











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
INTRODUCCIÓN
Los bosques son los reservorios de la diversidad biológica más importante del planeta debido a que sirven de hábitats para plantas, animales y microorganismos; estos se definen formalmente como “tierras que se extienden por más de 0.5 ha, dotadas de árboles de una altura superior a los 5 m, con una cubierta de dosel mayor al 10%, o de árboles capaces de alcanzar esta altura in situ”, y se categorizan en bosques primarios y secundarios (FAO, 2010, p. 217). Los bosques primarios están compuestos de especies autóctonas cuya característica principal radica en presentar dinámicas forestales naturales, estructuras disetáneas y procesos naturales de regeneración, y no evidencian intervenciones significativas de origen antrópico. En contraposición, los bosques secundarios presentan como rasgo común “el disturbio o perturbación al ecosistema, pudiendo ser causado u originado naturalmente, o bien por el hombre como actor principal” (Smith et al., 1997, p. 2).
De igual forma, se presentan otras clases de bosques como los “Bosques Periurbanos”, que corresponden a sistemas boscosos o grupos de árboles individuales ubicados en las periferias de las ciudades (FAO, 2016) y que cumplen con una función de amortiguamiento y transición entre las zonas urbanas y las rurales (Douglas, 2005). Es importante resaltar que estos bosques son áreas susceptibles o vulnerables a altos niveles de perturbación de origen antrópico (Torres y Pérez, 2008).
Ahora bien, Li y Zhang (2007) manifiestan que el estudio del patrón espacial genera información esencial, pues representa de forma estadística una variedad de procesos físicos-ecológicos en los bosques, como la competencia, variabilidad, distribución del tamaño, entre otros. Conforme a esto, Penttinen y Stoyan (2000) señalan que el estudio del patrón espacial y sus características son herramientas valiosas para los análisis de datos exploratorios en silvicultura con el fin de describir la variabilidad de las masas forestales. Por tanto, para un análisis de la diversidad biológica es útil el estudio del patrón espacial de las interacciones de individuos en comunidades ecológicas que permitan revelar las correlaciones locales de estos y su comportamiento (Murrell y Law, 2003). Al respecto, Olaya (2014) indica que, para poder efectuar un análisis de este tipo, debe disponerse en cada una de las observaciones de los eventos (en este caso, los árboles) de una coordenada asociada, lo que aporta una información adicional más minuciosa del fenómeno. Así, la distribución espacial de especies ha sido extensamente estudiada en diversos ecosistemas (Fisher et al., 2007; Isaacs, 2011; Linares-Palomino, 2005; Rozas y Camarero, 2005) donde se han aplicado técnicas de análisis estadístico de carácter espacial, como la función K de Ripley, los patrones de puntos marcados, el análisis de cuadrantes, el test Kolmogorov-Smirnov (K-S), el I de Moran y el LISA, con la idea de conocer cómo se comportan las especies animales y vegetales dentro de ecosistemas particulares.
En el caso de los bosques periurbanos de la ciudad de Mérida (Venezuela), estos fueron estudiados previamente por Rodríguez (2015), quien analizó su estructura y composición florística, tomando como referencia varios puntos entre los 1 700 y 2 400 m de altitud. Como resultado, logró diferenciar claramente bosques maduros y sucesionales existentes en el área de estudio que le permitieron escoger -bajo criterios florísticos y ecológicos- los sitios idóneos para el establecimiento de las parcelas a levantar. El autor reportó 102 especies, pertenecientes a 44 familias y 70 géneros, incluyendo dos indeterminadas; 76 especies en los bosques maduros y 50 especies en los sucesionales.
