











 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
Introduction
Student evaluation of teaching (SET) is an ad-hoc way of assessing teaching effectiveness in higher education institutions 1. Feedback from students can assist teachers in comprehending the students behaviors and improve teaching practice 2,3. Receiving feedback can highlight different issues that arose during the course, related to the material, readings, course tools and even teaching practice. For this reason, educational institutions, centers, and faculty staff rely on tools to gather information and aid instructors in supporting student learning 4-6.
Despite end-course systems showing surveys with dichotomous, closed, or likert questions being quickly processed, the same cannot be said for open-ended questions or free-text responses, which often demand more time and effort for comprehensive analysis. This poses a challenge for teachers who must decipher student feedback, opinions, and comments from evaluation software, resulting in time lost if the lecturer should to understand the text. In addition, it leaves it up to you to assign the polarity of the comments; It is the teacher who decides if they were positive or negative 5,7.
The reason behind using student feedback for the improvement of teaching is to give a comprehensive view of teaching from the students’ perspective, which might result in valuable information or data for teachers 8. Interest in student perception is increasingly becoming a prominent method for evaluating multiple elements of the academic context, teaching practices, student engagement, and even the achievement of learning objectives 9-12. Collecting short feedback messages at the end of a course offers numerous benefits for both the lecturer and future students, including adjustments to teaching practices, slides, readings, activities, student behavior and also provides to lecturer an summarized overview of student opinions.
Recently, artificial intelligence (AI) has made remarkable advancements across multiple domains, stretching the limits of what was once deemed impossible and opening up a new era of exploration and innovation. The large linguistic models (LLMs) can be considered a relevant development for the Natural Processing Language (NLP) because these can perform a wide variety of tasks, such as summarizing, synthesizing, translating content, and analyzing the sentiment of sentences, comments and reviews. LLMs use a transformative architecture and have been incorporated into several popular tools like Google's Bidirectional Encoder Representations from Transformers (BERT) 13, OpenAI's Generative Pre-trained Transformer (GPT) 14 and among others not so well known.
Addressing the situation of teachers reading, understanding and evaluating students feedback comments nowadays can be automated using sentiment analysis, opinion mining and other approaches 15-18. In particular, the analysis of the comments at the end of the course, which is when the teacher should receive information about his or her practice in a way that allows him or her to modify or adjust it for a next iteration.
The paper aims to classify the polarity expressed in teaching feedback at the end of the course using a Large Linguistic Model (LLM), present word clouds, statistics, trends and other analyzes from the comments through a prototype tool. The sentiment analysis of Student evaluation of teaching (SET) can be considered as a strategy to improve teaching practice. The analysis of student comments allows us to identify elements of teaching practice that caused difficulties for students. The rest of the paper has been organized as follows. Related research is presented in section 2. The research method is presented in Section 3. Followed by results and discussion in Section 4. To finish, conclusions and future work are outlined in Section 5.
Related Work
Sentiment Analysis (SA) for education can vary depending on the context and multiple tasks that can be addressed. Commonly, sentiments surrounding education can range from positive to negative. In this context, the emotions affect the motivation and the outcome of the learning process 19-21. The role of Artificial Intelligence (AI) in sentiment analysis is crucial for aiding specific processes and tasks related to student comments 22. Modern AI-powered tools excel at discovering polarity, classifying, and predicting emotions within unlabeled sets of comments 23. Numerous studies have explored sentiment analysis (SA) in education, with a substantial focus on e-learning, classroom learning, and daily sessions and real-time interventions 25,24.
Similarly, there is an interest in feedback and student comments due to their potential to offer valuable insights into student learning behaviors and to enhance teaching practices. For example, the student perception of teacher feedback 26, the relationship between feedback and learning motivation27, the feedback as part of student satisfaction 28, sentiment analysis of student feedback 29-32) and this last using techniques as Support Vector Machines33, Naive Bayes 34, dictionaries, lexicons 29, and more recently, Deep Learning-based models35 and Language Learning Models (LLMs) 16,17,36,37. Making important advances in data analysis within the educational context aimed at understanding, automating and improving the learning experience.
Experience that is then evaluated by students at the end of the course. For a century, numerous institutions around the world have implemented Student Evaluations of Teaching (SET) systems for storing, retrieving, and processing student evaluations of courses and teaching 38. Course and teaching evaluations tools designed to present surveys, evaluate academic performance and that have been maturing until today as a study object to improve the teaching 39-41.
Modern course evaluation SET tools incorporate Likert scale, numeric and open-ended questions, allowing students to provide textual feedback, creating a notable gap in the comprehensive analysis of sentiments and opinions after the course is completed 42-44. In this paper, we propose the sentiment analysis of textual end-of-course feedback using a LLM-based approach to enhance the teaching and learning processes.
