











 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink1. INTRODUCTION
Reverse-Time Migration (RTM) is a seismic imaging method that uses the solution of the full wave equation to obtain imaging of complex areas, particularly those with abrupt changes of lateral and vertical velocities. It was initially proposed by Baysal [1], but only the last decade progress in computing technologies has allowed the implementation of the algorithm and its practical use in 3D depth seismic processing projects. In recent years, there has been growing interest in high-performance computing (HPC) architectures based on graphic processing units (GPUs) that assemble a considerable amount of computing devices with single instruction multiple thread (SIMT) cores [2]. HPC based on GPUs are suitable architectures for the implementation of RTM, because of the inherent parallelism on each time step in the algorithm [3]. In addition to the computing resources, RTM also demands large memory resources, as the source and receiver wavefields must be available for computing imaging condition. Thus, depending on the volume of the wavefields, the implementation can exceed the limit of a single device (GPU) memory. This implies the use of higher memory hierarchy levels, which degrade the code performance due to the data transfer overhead.
A different approach to overcome the GPU memory constraint is to use implementation strategies where memory requirements are reduced in exchange for increasing the number of computing operations because the source wavefield should be recomputed. Some strategies have been already implemented for CPU architectures, such as optimal checkpointing proposed by Dussaud et al. [4], which can be adapted to GPU architectures.
The aim of this work is to evaluate three different GPU implementation strategies of the RTM method, focused on memory management such that a 3D shot can be migrated in a single GPU, thus avoiding expensive transfers from (or to) host RAM or hard disk memory. The main contribution of our work is to demonstrate that the robust oil industry RTM algorithm can be effectively mapped to GPU based architectures. Our RTM implementation is based on a 3D Time Domain Finite Difference numerical scheme to solve the acoustic wave equation, with absorbing boundary conditions. The conclusions of this work about the GPU memory management in the analyzed strategies can be extended to simulations based on the same numerical scheme for other forms of wave equations, such as visco-acoustic, elastic or electro-magnetic.
This document is organized as follows: the RTM method is introduced in Section 2 and the implementation strategies of the RTM method in Section 3. Section 4 summarizes the main characteristics of the GPU architecture used for this work. Section 5 presents the performance results from the different RTM implementations and, finally, the conclusions and discussion are presented in Section 6. All the implementation strategies are assessed in terms of the resulting image quality, memory requirements, and execution times.
2. THEORETICAL FRAME
RTM is a mainstream method used to generate subsurface images in complex areas, which favors the identification of possible reservoir locations. RTM generates a reflectivity map R(x,y,z) by computing an imaging condition from the correlation between the source and the receiver wavefields. This condition is given by

where p s (x,y,z,t) is the source wavefield, which is obtained by propagating the source through the medium; and p r (x,y,z,t) is the receivers wavefield, which is obtained by backpropagating the seismic traces information. Both wavefields require a numerical solution of the wave equation that models the propagation of a seismic source through a medium. In this work, we use the constant density acoustic wave equation to model the propagation of a seismic source. The isotropic acoustic wave equation is given by

where ∇s is the Laplacian operator, and v is the p-wave velocity model of the subsurface. One of the most common methods to find the numerical solution of the wave equation is applying finite differences to the temporal derivative and compute the Laplacian operator with finite differences or pseudo-spectral methods. The 2nd order finite difference approximation in time for the temporal part of the equation is given by

In Equation 3, p k is the p wavefield in the time t= kΔt. The source wavefield can be computed from t=0 to t=tmax, assuming a non-perturbed media in the two first time steps and knowing the source position and its wavelet signature. In the same way, the receiver wavefield can be back propagated from t=tmax to t=0 assuming zero values in the last two time-snapshots and injecting the seismic traces as sources.
ABSORBING BOUNDARY CONDITIONS
Representing the wavefield on a memory-constrained computing system implies that only a reduced time-space part of the wavefield can be stored. This means that artificial boundaries are created in the border of the model. Depending on the numerical method, the effect of the border can be: periodicity, if pseudo-spectral methods are used; or reflections, if finite differences are used. In any case, the energy reaching the artificial boundaries must be vanished, so that it does not affect the migrated image. Several algorithms have been proposed to manage the artificial boundaries. Perfectly Matched Layer (PML) was used in this work for the first two strategies, as it is an efficient and simple method. The third strategy uses a random boundary method as proposed by Clapp [5]. In particular, for the PML absorbing boundary conditions, we opted for the convolutional PML (CPML), proposed by Pasalic [6], which applies PML directly on the second-derivative wave equation in (2). The main idea of CMPL is to introduce a complex stretching parameter given by