Sin embargo, el autor no consideró en su análisis el elemento de distribución espacial interna de cada parcela, por lo que se desconocen las interacciones de los individuos y su estructura y diferenciación espacial entre las categorías de bosques analizados. Por consiguiente, la pregunta a ser considerada en esta investigación fue: ¿los patrones espaciales de los bosques primarios y secundarios son estadísticamente iguales? De aquí surge la necesidad de estudiar la distribución espacial de los individuos y sus implicaciones en el análisis de los procesos de intervención en los bosques, y la razón por la cual se realizó el presente trabajo, poniendo el foco de la investigación forestal en los bosques periurbanos, aplicando técnicas de patrones puntuales en parcelas establecidas en la ciudad de Mérida (Venezuela).
El hecho de concederle características espaciales a fenómenos ecológicos naturales puede abordarse desde distintas aproximaciones de estadística espacial (Cressie, 1993; de la Cruz Rot, 2006); entre ellas, se puede encontrar los patrones o procesos puntuales que se definen formalmente como un proceso espacial con localizaciones de eventos {Z(s): s ∈ D}, donde Z(∙) eventos son aleatorios en el espacio D y cuyo proceso puede ser discreto o continuo (Cressie, 1993; Giraldo, 2009). Cabe indicar que el proceso más simple es el de Aleatoriedad Espacial Completa (también conocido como Poisson Homogéneo -CSR-), es decir, la ubicación espacial de los eventos no tiene influencia sobre el proceso estocástico (Baddeley, 2008; Cressie, 1993). Por el contrario, existen otros patrones cuyo comportamiento de la función de densidad espacial no es aleatoria e independiente (Legendre y Legendre, 1998; Lloyd, 2010), pues a diferencia de las técnicas geoestadísticas y los análisis de datos de áreas, los patrones puntuales parten del hecho de que el conjunto de los eventos son aleatorios; en otras palabras, la decisión respecto de donde se hace la medición no depende del investigador, ya que el evento se mide en donde ocurre y no donde el usuario desea (de la Cruz Rot, 2006), mientras que las preguntas de interés en un proceso de distribución espacial se centran en si los eventos se comportan de una forma más o menos agregada o regular de lo que se esperaría (Baddeley, 2008; Legendre y Legendre, 1998; Lloyd, 2010).
MATERIALES Y MÉTODOS
Los datos de campo fueron recolectados por Rodríguez (2015) en los bosques de la zona norte de la ciudad de Mérida (Venezuela), entre los 1700 m y 2400 m de altitud (Figura 1). Los sitios se encuentran ubicados entre las unidades ecológicas de la Selva Semicaducifolia Montana y la Selva Nublada Montana Baja, donde las temperaturas medias anuales oscilan entre los 13 °C a 18 °C (Ataroff y Sarmiento, 2004), con una precipitación media anual aproximada de 1800 mm (López, 1976). Estos lugares se caracterizan por sus comunidades boscosas densas, compuestas por árboles entre los 10 m y 20 m de alto, con elevado epifitismo, y donde abundan los helechos, musgos, hepáticas, orquídeas y bromelias (Rodríguez et al., 2010).
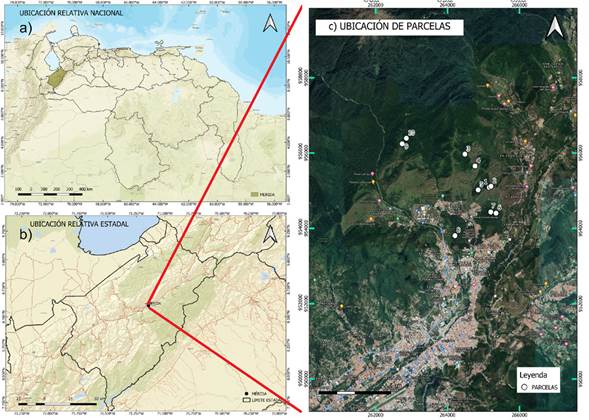
Figura 1 Ubicación del área de estudio de los bosques periurbanos de Mérida, Venezuela: (a) relativa nacional, (b) relativa estadal y (c) ubicación de las parcelas.