Methodology
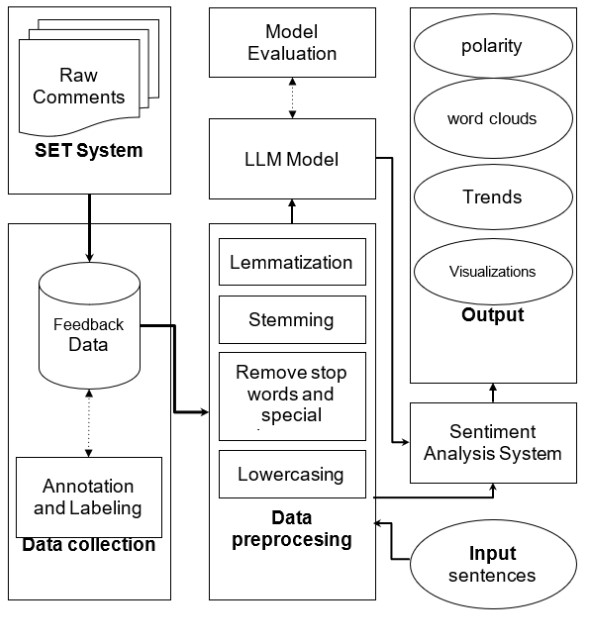
In Fig. 1 the schematic process carried out in our sentiment analysis for end-course students feedback. While drawing inspiration from existing frameworks like 45, the approach suits our own requirements as the customizations in preprocessing techniques, dataset annotation procedures, model evaluation methodologies, and preprocessing new teacher inputs. Student comments are sourced from official SET systems, then they are preprocessed before being fed into the Large Language Model (LLM) operating within the sentiment analysis system. The analysis facilitates the generation of visualizations such as word clouds and other graphical representations, providing to the teacher a comprehensive understanding of sentiment patterns and trends within the student feedback.
In this paper, we consider a quantitative and qualitative approach. Quantitatively we employ performance measures to assess three pre-trained LLM-based models, this provides valuable insights into potential of Machine Learning models. Qualitatively, we describe a case study and the characteristics of our prototype tool.
Dataset description: Our dataset comprises 365 Spanish comments collected between 2018 and 2023 encompassing feedback messages from end-of-course evaluation at Universidad del Valle and report from Pontificia Universidad Javeriana, both at Cali, Colombia. Due to scarcity of spanish labeled dataset, the dataset was annotated with positive, neutral and negative using crowdsourcing approach. Participants chose a class for students' comments and the more frequent orientation was established as a label. Table 1. shows a few annotated examples. Dataset distribution was 60%, 32% and 8% as Positive, Negative and Neutral respectively.
Table 1 Sample Feedback Comments in dataset. Source: Authors
| No. | Sentence | Label |
|---|---|---|
| 1 | El profesor manejó una buena metodología en el curso | Positive |
| 2 | Agregar más uso de terminal de forma práctica en clase. | Neutral |
| 3 | Sería mejor si el curso se dictará de manera presencial. | Positive |
| 4 | Contestar el correo y tener otros medios para comunicarse | Negative |
| 5 | Nirguna, been curso y professor. | Positive |
Preprocessing: Student feedback is unstructured texts and to analyze them a preprocessing stage is needed. At this stage, the text was divided into sentences and junk elements like stop words, numerical values, and certain special characters were removed to reduce noise in the data set. Using NLTK 46 and spaCy 47 for these tasks, all words were transformers to lower case and stemming and lemmatization were optional in experimentation and model evaluation stage. Additionally, person names and feedback messages such as "ninguno", "sin comentarios", "sin observaciones" were manually removed because they had no relevant content.
Pre Trained LLM: After the preprocessing the dataset three deep pretrained models for spanish language were used: i) Py-sentimiento, a Robertuito and RoBERTa-based model trained in spanish tweets 48-50, ii) a customized version of VADER (Valence Aware Dictionary and sEntiment Reasoner) wich translate comments and classify the text polarity 51 and iii) Distilbert-based model, a small, fast and light Transformer by distilling BERT base 52,53.
Fine-tuning plays a critical role in the training of models with initial parameters. However, there are instances where these parameters need modification to incorporate or adapt to specific tools or contexts. The Hugging Face Transformers library offers pretrained models, and within it, the Training Arguments function, which furnishes an intuitive and user-friendly interface for managing key aspects of the training process 54,55.
Tool design and development: The implementation of a tool to support improving teaching and learning using sentiment analysis entails a comprehensive approach focused on leveraging advanced technologies and software development methodologies.As part of study approach Rapid Application Development (RAD) methodology was adopted for designing and development of ASETool, focusing on the rapid build of prototypes focused on the end user. With a containerized-microservices architecture, ASETool separate services for data preprocessing, sentiment analysis, and user authentication allowing scalability, portability and other advantages.
