











 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
INTRODUCTION
High-performance computing (HPC) is the concept that encompasses the principles, methods, and techniques that allow to address problems with complex computer structures, and of high requirements. The solution to those problems involves massive data sets, a large amount of variables, and complex calculation processes, which require efficient application of modern parallel computation tools [1]. In addition, the scientific challenges arising in engineering, geophysics, bioinformatics, and other types of applications of intensive computational use, require ever-higher amounts of computational calculations [2].
High-performance computing systems have shown exponential growth in computational power in recent decades, and this is due mainly to the evolution of microprocessor technology [3]. Large HPC systems are dominated by processors using mainly x86 and Power instruction sets, supplied by three providers: Intel, AMD, and IBM [3]. Performance of HPC systems has increased continuously with advances of Moore's Law and parallel processing, while energy efficiency could be considered a secondary problem [4]. By 2000, hardware manufacturers improved their processors' performance by adding optimization technology, like bifurcation prediction, predictive execution, and increased cache size, besides making the clock frequency faster. However, the downside of this situation was increased energy consumption, which obligated manufacturers to add multiple nuclei in a processor to avoid having problems due to overheating [3]. According to the aforementioned, it was clear that energy consumption was the dominant parameter in the scaling challenges to achieve better performance. It is widely accepted that future HPC systems will be limited by their energy consumption [2], and thermal problems [5]. Improvement is required in energy efficiency to achieve exascale computing (1018 FLOPS) [4-5].
Using concepts of integrated technologies, like systems on a chip (SoC, System-on-Chip), have emerged naturally to address the problem of energy consumption. The first prototypes were studied based on a vast number of microprocessors of many low-power nuclei instead of rapid complex nuclei, to comply with HPC and power consumption demands. In addition, recent progress and the availability of 64-bit Advanced RISC Machine (ARM) nuclei open new expectations for cluster development [4].
One way to address this problem of energy consumption is to replace the central processing units (CPU) of high-end servers with the low-power processors traditionally found in embedded systems. The use of integrated processors in clusters is not new: Diverse BlueGene machines use integrated PowerPC chips [7]. Likewise, low-power processors, which were originally destined for mobile devices, have had enormous improvement with respect to their computational power. Low-power modern processors, like the most recent ARM designs, provide great performance in relation to their low energy consumption. Today, most mobile devices are themselves small supercomputers, which supply computing power due to multiple processors and sophisticated graphic processors, while maintaining the low energy consumption that is necessary for mobile applications [5].
Implementation of HPC platforms is a costly undertaking, which may be inaccessible for small and medium institutions. Projects like Mont-Blanc [http://www.montblanc-project.eu/] and COSA (Computing on SoC Architectures, http://www.cosa-project.it/) [8] have successfully demonstrated the use of SoC-based clusters for HPC systems, but the need still exists to analyze their viability. The principal deficiencies of the current evaluations of these systems are the lack of detailed information on the performance levels in distributed systems, and the comparative evaluation in large-scale applications [9].
This work analyzed publications in the area of clusters of Systems on a Chip for high-performance computing. Inspired on the PRISMA Declaration, a search and selection of investigations was conducted. Similarly, a systematic review was carried out to learn of the evaluations made of these types of systems in the research setting. This evaluation does not compare the systems to each other, since each application has its own characteristics and different configurations, which does not make it appropriate to know which is better or worse at the performance level. Likewise, it is highlighted that the objective of this article is to know the type of evaluations carried out on Systems on a Chip for high-performance computing.
1. METHODOLOGY
The search and systematic review used an adaptation of the PRISMA Declaration, which sought to help the authors to improve the presentation of the systematic reviews [10]. The PRISMA Declaration consists of a 27-item checklist and a four-phase flow diagram, which are the methodological route to conduct the search and systematic review. Additionally, PRISMA can be useful for the critical evaluation of published systematic reviews [11]. The following sections will present the results of the search process and systematic review. Based on the PRISMA Declaration, we first defined the theme or problem to analyze and then formulated three research questions, which are the base of the search criteria and selection of the bibliography review.
2. RESULTS
This work sought to identify what types of performance evaluations have been conducted on clusters based on systems on a chip for high-performance computing. Hence, it is important to know what hardware, benchmarks, and measurement parameters have been used in implementing these types of systems.
Specifically, three questions focused on the recognition of the performance evaluations mentioned were formulated, to allow concentration in the search of the bibliography review.
2.1 Search sources
According to the research questions, a set of search sources was defined, which include IEEE Xplore Digital Library (Institute of Electrical and Electronics Engineers), Science Direct, Engineering Village, and Google Scholar, which contain published scientific bibliography according to the theme of interest.
2.2 Search criteria
In line with the search sources, the study created the permitted criteria to carry out the bibliography review according to terminology employed by experts in high-performance computing. General criteria, like date range, expressions of interest, languages selected, and expressions not permitted are listed ahead:
Study period: 2010 onwards.
Languages: Spanish and English.
Expressions:
Expressions not permitted (the word SoC captures too much information that does not belong to the study theme):
Measurement in SoC
Benchmark in SoC
With these terms defined, a search chain has been specified that includes adequate terminology according to the functioning of the databases (figure 1).