En esta área Rodríguez (2015) estableció diez unidades muestrales (parcelas), cinco en zonas aparentemente no intervenidas (bosques primarios; parcelas 1, 2, 3, 9 y 10) y cinco en bosques secundarios (parcelas 4, 5, 6, 7 y 8); las unidades muestrales se establecieron mediante varios recorridos y visitas de campo, y por medio de los análisis prospectivos se determinó el estado sucesional de los bosques. Cada una de las parcelas estuvo conformada por franjas de 50 m de largo por 10 m de ancho, 5 m a cada lado de su línea central, y para cada unidad muestral se seleccionó un fragmento representativo de cada tipo de bosque con el fin de elaborar un perfil estructural (vertical y horizontal) de vegetación de acuerdo al método de Richards (1983). Así, se elaboró un perfil estructural a partir de un tramo de 50 m x 5 m. El levantamiento de los datos para el perfil incluyó: la ubicación o posición del individuo (coordenadas x, y), el DAP de todos los individuos ≥ 2.5 cm, la altura total (m), el volumen (m3) y la especie. Para la ubicación de los árboles en la parcela se estableció un plano de coordenadas, siendo el eje X la franja central de 50 m de la parcela y el eje Y uno de los bordes de 5 m; además, a cada árbol dentro de la parcela de 50 m x 5 m se le determinó su posición (X, Y) respecto a los ejes.
Es importante acotar que no se pudo efectuar una corrección de posición de los individuos por pendiente, ya que no se disponían los datos altitudinales de alta precisión para realizar dicho procedimiento.
Con relación al análisis de la distribución espacial en cada una de las parcelas se asumió una condición de un proceso estocástico de patrón de punto: {Z(s): s ∈ D}, donde s ∈ ℝ d representa una ubicación en el espacio euclidiano d-dimensional, Z(s) es una variable aleatoria en la ubicación s y s varía sobre un conjunto de índices D ⊂ ℝ d ; Z(∙) y D son aleatorios (CSR). Este proceso es la hipótesis nula planteada en esta investigación (Cressie, 1993; Giraldo, 2009). Para contrastar dicha hipótesis estadística se aplicaron técnicas correspondientes a patrones de puntos, como lo son: la función K Ripley, el análisis de los Cuadrantes y el test de Kolmogorov-Smirnov (K-S) (Acevedo, 2013; Dale y Fortin, 2014) (α = 0.05). Y para el análisis de patrones puntuales se aplicó lo determinado por Pélissier (1998), Penttinen y Stoyan (2000) y Li y Zhang (2007): si se desea probar la intensidad espacial de los árboles de cada parcela (ind.m-2) y el rango de la estructura espacial de las parcelas (interacciones entre los individuos), se parte del supuesto de que se realizó un mapeo exhaustivo de todos los eventos (Dale y Fortin, 2014). El análisis de los patrones puntuales fue realizado con el software libre R (R Core Team, 2014) en las librerías Rcmdr (Fox, 2005, 2017; Fox y Bouchet-Valat, 2018), Maptools (Bivand et al., 2013) y Spatstat (Baddeley et al., 2016), y se realizó un pre-procesamiento con el propósito de convertir cada una de las parcelas en bases de datos espaciales de formato Shapefile -para ello se utilizó el software libre de Sistemas de Información Geográfica Qgis (Lacaze et al., 2018)-.