The foundational user interface concept of the proposed system is delineated in Fig. 2a, while the architectural depiction, featuring pivotal elements and model integration, is presented in Fig. 2b.
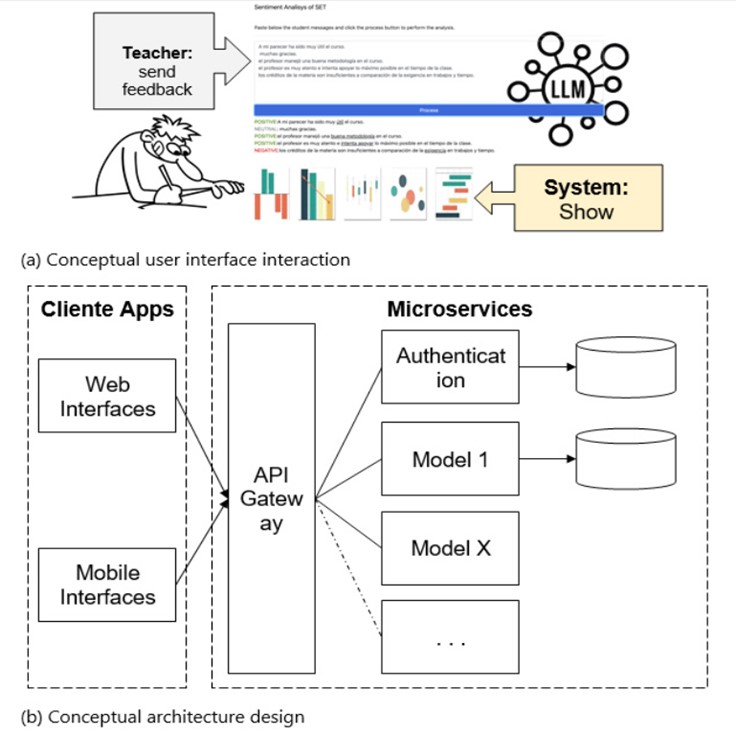
ASET tool presents a user-friendly and web-based design for ease of use by both technical and non-technical educators. With the interface interaction educators possess the capability to submit multiple comments via the interface and subsequently conduct textual analysis. The architectural design allows developers and stakeholders the opportunity to seamlessly integrate novel models and features into the existing architecture, thereby ensuring a harmonious and adaptable system.
Results and discussion
In the absence of a standardized and labeled end-of-course assessment data set, crowdsourcing makes the labeling possible rapidly and cost-effectively 56,57. As part of the approach, the completely labeled dataset was used as a baseline to compare the classification performance from each model following the key idea that crowdsourced sentiment is more accurate 57. The accuracy metric was employed to evaluate the correspondence between the predictions from each model and the crowdsourced labels. In this context, accuracy indicates how well the model can discern the polarity of the texts and whether the predictions are equal to human judgment.
Table 2 Performance Analysis of Analysis of textual feedback.
| Model | Accuracy |
|---|---|
| Pysentimiento | .85 |
| Distilbert | .93 |
| Vader | .79 |
Source: authors
Table No. 2. show the performance of models. For the real-world dataset used in this study the models were consistent for crowdsourcing labels validating the viability for sentiment analysis in end-of-course evaluations. In fact, two of three models considered present an accuracy major than 80%. Coinciding with other studies where popular and non-free LLMs such as GPT (14) have demonstrated the potential for student feedback sentiment analysis achieving relevant performance 16.
Large language models (LLMs) have the potential to automate analysis and improve information richness to improve teaching. LLMs can influence teaching practice based on student's messages, which can be shaped by our conceptual approach.
Accuracy scores indicate that the LLM predictions are similar to those made by a human. The results show that the multilingual-distilbert model adapted for sentiment analysis can classify the polarity of a text in a way that is similar to a person, making these tools can be used for automatic analysis. In particular, for this study, the positive polarity from end-course evaluation raises can reveal a course satisfaction and the teacher could continue with its methodology and practice. However, It is expected that students do not feel satisfied, write negative or neutral comments that can be automatically analyzed. Fig 3. shows the amount of the feedback comments labeled from crowdsourcing (Crowd) and automatically using Vader (M1), Distilbert (M2) and Pysentimiento (M3).