in the differential operators of the acoustic wave equation on each direction i∈[x,y,z], σ i and α i are parameters that adjust the behavior of vanishing energy. The new differential operators in the wave equation are

where ψ i and ζi are two additional wavefields that are computed recursively on each time step as follows

In previous equations, a i and b ¡ are given by

Now, substituting the second derivatives given by Equation 5 in the acoustic wave equation in (2), we have

Equation 8 is applied near the model borders. To use this equation the computation of a time snapshot follows the next three steps:
1. Update ψ i n using ψ i n - 1 and the first derivative of p n.
2. Update ζ i n using ζ i n-1, the second derivative of p n and the first derivative of ψ i n, computed in the previous step.
3. Use Equation 8 to compute p n+1.
The fields ψ i and ζi require extra memory for each PML border.
EXPERIMENTAL DEVELOPMENT
MEMORY MANAGEMENT STRATEGIES
The implementation of the RTM algorithm requires large amounts of memory in real seismic surveys. Naive implementations of this algorithm can easily exceed the GPU memory limits, as it is shown in Table 1; therefore, it is necessary to consider strategies to reduce the memory usage. These strategies recompute the wavefields when they are required, instead of storing the entire wavefields. Thus, memory-constrained architectures, such as GPUs, can be used at the cost of increasing the execution times of the algorithm.
Table 1 Variation of the memory requirement to store the full wavefield for different frequencies fq of the source wavelet.
| fq[Hz] | dh[m] | Nx | Ny | Nz | dt[ms] | nt | Wavefield Snapshot [MB] | FuU Wavefield [GB] | Wavefield Boundaries [GB] |
| 3 | 160 | 85 | 85 | 26 | 16.17 | 309 | 0.75 | 0.23 | 0.06 |
| 6 | 80 | 169 | 169 | 50 | 8.08 | 618 | 5.71 | 3.53 | 0.67 |
| 12 | 40 | 337 | 337 | 99 | 4.04 | 1237 | 44.97 | 55.63 | 6.13 |
| 18 | 27 | 505 | 505 | 148 | 2.69 | 1855 | 150.97 | 280.06 | 21.72 |
| 24 | 20 | 673 | 673 | 197 | 2.02 | 2474 | 356.91 | 882.99 | 52.74 |
| 31 | 16 | 841 | 841 | 246 | 1.61 | 3092 | 695.96 | 2151.92 | 104.5 |
In the RTM algorithm, each shot requires a sub-model size according to the patch size, the migration apron, and the absorbing boundary Layer width, as shown In Figure 1. We estimate the memory capacity required by the RTM algorithm for a FDTD approximation of 8th order in space and 2nd order In time, an extended absorbing boundary layer L=8 grid points, tmax=5s, single precision floating point representation, and a full migration apron. The velocity model size and the time step can be reduced depending on the central frequency fq of the source wavelet. This reduces significantly the memory requirements, but the numerical method must satisfy the stability and a minimum number of points per wavelength. Table 1 shows the amount of required memory, and maximum spatial and time sampling steps for different central frequencies of the source wavelet, assuring a minimum number of points per wavelength of ppwl = 3. The information given In Table 1 is for the SEG synthetic velocity model.