Por un lado, se aplicó la función K de Ripley, que es utilizada para describir la relación entre cada uno de los eventos localizados en un área predeterminada; su estimador es / donde N es el número de puntos del patrón, A la superficie del área de estudio e I (d ij < r) la función indicadora, que toma el valor de 1 si la distancia entre los puntos i y j es menor que r, y 0 en el caso contrario (de la Cruz Rot, 2006; Dixon, 2002; Lloyd, 2010). Por otro lado, para corregir el efecto de borde y aquellos puntos situados cerca de la frontera de la zona de estudio se utilizó el estimador /, donde el valor w ij pondera los distintos puntos en función de su distancia al borde de la zona de estudio. Es importante resaltar que la función K de Ripley trata de incorporar la escala como una variable más del análisis, convirtiendo dicha dependencia en un hecho favorable en lugar de una desventaja (Olaya, 2014; Ripley, 1977, 1988); ello implica que este test no debe verse específicamente como una prueba de hipótesis, sino como una prueba de hipótesis aplicada para distintas escalas o distancias de análisis. Por su parte, Baddeley (2008) y Baddeley et al. (2010) reseñan que el test Kolmogorov-Smirnov (K-S) es una prueba eficaz que permite comparar las distribuciones observadas y esperadas de los valores de una función t-Student con base en una distribución empírica (ECDF) de la forma: E n - n(i)/N, donde n(i) es el número de puntos menor que Y i ordenados de menor a mayor (este test asume que los datos siguen un proceso CSR, determinado por el usuario).
Así mismo, se analizaron los patrones puntuales marcados (marcas), es decir, cuando los puntos se diferencian unos de otros por alguna cualidad (especie, altura total, DAP y volumen) se emplean técnicas para el análisis de patrones marcados (de la Cruz Rot, 2008). En este sentido, se utilizó la función K descrita anteriormente, con modificaciones que incluyeron la ponderación del efecto que causa la inclusión de una variable y comparándolo con el efecto que tiene la misma sobre la función K, sin la inclusión de la variable de interés. En este caso la hipótesis nula es: el patrón de las entidades ponderadas por las variables no está significativamente más agrupado que el patrón subyacente de esas entidades; y para ello sólo se utilizaron las variables: especie, DAP (m), altura total y volumen de cada uno de los individuos, siendo el estimador de la función K ponderada con marcas: kmm(r) = E 0(∑ [xn, mx] m(x 0)m(x n ) 1(0<||x n - x 0|| ≤ r))/λμ 2 m , r>0, donde N m es el patrón marcado, x n y m(x n ) son un punto cualquiera y su marca, λ es la intensidad del patrón y μ m el valor medio de las marcas del patrón (de la Cruz Rot, 2008; Stoyan y Stoyan, 1994). Adicionalmente, con fines de mapear la densidad de cada una de las parcelas, se generaron los contornos de densidad espacial utilizando un núcleo gaussiano y cuya expresión es: k(h) = (1-h 2/r 2)2⩝h≤r, donde h es la distancia al punto y r el radio máximo de influencia (Olaya, 2014).
Una pregunta a ser considerada en este tipo de análisis fue: ¿los patrones espaciales de los bosques primarios y secundarios son estadísticamente iguales? Para responderla se aplicó la hipótesis del etiquetado aleatorio, en la que cada patrón individual sería una muestra aleatoria del patrón total y, por lo tanto, debido a la naturaleza de la función K: K(r) BP, P1 = K(r) BP, P2 = K(r) BP, P3 = K(r) BP, P4 ... = K(r) BP, P10 = K(r) donde la hipótesis alternativa es la diferencia entre pares de funciones K, es decir, K(r) BP - K(r) BS , se evalúa si un patrón está más o menos agrupado que el otro (y a qué escala); mientras que en: K(r) BP, P1 = K(r) BP, P2 ; K(r) BP, P1 - K(r) BP, P3 ... se estima la segregación de los procesos, permitiendo así comprobar si un tipo de patrón de punto tiende a estar rodeado por otros del mismo tipo (de la Cruz Rot, 2008).