Additionally, the study defined the exclusion criteria of the works related:
2.3 Systematic Review Resu lts
Specifically, the information of interest, upon obtaining the publications selected, was based on evaluation strategies and tools, types of tests, and results of evaluations for clusters based on systems on a chip for high-performance computing. Table 1 shows the amount of works found, excluded, and selected from each source consulted to be analyzed in this review.
Table 1 Amount of Publications per Each Research Source
| Source | Amount of Works | Excluded | Final amount of works |
|---|---|---|---|
| IEEE | 36 | 25 | 11 |
| Science Direct | 17 | 14 | 3 |
| Engineering Village | 61 | 59 | 2 |
| Google Scholar | 30 | 27 | 3 |
| Total | 144 | 125 | 19 |
Source: Prepared by the authors.
According to the PRISMA Declaration, 144 studies were identified in the "Identification'" phase, of which 40 publications duplicated in the different databases were manually excluded, thus, leaving 104 studies, which make up the "Screening" phase of the Prisma model. The "Eligibility" phase excluded 75 more publications and studies that did not contain the requirements according to the inclusion and exclusion criteria initially expressed. This analysis was first conducted by the title, followed by the abstract, and the contents of the evaluation methodologies. Finally, these 29 documents were analyzed in depth, finding that 10 of the publications contained evaluations of devices with emphasis on computer networks, which is not part of the respective analysis, thereby, considering the 19 studies that finally complied with all the criteria and the emphasis required, and which were selected to be part of this systematic review. The phases of the methodology, as well as the number of publications worked in each of them, can be observed in figure 2.

2.4 Statistical information
The following presents the statistical data on the studies selected, from a general vision of the information analyzed in the evaluation of clusters based on systems on a chip for high-performance computing. Table 2 summarizes the data collected.

According to the information illustrated in figure 3, the date range of the publications selected is between 2012 and 2017; bear in mind that the study consultation began in 2010.

The origin of the publications included in the review can be seen in figure 4. These publications are concentrated in three continents, America, Asia, and Europe, with Europe having the highest percentage of publications on the theme selected with 52 % of all the studies. It should be noted that Spain was the European country with the highest number of publications. Likewise, in the other continents, The United States, Brazil, and Thailand had the highest participation (figure 5).
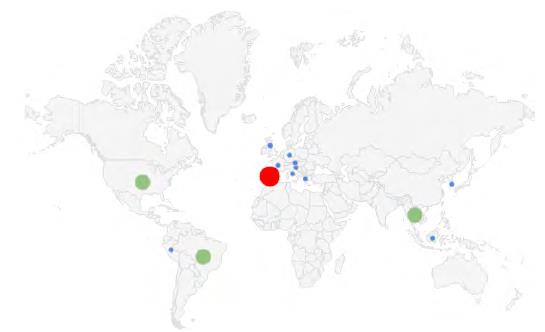