Note in Table 1 that for source wavelet of central frequency of 31 Hz, the computing system may require up to 2 TB of memory to store the source wavefield for all the 3092 time steps. This amount of memory could be available at low memory hierarchy levels, such as hard disk drive, although its use may cause very slow and inefficient execution of the RTM algorithm. To overcome this problem, various strategies have been reported [4]. In this work, we focus in evaluating such strategies to select those that can be used in industry applications using a single GPU to migrate a single RTM shot.
STRATEGY 1: STORING WAVEFIELD CHECKPOINTING
The first strategy uses the available memory in the GPU device to store checkpoints in the source modeling process. When the imaging condition requires a non-stored source wavefield snapshot, it is recomputed from the nearest checkpoint. Additional to uniform checkpoint distribution along the modeling time steps, optimal checkpointing strategies have also been reported in the literature [7], [8]. These strategies increase the computational complexity, while reducing the memory complexity to a logarithmic function of the total number of steps.
STRATEGY 2: BACKPROPAGATE THE SOURCE WAVEFIELD USING STORED BOUNDARIES
In the previous strategy, the source wavefield is recomputed in the forward direction starting from checkpointing snapshots. However, the source propagation is a reversible process itself, taking into account that we can solve for p i-1 in Equation 3 instead of solving for p i+1 . This allows us to propagate the source field up to tmax and then recompute it backwards, saving only the two last time steps with two memory buffers.
The main problem with this strategy is that the energy at the boundaries cannot be reversed, as the PML vanishes the energy reaching the model's border. This means that on a single time step, the field in the inner part of the model can be recovered, but the PML must be stored [9], [4]. Strategy 2 is an efficient implementation strategy, in terms of memory management, but the amount of memory used to store the wavefield at the boundaries can depend largely on the size of the model. For the velocity models shown in Table 1, and assuming FDTD approximation of 8th order in the spatial derivatives, the wavefield at the boundaries ranges from 0.06 GB up to 104.5 GB of memory. Currently, the most advanced GPU cannot handle such amount of memory, making this strategy impractical for industry applications using a single GPU.
This strategy can be extended to the RTM with a visco-acoustic modeling but the wavefield should be reconstructed including attenuation phenomena [10].
STRATEGY 3: BACKPROPAGATE THE SOURCE WAVEFIELD USING ONLY TWO LAST SNAPSHOTS AND RANDOM BOUNDARIES
The random boundaries technique proposed by Clapp [5] extends the velocity model with carefully generated random values. The goal of this technique is to generate a random reflection pattern of the energy reaching the model's border. Its two main characteristics are: first, the energy reflected by the boundaries at the source wavefield is not coherent with the receiver wavefield and, therefore, the final image will be affected only by a random noise; second, the energy is not vanished and the modeling process is now reversible with a stable scheme. The latter reduces significantly the memory requirements as the wavefield at the boundaries does not need to be stored, and the source wavefield only requires the last two snapshots to be recomputed. These features allow for successful application of strategy 3 to in industry applications where a 3D shot can be migrated with RTM in a single GPU without any problem with the memory available in the device.
GPU ARCHITECTURE
The RTM strategies under study in this work will be implemented on the Nvidia K40 GPU. Therefore, in this Section we describe only the GPU architecture, and the specifications of the CPU, host RAM and I/O bandwidth are irrelevant for the paper's main objective.
GPUs are parallel computing devices designed for video operations such as image rendering. These devices contain hundreds of cores based on a Single Instruction Multiple Thread (SIMT) architecture and have been adapted for scientific computation algorithms. Nowadays, general purpose applications can be developed using these devices with programming models and APIs like CUDA and OpenCL.
The GPU gathers thousands of computing elements in a single chip adding new memory hierarchy levels as shown in Figure 2. These computing elements represent more computational power than conventional CPUs, but they require optimal data transferences to achieve the best performance. Data reaches GPU from CPU through the PCI bus, and it is stored on the device memory. Then, the data can be accessed from the computing cores and can be cached in shared, LI and L2 memories.

Programmers employ cores launching a large amount of threads on the GPU. This hides memory latencies creating a pipeline between computing and memory access operations. The threads have their own hierarchy, which constrains the hardware resources they can access. This is shown in Figure 3. A single thread can have its own general purpose registers; a group of threads, called a block, may have access to the resources of a single Streaming Multiprocessor (SMX) including shared memory, and the grid conformed by the whole set of thread blocks can access all device resources including the device RAM memory.