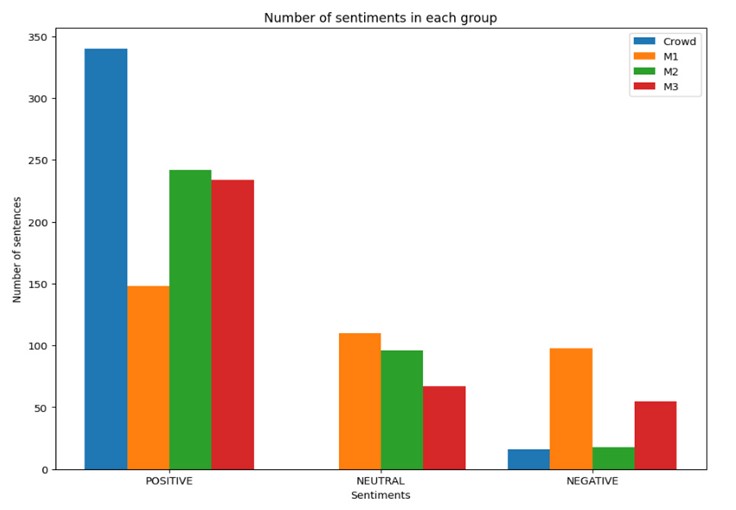
From the study dataset, we observed that negative comments tend to have a greater length compared to positive or neutral ones. Sentences such as "buen curso", "me gustó", "estuvo chevere!" were used by students to express positive feedback while in negative cases more words to express disgust, displeasure, dissatisfaction which leads to negative polarity.
Based on crowdsourced labeling, we obtained positive or negative messages for the feedback messages in the data set, with no neutral sentences being recognized. While crowdsourcing has been widely employed for labeling tasks, in our case, the absence of neutral labels poses an intriguing aspect to explore, especially if our objective were to train machine learning models. The lack of neutral labels may suggest a bias or imbalance in the data collection.
The ASET system prototype has great potential, taking raw comments and performing an analysis of sentiments and emotions in feedback when the course has ended to improve teaching and consequently the learning using end-course feedback. The used microservices architecture required real-time sentiment classifier model which was situated in an isolated container. As evaluated the ASET architecture shows various advantages such as the creation, update and deployment of new versions and ML models for sentiment analysis. Furthermore, isolated environments allow fix issues without impacting other parts of the application, such as user interfaces, models and other services. Thus improving the overall resilience and reliability of the application.
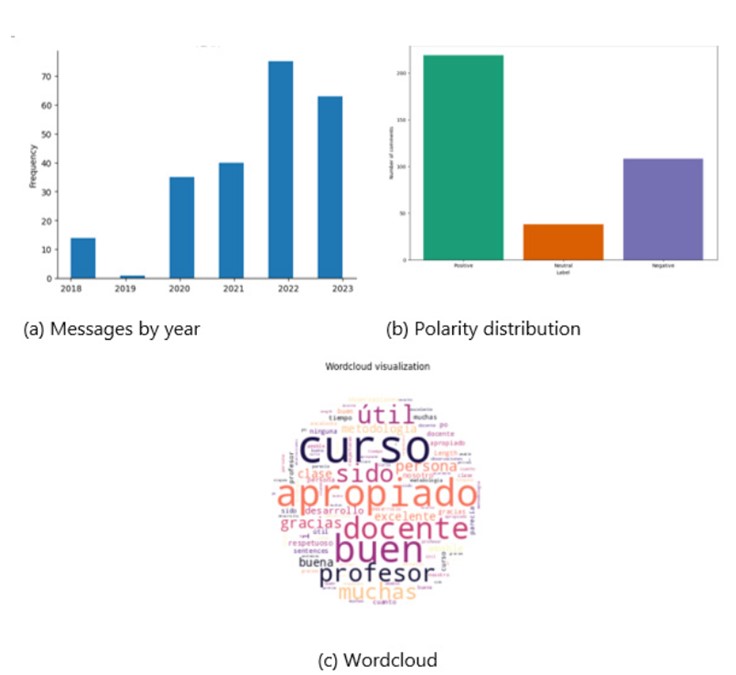
In the analysis of end-of-course comments collected over recent years, the first graph shows the volume of comments for each course is an underutilized resource that can be effectively processed with machine learning techniques. For this reason, we perform the analysis of end-of-course comments collected over the last six years using ASET tool, Fig 4a shows the distribution of comment counts per year, providing a clear visualization of trends over time. Using the dataset, Fig 4b illustrates the distribution of comment polarity, highlighting the proportion of positive, neutral, and negative comments labeled using Distilbert model. To show popular used words within the comments in Fig 4c a word cloud offers a visual representation, where the size of words reflects their frequency in the comments.
Conclusions
Recent artificial intelligence tools will have an impact on sentiment analysis and emotion research. In this paper the possibilities of LLM use for sentiment analysis was evaluated. In particular, the textual analysis of feedback from students at the end-course. This paper reveals that LLMs are not only competent in sentiment analysis but that can be used to support key tasks such as textual analysis of student feedback and provide to teachers a preliminary analysis.
Future work includes conducting aspect-level analysis, refining the software prototype, integrating a generative LLM model capable of providing directives to teachers based on student feedback and, to integrating LLM models to the Student Evaluation of Teaching (SET) system.