Para probar estas hipótesis se aplicaron las funciones: K-cruzada y L-cruzada, que corresponden con generalizaciones de la función K y L aplicando una aproximación de patrones de puntos multi tipo, de tipo categórico univariado. La función K-cruzada es: K ij (r) = λ j K ij (r), donde K ij (r) es la función K-cruzada y λ j es la intensidad del patrón de tipo "j", que proporciona el número medio de puntos de tipo "j" dentro de un radio r alrededor de cualquier punto de tipo "i". De igual manera, se aplicó la función L-cruzada: L * 12(r) = (K * 12(r)/π)1/2 (de la Cruz Rot, 2008; Diggle, 1983; Harkness e Isham, 1983), así como la función multivariada I, cuyo estimador es I(y) = ∑ m i=1 p i J ii (y) - J(y), J ii (y), donde J es la función del patrón de tipo i y p i su abundancia relativa, es decir, J(y) es la función J del patrón total ignorando las marcas de cada tipo; si las categorías son independientes entonces I (y) = 0, y si las desviaciones de I(y) < 1 y I(y) > 1 indican asociación negativa o positiva respectivamente (van Lieshout y Baddeley, 1996, 1999). Finalmente, se aplicó la función K-múltiple -que corresponde con una generalización de la función K-, analizada para patrones de puntos marcados arbitrariamente. Aquí se supone que x i , x j son subconjuntos, posiblemente superpuestos, de un proceso de punto marcado, por lo que la función K-múltiple λ j K ij (r) es igual al número esperado de puntos aleatorios adicionales de x j dentro de una distancia r de un punto típico de x i , mientras que λ j es la intensidad de x j , siendo esta intensidad la esperada para una cantidad de puntos de x j por unidad de área (Diggle, 1983, 1986; Harkness e Isham, 1983; Lotwick y Silverman, 1982).
RESULTADOS
Los resultados obtenidos del análisis de las parcelas establecidas en ambos tipos de bosques manifiestan un proceso CSR, ya que la función K de Ripley sin marcas se encuentra dentro de los intervalos de confianza de la hipótesis nula (color gris) a lo largo de la distancia establecida la distancia r (Figuras 2a y 2b).
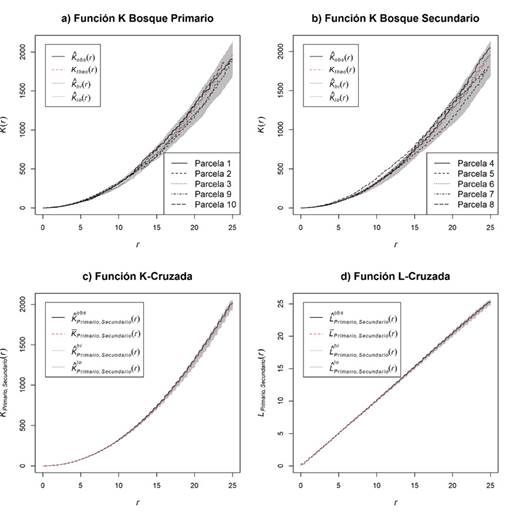
Figura 2 Comparación de parámetros espaciales entre tipos de bosques periurbanos de Mérida, Venezuela. Función K: (a) primario y (b) secundario, (c) Función K-Cruzada y (d) Función L-Cruzada.
Estos resultados son refrendados por la figura de densidad espacial, donde los colores rojos, indican la presencia de una concentración mayor de individuos por unidad de superficie; esto se refleja en lo obtenido en la parcela 4, la cual es del tipo representativo de bosque secundario, mientras que la parcela 1 (de bosque primario) posee una densidad superior que la parcela de bosque secundario (Figura 3); estos resultados concuerdan con los obtenidos por Montañez Montañez Valencia et al. (2010) quienes reportaron una tendencia al incremento del gregarismo proporcional a la escala espacial en el estrato arbóreo, no obstante, en el sotobosque el grado de agrupamiento de las especies disminuyó a medida que aumentó la escala de análisis.