To understand the GPU components and to make efficient applications, programmers use the hardware abstraction model of the GPU given by the available APIs. Also, GPU vendors provide recommendations to Improve application's performance, especially on memory access. These recommendations include the reduction of memory transfers between CPU and GPU, but due to the large memory required by the RTM algorithm, GPU RAM could be not enough to store all the wavefields, and CPU RAM may be used. This increases the data transfers between GPU and CPU and decreases performance significantly; hence, computing strategies become the solution to make all calculations using only the GPU memory
4. RESULTS
The three strategies of the RTM method were Implemented on a Nvidia K40 GPU. The constant density acoustic wave equation was solved using FDTD approximation, and the CPML condition was implemented to avoid artificial reflections on the model's border for the first two strategies. The last strategy uses random boundaries to manage artificial boundaries.
The essence of all strategies Is the routine to generate one time-step in the modeling process. At each time-step, the wave equation is solved with an explicit scheme, such that each point in the model can be computed independently. In the proposed parallel implementation, one time-step Is generated in two GPU kernels: one for the wave equation, and one for the CPML absorbing boundary conditions, such that all spatial points of a single snapshot are computed in parallel. Before starting a GPU process, the data must be transferred to the GPU memory. The transfers between GPU and CPU must be minimized as they are slow compared with the computing time. The capacity of the GPU memory available to process each shot for the K40 GPU device memory is 12 GB.
The proposed parallel implementation for the three strategies was tested using the SEG velocity model shown In Figure 4. The model parameters and data are shown in Table 2. The average execution time to migrate a single shot and the GPU memory required by all strategies are shown In Table 3.

Figure 4 Left: Cross-line of the SEG velocity model at 7.44km. Right: In-line of the SEG velocity model at 5.12km.

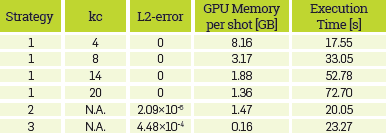
Table 3 L2-error norm of the migrated image using all strategies compared with the migrated image storing the entire wavefields. GPU memory and execution times required for all strategies.
STRATEGY 1 STRATEGY 3
This strategy only stores some snapshots of the source wavefield and the missing snapshots are recomputed from the last stored checkpoint. To analyze the required memory and the execution time, the imaging condition was calculated on each time-step, but the interval to set our checkpoints range from kc=4 to kc=20. The memory resources and the execution times used by this strategy, for different kc values, are shown in Table 3. The resulting image is shown in Figure 5. These images are used as reference to compare with the images obtained with the following strategies.

STRATEGY 2
The second strategy only stores the boundaries of the source wavefield. The L2-error norm obtained with this strategy is 2.09 x10-6 and the computational resources are also shown in Table 3. The migrated image is shown in Figure 6 -left and -right. Note that the error in the quality of the migrated image is tolerable, and the balance between the GPU memory requirements and execution time makes this strategy very convenient for large size 3D models.

Figure 6 Left: Crossline of the migrated image at 7.44 km, and Right: Inline of the migrated image at 5.12 km; using RTM implementation with strategy 2.
The last strategy presented herein required only 0.16 GB of device memory, but the L2-error norm is 4.48x10-4 compared to the migrated image obtained with strategy 1. The migrated image obtained with this strategy is shown in Figure 7. It must be noted that, despite the numerical error obtained with this strategy, the image locates adequately the reflectivity map as there is incoherent random boundaries energy reflection and, therefore, the forward and backward wavefields correlate poorly, minimizing coherent artifacts produced by the boundaries. The greatest error is caused by the top boundary that is very close to the source and generates strong random reflections and diffractions at first modeling time snapshots. Different solutions can be used to solve this problem, such as applying PML boundary conditions to the top part of the model or increasing the random boundary length at the top. Those solutions, however, would increase the memory amount requirements of strategy 3.