According to the country of origin of the publications studied, three institutions stand out in Europe: The Supercomputing Center in Barcelona, the Department of Computer Architecture at Universidad Politécnica de Catalunya, and Cambridge University in the United Kingdom, which had a higher number of studies on the theme of the systematic review.
Consequently, from the northern region of the American continent the study obtained greater information from institutions like the University of Maine in Orono, the City University of New York Graduate Center and the City College of the City of New York, and the University of Oklahoma in The United States. Additionally, in the southern region of the American continent some of the investigations were presented by Pontificia Universidade Católica Minas Gerais, and Universidade Federal de Santa Catarina in Brazil. Furthermore, the Asian continent was represented by institutions like the College of Computer Engineering, and the Suranaree University of Technology in Nakhon Ratchasima Province in Thailand.
2.5 Answering the Research Questions
According to the questions initially made, which were focused on recognizing the performance evaluations of the clusters based on systems on a chip for high-performance computing, it was possible to extract information that answers the three research questions.
The initial question corresponded to the inquiry: What type of devices were used in the investigations consulted? Regarding the technology used in the studies analyzed, it was found that the Raspberry, Odroid and Nvidia systems are the most representative, according to the selection made in the bibliography review. These technologies represent 58.2 % of all the technologies used, according to figure 6.
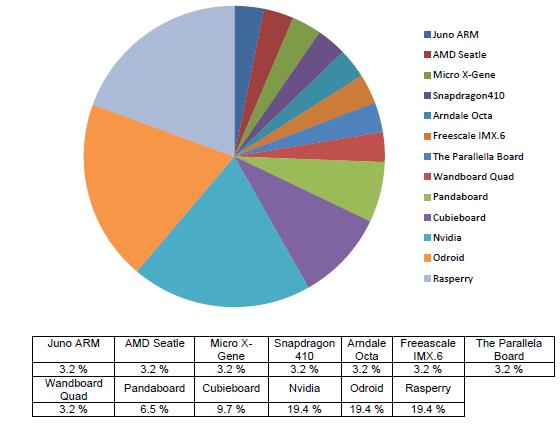
Source: Prepared by the authors.
Figure 6 Technology Used in the Publications of Clusters of Systems on a Chip
Each of these systems represented 19.4 %. The remaining percentage focused on systems like Juno ARM, AMD SeattleMicro X-Gene, Snapdragon 410, Arndale Octa, Freescale IMX.6, The Parallella Board, Wandboard Quad, Pandaboard, and Cubieboard.
The second question referred to What tests or benchmarks were implemented to measure cluster performance. As a result of the review, approximately 25 different performance tests were found (figure 7), highlighting the High Performance Linpack (HPL), Stream, and NAS Parallel Benchmarks tests.