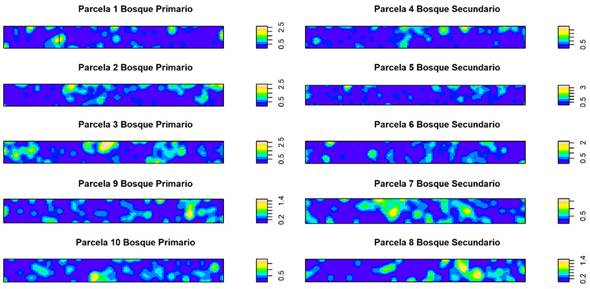
Figura 3 Comparación de parámetros espaciales (Densidad) entre bosque primario y bosque secundario. En parcelas de bosques periurbanos de Mérida, Venezuela.
Entretanto, los resultados obtenidos por la función K-cruzada y L-cruzada, generan como consecuencia, que no se tiene evidencia suficiente para rechazar la hipótesis nula de igualdad de los patrones espaciales de los bosques primarios y secundarios (Figuras 2c y 2d); esto es refrendado por el Test del análisis de Cuadrantes y el Test K-S, donde solamente para las parcelas 4 y 8 (de bosque secundario) y 2 (de bosque primario) se obtuvo evidencia suficiente para rechazar la hipótesis nula de un proceso CSR. Adicionalmente, estos análisis reportan 407 individuos (53%) en la categoría bosque primario y 367 para la categoría secundario (47%), siendo lo más relevante la intensidad de los árboles por unidad de superficie, ya que la media de las intensidades de individuos es ligeramente mayor en el bosque primario (0.33 ind.m-2) que en las parcelas de bosque secundario (0.31 ind.m-2), las cuales podrían deberse a errores de conteo en campo. Dado que la densidad media de ambos bosques es prácticamente la misma (3 100-3 200 arb.ha-1), únicamente incrementando suficientemente el tamaño de la muestra se podría alcanzar a rechazar la hipótesis de igualdad de medias, o bien utilizando un nivel de significancia α muy superior al 5%.
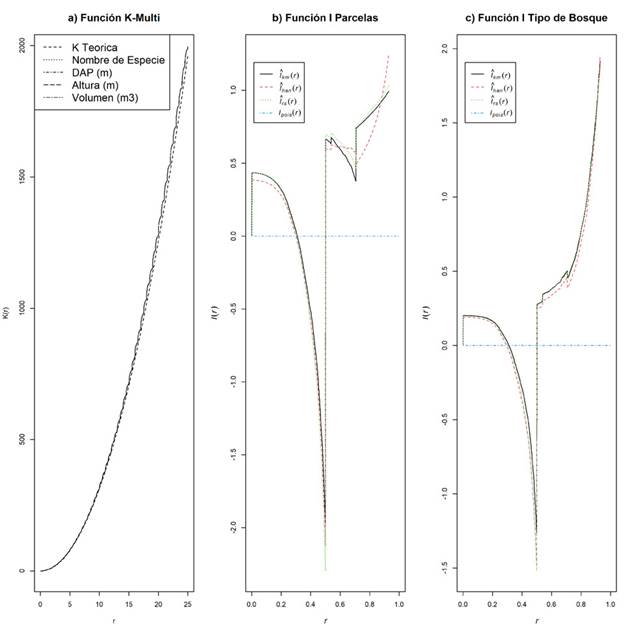
Con la Función K sin marcas se obtuvo una línea base que indica el proceso que sigue los árboles de cada parcela sin involucrar una covariable, esto permitió comparar la línea base con los resultados ponderados por las variables en la función K con marcas (Baddeley, 2008; Baddeley et al., 2016), por tanto, se obtuvo el efecto que tienen las mismas sobre la distribución espacial de los árboles. El proceso que involucra las marcas manifiesta un mismo comportamiento CSR para las variables DAP y altura, con lo cual no existe suficiente evidencia para rechazar la hipótesis nula CSR para estas variables, no obstante, cuando se incluye la variable especie para ambos tipos de bosque cambia de agrupado hasta los cinco metros, esto implica que una misma especie tiende a mostrar agrupación en un radio de 5 m, antagónicamente, a partir de esta distancia el proceso espacial se convierte en regular. En tanto para el volumen, el proceso para el bosque secundario oscila cada cinco metros de agrupado a regular, mientras que para el bosque primario se genera un proceso exclusivamente de tipo regular (Figura 4). Finalmente, los resultados de la prueba K-múltiple manifiestan