para las Lenguas (MCER). Para la investigación elegimos los grupos que pertenecieran a los niveles A2 (N=55), B1 (N=46) y B2 (N=29). Esta decisión se tomó con base en que nuestra prueba piloto y otros investigadores (Alotabi & Alotabi, 2017) sugieren que la tarea es difícil para niveles menores de proficiencia.
2.6 Corpus para el análisis de errores
El análisis se dividió en dos partes: una para detectar el porcentaje de errores léxicos propuestos por Marín (2013); y otra para identificar diferencias por nivel de proficiencia en los errores léxicos y de sufijo (propuestos para fines de esta investigación). El corpus para el primer análisis es más amplio que el del segundo. Comenzamos por consultar los porcentajes de respuestas correctas en cada palabra experimental según los resultados enviados por la plataforma ClassMarker. Después seleccionamos las cuatro palabras con menor porcentaje de aciertos de los cuatro sufijos experimentales e identificamos sus características de cognado y frecuencia (ver Tabla 4). Las respuestas de todos los participantes (N=130) en estas 16 palabras conforman la base de datos para el primer análisis (errores léxicos), que dio como resultado 2080 reactivos analizados
Para descubrir si la proficiencia de los participantes influye en el tipo de error que cometen, tanto en el tipo de error léxico como de sufijo, tomamos el 20 % de participantes de cada nivel de proficiencia en forma aleatoria (11 participantes del nivel A2, nueve del nivel B1 y seis del nivel B2) y analizamos sus respuestas en las mismas 16 palabras más problemáticas. Decidimos tomar esta muestra del 20 %, ya que este porcentaje de participantes es representativo de cada nivel.
3. Resultados
Encontramos que los errores léxicos más frecuentes en los cuatro sufijos experimentales son el uso de un sufijo erróneo, seguido por el error de omisión y luego por el uso de una palabra similar. Esto quiere decir que, por ejemplo, para la base verbal tax, cuyo derivado es taxation, la mayoría de las respuestas fueron taxed (sufijo erróneo de tipo flexivo), seguidas por tax (error de omisión) y alguna ocurrencia de taxi (uso de una palabra similar). Las excepciones a esta tendencia se dan con la palabra increment, que obtuvo un 35.8 % de respuestas erróneas por palabra de nuevo cuño (increasement) y un 8.2 % de omisión (increase); y la palabra advocacy, que tuvo un 33.6 % de uso de palabra similar (advocation) y un 6 % de omisión (advocate). En la Tabla 4 se pueden ver los porcentajes de errores léxicos con las 16 palabras más problemáticas para todos los participantes, así como las características de cognado y frecuencia de dichas palabras.
Tabla 4 Porcentajes de errores léxicos9

Nota: se usa C+ para palabra cognada, C- para palabra no cognada, F+ para palabra de alta frecuencia y F- para palabra de baja frecuencia.
La Tabla 4 muestra los porcentajes de los errores léxicos propuestos por Marín (2013) y las condiciones de cognado y frecuencia de las palabras con menor porcentaje de aciertos. En cuanto a estas condiciones, destacamos que siete de las 16 palabras más problemáticas no cuentan con ninguna propiedad facilitadora para el aprendizaje, al ser son no cognadas y de baja frecuencia; y 12 de las 16 palabras son de baja frecuencia. Esto sugiere que la alta frecuencia de palabra induce a un mayor número de respuestas correctas. Respecto a las respuestas correctas, encontramos que el porcentaje de aciertos aumenta conforme se incrementa el nivel de proficiencia de los estudiantes (A2= 10.2 %, B1 = 14.6 %, y B2 = 19.8 %)10 aceptando así la H1.
Para el segundo análisis se consideraron dos tipos de errores léxicos: palabra similar (1.2) y palabra creada por el estudiante (1.3) y dos tipos de errores de sufijo: sufijo derivativo con misma función gramatical y valor semántico (1.1.a) y sufijo flexivo (1.1.e). Encontramos que el error más frecuente para todos los participantes fue usar un sufijo flexivo. Sin embargo, para el nivel B2 la diferencia es mínima entre este error y el uso de un sufijo derivativo con la misma función gramatical y valor semántico (30 % versus 29 % respectivamente). Notemos que esta diferencia aumenta conforme disminuye el nivel de proficiencia de los participantes: 39 % versus 28 % en el nivel B1, y 37 % versus 19 % en el nivel A2 (ver Figura 1). Esto sugiere que los participantes de menor proficiencia usan más frecuentemente sufijos de menor nivel de dificultad según la escala de Bauer y Nation (1993), aceptando así la H2.

Asimismo, la Figura 1 nos permite ver que los errores de uso de un sufijo derivativo con la misma función gramatical y valor semántico (como refnation por refinement) y el de palabra creada por el estudiante (como increasement por increment) ocurren en mayor proporción en los niveles altos de proficiencia. Estos errores demuestran conocimiento tanto semántico como sintáctico de los sufijos, pero no distribucional. En oposición, el uso de una palabra similar (como taxi por taxation oforget porforgery) no muestra ningún tipo de conocimiento de los propuestos por Tyler y Nagy (1989). De este modo aceptamos la H3: los participantes más proficientes mostrarán un conocimiento más avanzado de la morfología derivacional.
4. Discusión y conclusiones
El análisis de las palabras con menor porcentaje de aciertos tuvo como objetivo identificar diferencias porcentuales y tipológicas de errores entre participantes mexicanos con diferente nivel de proficiencia en inglés. Encontramos que, en general, los participantes eligen un sufijo de menor dificultad (especialmente flexivos), aunque también encontramos un sobreuso del sufijo -ation (nivel 4 de dificultad), sustituyendo a cualquier otro sufijo experimental, y algunas instancias de sobreuso con el sufijo -ment (nivel 4) cuando se esperaban respuestas con los sufijos -al (nivel 5) o -y (nivel 6) (ejemplos: refination por refinement, dispersement por dispersal).
A propósito de la proficiencia, descubrimos divergencias en el porcentaje y tipo de errores que cometen los estudiantes de diferente nivel. Resaltamos que el uso de sufijos flexivos disminuye en el nivel B2 y que estos participantes y los del nivel B1 tienden a elegir un sufijo con la misma información gramatical y semántica que el requerido; es decir, un nominalizador deverbal con valor de resultado. Sin embargo, su elección es errónea, ya sea porque la palabra derivada no existe con ese sufijo (adjournation en lugar de adjournment) o porque el contexto restringe la conveniencia del sufijo nomi-nalizador (producen, por ejemplo, dismission en lugar de dismissal, siendo que las dos palabras existen pero la segunda se ajusta mejor al contexto). Pensamos que algunas elecciones erróneas con palabras reales pueden deberse a la frecuencia de la palabra derivada (treatment es mucho más frecuente que treaty), a diferencias semánticas sutiles (advocation por advocacy) o a la productividad del sufijo, su nivel de dificultad y su condición de cognado (los hispano hablantes pueden tener más tendencia que hablantes de otra L1 a producir dispersion en lugar de dispersal). En conjunto, estos resultados sugieren que el conocimiento sintáctico y semántico de los sufijos antecede a su conocimiento distribucional en la adquisición del inglés como L2, tal como lo sugieren Tyler y Nagy (1989) para la L1.
Los resultados de esta investigación pueden ser de gran utilidad para maestros y lingüistas interesados en la adquisición morfológica en la L2, puesto que proporcionan información para planear secuencias didácticas efectivas, muestran una manera eficaz de evaluar el conocimiento distribucional de los sufijos y revelan, a partir de los errores, un paso más en la interlengua del inglés como L2.