Finally, the third question asked What other parameters were kept in mind to conduct the evaluations. To answer this question, it was established that the benchmarks currently used are standardized, and the measurement parameters are already identified for the comparisons made to be measured under the same conditions. Hence, no additional parameters were evidenced from those specified in the performance tests.
DISCUSSION
As stated, cutting-edge HPC systems have high-energy consumption, which has motivated the community to seek strategies aimed at reducing energy consumption while offering high performance. These strategies use diverse forms of evaluating these systems to demonstrate their performance and reduction of energy consumption. These evaluations, methodologically speaking, are known as performance tests or benchmarks.
In the field of HPC, benchmarks appear during the stages of development of the clusters, including the design, implementation, and maintenance, seeking to estimate, evaluate, and ensure the effectiveness of the system [23]. Benchmarks help to quantify the capacity of HPC systems. The result of the benchmarks is that of finding the suitability of a given architecture for a selection of computer applications. Said measurements must be based on real computer applications, and on a comparative and consistent evaluation process [24].
Because of the review, it was possible to identify that the most relevant performance tests in the field of HPC are High-Performance Linpack (HPL), Stream, and NAS Parallel Benchmarks.
The HPL is an implementation of the Linpack benchmark, developed specifically to be executed in architectures that provide support to the parallel-distributed processing. Likewise, it is used to measure the performance of a high-performance computer and is currently used by the Top500 and Green500 to compile their rankings. The HPL is based on the resolution of dense linear systems (generated randomly) from double-precision equations (64 bits), over a system with distributed memory [25]. The HPL provides programs to evaluate the numerical precision of the results and the time of resolution. The reported performance value depends on diverse factors, but under certain efficiency assumptions of the intercommunication network; the HPL resolution algorithm may be considered scalable, and its efficiency is maintained constant with respect to the memory used by each processor. Execution of HPL requires an implementation of MPI distributed memory and the BLAS library. The unit to present the HPL results is Flops [15].
STREAM is a benchmark that permits evaluating the efficiency of access to the principal memory through four operations over vectors and it is the standard industry benchmark to measure a system's memory bandwidth and the computation rhythm of simple vectors. The program runs four copy, scale, add, and triad operations of floating-point values over large matrices to calculate the memory bandwidth obtained in each operation in MB/s. Table 3 shows the number of flops and bytes counted every loop iteration [3].
Table 3 Operations of the STREAM benchmark
| Operation | Instructions | Per iteration | |
|---|---|---|---|
| bytes | Flops | ||
| COPY | a(i)= b(i) | 16 | 0 |
| SCALE | a(i)=q* b(i) | 16 | 1 |
| SUM | a(i)=b(i)+ c(i) | 24 | 1 |
| TRIAD | a(i)=b(i)+ q*c(i) | 24 | 3 |
Source: [3].
The "NAS Parallel Benchmarks" suite is a project developed by the NASA Advanced Supercomputing (NAS) Division to evaluate the performance of highly parallel computing in supercomputers. The benchmark derives from Computational Fluid Dynamics (CFD) applications, and consists of five kernels and three pseudo-applications. Currently, NAS Benchmarks comprise 11 benchmarks, of which eight were originally available in the NPB 1 version: MultiGrid (MG), Conjugate Gradient (CG), Fast Fourier Transform (FT), Integer Sort (IS), Embarrassingly Parallel (EP), Block Tridiagonal (BT), Scalar Pentadiagonal (SP), and Lower-Upper symmetric Gauss-Seidel (LU); and three other benchmarks available from version NPB 3.1 and NPB 3.2: Unstructured Adaptive (UA), Data Cube Operator (DC), and Data Traffic (DT) [3].
According to the benchmarks presented and the works studied, these three performance tests are robust tools to evaluate cluster systems based on SoC for HPC.
To implement these tests, it is necessary to conduct a specific study in each of these tools to obtain standardized results that are comparable with the related literature.
In most of the works analyzed, it was found that the evaluation conducted made possible to know the performance and power consumed by the clusters. Performance was mainly evaluated by using performance tests already named. Power consumption is a determinant factor in HPC systems based on SoC, given that the number of instructions executed per watt consumed are related, with this being a currently recognized parameter, which was previously not relevant for the construction of clusters for HPC.
Additionally, it must be highlighted that referent measurements exist to evaluate this technology, like the Top500 and Green500 lists [26]. The former classifies supercomputers according to the performance of instructions in floating point, while the latter classifies the most energy efficient supercomputers.
The Top500 list does not have as criterion to classify big machines according to energy consumption, although it is a parameter that has always been measured. The Green500 list calculates the performance of the cluster, and captures the power consumed by the cluster during the execution of the performance tests. Thereafter, performance per watt is determined by using the following formula: Performance per watt (PPW) = Performance/power [3].
It should be stressed that when designing an HPC cluster, the main goal is to obtain a hardware configuration that offers good results in the application or sets of applications. This hardware will be evaluated through performance tests that will allow to know the efficiency of these systems. These tests must be conducted with standard benchmarks for their results to be comparable.
4. CONCLUSIONS
This work presented a systematic review of the evaluations conducted on clusters of Systems on a chip for high-performance computing, using elements from the Prisma Declaration. The Declaration made possible to establish a methodological route to carry out the search and systematic review of the bibliography consulted.
As a result of the review, it was found that the performance tests most used were: High-Performance Linpack (HPL), NAS Parallel Benchmarks, and STREAM benchmark. These tests are the best known in HPC, given that they introduce standard results, which permit using comparatives. Likewise, the hardware most used were the Raspberry, Odroid, and Nvidia systems.