un proceso CSR para las marcas entre todas las escalas que tiende a generar diferencias cuando se trata de largas distancias (Figura 5a); pero, los resultados de la función I para las parcelas y para los tipos de bosques, indican que el proceso tiende a ser asociación negativa hasta 1 m en el caso de las parcelas y en el tipo de bosque hasta 0.8 m (Figuras 5b y 5c). Nótese que las diferentes curvas corresponden con el comportamiento de distintos estimadores de la función para un radio r, rs es el estimador de "muestra reducida" o "corrección de fronteras" de l(r) calculado a partir de las estimaciones corregidas de fronteras de las funciones J, km el estimador espacial de Kaplan-Meier de i(r) calculado a partir de las estimaciones de Kaplan-Meier de las funciones J; han es el estimador de estilo Hanisch de l(r) calculado a partir de las estimaciones de estilo Hanisch de las funciones J; un es la estimación no corregida de l(r) y theo el valor teórico de l(r) para un proceso de Poisson estacionario: idénticamente igual a 0 (Baddeley et al., 2016).

Figura 4 Función K con marcas, bosque primario y bosque secundario. En parcelas de bosques periurbanos de Mérida, Venezuela.
DISCUSIÓN
Con base en estos resultados entran en discusión las afirmaciones de Ledo et al. (2012), quienes indican que la estructura horizontal en una masa forestal viene determinada -teóricamente- por la distribución en el espacio de los árboles o patrón espacial, donde cada uno de los patrones observados revela una historia forestal distinta. En efecto, esta “fotografía” responde a unas causas (Legendre, 1993) y también genera ciertas consecuencias (Halpern y Spies, 1995). Por esta razón, afirmaciones como las de Guariguata y Kattan (2002) y Linares-Palomino (2005) señalan que los patrones de distribución de las especies se ven significativamente afectados a diferentes niveles de perturbación, puesto que estos eventos representan oportunidades de fragmentación en los ecosistemas. De esta manera, en el caso de ecosistemas no intervenidos, los sucesos deberían estar teóricamente aglomerados a mayores niveles; por el contrario, cuando hay aleatoriedad, indican la presencia de intervención. En contraposición, de La Cruz Rot (2006) plantea que la hipótesis nula para la relación entre las plantas adultas debería ser la independencia, en otras palabras, que si el bosque es maduro se debería tender a un patrón CSR. En el caso de esta investigación el no rechazo de la hipótesis nula indica que no se obtuvo suficiente evidencia para negar dicha hipótesis, por lo tanto, puede afirmarse que se está en presencia de un bosque maduro intervenido.