Figure 7 Left: Crossline of the migrated image at 7.44 km, and Right: Inline of the migrated image at 5.12 km; using RTM implementation with strategy 3.
Figure 8 and Figure 9 compare the results of strategies 2 and 3 respect to the reference: Strategy 1. The magnitude of the difference is larger in strategy 3, according to the L2 error calculated on Table 3. The error in Strategy 2 is located on the top of the model as the reconstruction of the source wavefield is less accurate on the early time steps, near to the source location. This means that the error is mainly produced by numerical rounding due to the recomputation the source wavefield. Furthermore, strategy 3 locates the error near the lateral random boundaries.

Figure 8 Left: Crossline of the difference between the migrated images at 7.44 km, and Right: Inline of the difference between the migrated images at 5.12 km; using the RTM implementation strategies 1 and 2. The amplitude of the images is amplified 106 compared to Figure 6.

Figure 9 Left: Crossline of the difference between the migrated images at 7.44 km, and Right: Inline of the difference between the migrated images at 5.12 km; using the RTM implementation strategies 1 and 3. The amplitude of the images is amplified 103 compared to Figure 7.
Finally, Figure 10 presents a comparison of memory usage for all strategies as a function of the execution time. The best execution time is achieved by Strategy 1, but it also requires the largest memory. This strategy trades off between memory and computation time, depending on the kc parameter. This makes this strategy a very flexible option to fit the algorithm on any memory constrained architecture. For the specific experiment, Strategy 2 has good performance in terms of memory and execution times at the same time. However, in a large scale problem, the GPU memory available can be exceeded when the boundaries are large. Strategy 3 obtains the best ratio between execution time and memory, but due to the boundary conditions method, it introduces an error in the image. However, the quality of the image is acceptable in terms of reflection events and the artifacts can be attenuated applying post-processing filters to reduce incoherent noise in the image.

CONCLUSIONS
In this work, we evaluate three RTM implementation strategies focused on managing the memory, such that the seismic RTM algorithm can be executed on a single GPU device. The GPU is a memory-constrained architecture that reaches its maximum performance when memory transfers from (or to) CPU are minimized. In the strategies studied herein, each shot is migrated independently by making only memory transfers at the beginning and end of the migration. The entire source wavefield cannot be fully stored in any GPU available. Furthermore, the three strategies analyzed in this work fix this problem by recomputing portions of the source wavefield.
Strategy 1 can use all the memory available on the GPU by adapting the checkpoint parameter; however, the computing time increases. Strategy 2 stores the boundary of the source wavefield to recompute it backwards in time and gets good balance between the GPU memory requirements and the execution time; however, if the GPU memory available is not enough to store the boundary and the two last snapshots, this strategy cannot be used. Finally, Strategy 3 has the lower execution time and requires less memory as compared with other strategies. Nevertheless, the reconstruction of the source wavefield introduces numerical error in the migrated image. Strategy 3 is therefore the recommended strategy to implement in the GPU architecture for large data and the numerical error in the final image produced by the random boundaries can be removed with post-processing techniques such as FX-decon [11], TFD [12] and structure tensors [13].
To conclude this analysis, the maximum frequency that can be migrated with the same parameters, the same velocity model, and the same GPU used in this article are determined. The results show that Strategy 1 can migrate up to 30 [Hz], Strategy 2 can migrate up to 30 [Hz] and Strategy 3 can migrate up to 70 [Hz]. Then, we extend this analysis to a hypothetic advanced seismic acquisition, such as broadband, which provides both low and high frequencies to obtain better resolution in imaging. In this case, RTM migration has the challenge to process data with frequencies above 100 [Hz]. Thus, we propose a marine survey acquisition with 18 cables 8000 [m]. The maximum frequency that each strategy can migrate, using the same GPU, is: 3 [Hz] for strategy 1, 3 [Hz] for strategy 2 and 12 [Hz] for strategy 3.
The frequency parameter quickly increases the memory required as it reduces spatial sampling of the velocity model and the timestep propagation. This analysis validates our recommendation about using Strategy 3 for migrations with high memory requirements.