Como consecuencia de estas ideas contrapuestas -la caracterización del proceso sin marcas y con marcas de tipo CSR con excepción de la variable especies-, se plantearon las siguientes preguntas: i) ¿el tamaño y forma de las parcelas de trabajo es el idóneo para caracterizar la heterogeneidad ecológica desde un punto de vista espacial?; ii) con el fin de caracterizar la heterogeneidad ecológica, ¿cómo se podría determinar el tamaño y forma idóneo de las unidades de muestreo desde un contexto espacial? Para responder ambas preguntas se debe partir, al menos de forma exploratoria, del conocimiento sobre la estructura de la covarianza espacial (Skøien y Blöschl, 2006). Por otra parte, la determinación de la distribución espacial de especies (tanto vegetales como animales) a simple vista puede generar una mala interpretación, dando como consecuencia datos sesgados que conlleven a la aplicación inadecuada de técnicas de manejo y conclusiones erradas (de La Cruz Rot 2008). Al respecto, debe señalarse que Rodríguez (2015) inició dicho proceso exploratorio sin involucrar las coordenadas espaciales de los eventos, sin embargo, con base en los resultados obtenidos acá, puede afirmarse que, desde un contexto exclusivamente espacial, las parcelas son muy pequeñas para caracterizar el proceso. Por ello, una recomendación es identificar dos comunidades de bosques periurbanos (primarios y secundarios) en los cuales se deben levantar los individuos con coordenadas y nuevamente ejecutar las técnicas de patrones puntuales, ya que es posible que el proceso de heterogeneidad ecológica sea significativo a gran escala y, por tanto, deberían diferenciarse, pues en vez de estar trabajando entre individuos, donde los patrones de agregación tienen protagonismo a pequeña escala (Ledo et al. 2012), se representarían las dinámicas poblacionales a escala de comunidades vegetales (Hubbell, 1979). Otra posibilidad para discernir el tamaño idóneo del área de trabajo sería definir un patrón de puntos con marcas continuas (semejantes a las que se emplean en la geoestadística), ajustando un modelo exponencial o potencial; ahí se podría concluir que el área es muy pequeña para caracterizar el proceso de autocorrelación espacial (Solana-Gutiérrez y Merino-de-Miguel, 2011), aun cuando debe probarse que existe independencia entre la localización de los puntos de muestreo y el valor de las marcas (de La Cruz Rot 2008). Para el caso de los bosques tropicales, algunos suelen presentar cierta tendencia a la regularidad espacial a escalas grandes, no obstante, según se va reduciendo la escala se suele encontrar una fuerte tendencia a formar agregados (Condit et al., 2000; Lawes et al., 2008; Ledo et al. 2009; Picard et al., 2009), por lo que la caracterización del proceso como CSR es indicativo de intervenciones sobre los bosques periurbanos, ya que es más difícil saber si un bosque es primario cuando no se dispone de un bosque referencial. La escala de análisis o los criterios (estrato, diámetro, tipo funcional) para definir la población que se analiza van a influir de manera decisiva en el patrón espacial resultante, de manera especial en las masas tropicales (Pélissier, 1998), sin embargo, se requiere de un levantamiento exhaustivo de los bosques periurbanos en la ciudad de Mérida con áreas de trabajo de mayor tamaño y su respectivo análisis de distribución espacial, que por razones logísticas no pudo ser realizado en esta investigación. Adicionalmente, el proceso obtenido por la función I es indicativo de una leve competencia entre los individuos a pequeña escala.
CONCLUSIONES
Se caracterizó el proceso de tipo CSR entre ambas categorías de bosques sin marcas, así como en las variables cuantitativas. En consecuencia, se obtuvo diferencias entre los patrones de puntos marcados de las especies entre bosque primario y secundario, pero no hubo evidencia suficiente para rechazar la hipótesis nula entre la distribución espacial de las parcelas y los tipos de bosque. Una razón posible es que el bosque maduro ha sido sometido a intervenciones de origen antrópico, al tiempo que se presentaban otros factores ambientales como el relieve y la topografía que pueden incidir de manera indirecta en el patrón espacial, pero que no fueron analizadas en esta investigación. Aun así, al no haber ningún modelo estadístico con las variables exógenas espaciales involucradas, la influencia de estos factores en la ocurrencia de los individuos no es totalmente concluyente. No está demás señalar que las unidades de muestreo fueron establecidas en bosques periurbanos con mayor potencial de ser propensos a perturbaciones humanas. Igualmente, es posible realizar el modelado de las especies con el fin de establecer pronósticos de la ocurrencia de especies e individuos, entre otros, aunque si se desea incluir en el modelo covariables espaciales estas deben ser variables con una gran envergadura espacial. Finalmente, para discernir la estructura ecológica es necesario determinar dos comunidades de bosques periurbanos (uno de bosques primario y otro de secundario) bien diferenciados y efectuar un censo de árboles con coordenadas para ejecutar nuevamente la aproximación de los patrones puntuales, identificando el proceso estadístico y realizando pronósticos.

