











 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
PermalinkIntroduction
In a panorama of uncertainty and a high degree of risk in financial markets, the study of the variables affecting their dynamics is pertinent for academics and practitioners. Two of the variables that are decisive in investment analysis correspond to returns and risk. Although in the last decades, finance as a research field has made important advances in the understanding of these two elements, there is still a long way to go to decipher the logic under which markets operate globally.
Recently, one of the most important innovations in the study of finance corresponds to the use of machine learning (ML), which "refers to a class of data science models that can learn from the data and improve their performance over time. The roots of ML [go] back to the scientific community's interest in [the] 1950s and 1960s in replicating human leaning through computer programs" (Ghodussi et al. 2019, p. 709). Particularly, in the case of finance as a research area, it "at the intersection of a number of emergent and established disciplines including pattern recognition, financial econometrics, statistical computing, probabilistic programming, and dynamic programming" (Dixon et al., 2020, p. vii).
This new approach to the study of finance has gained relevance, mainly for two reasons. Firstly, recent computational advances and the spread of statistical packages such as R and Phython have allowed the wide use and estimation of previously unviable models at low costs and with reliable accurate results. Secondly, the relative abundance of financial data allows the use of ML and big data techniques in a more accessible way than in other fields of economics and management. In consequence, the studies related to ML in finance have experienced a remarkable increase in the last few years. According to data taken from the Web of Science database, in 2001, there were four articles related to the use of ML in finance, in 2010 this figure was seven, while in 2022, the number of articles related to this topic exceeded 45.
The use of ML techniques in finance has covered a wide variety of topics. For instance, applications related to price prediction, risk management, and trading strategies have grown exponentially in academic publications in recent years. However, one of the topics that received the least attention until a couple of years ago is the study of volatility. This fact is striking, considering that "Modeling volatility is both challenging and promising. The challenge is to include the concept of second-moment clustering in a standard ML model. The advantage is that volatility is not subject to market efficiency effect (i.e., volatility will not disappear as a result of prediction)" (Ghodussi et al. 2019, p. 720). This is to say that although there is greater potential in the development of models dedicated to predicting volatility, much of the financial literature has focused on predicting returns.
However, the results obtained from our exercise suggest that there is an increasing number of works related to ML applications for volatility analysis. According to data taken from the Web of Science database, between 2001 and 2016 the number of articles related to the use of ML in the study of volatility was 84. Only considering the works published on this topic between 2017 and 2023 this figure increased to 234. In other words, in a little more than 6 years, more studies were published than in the previous 15 years. These figures show a clear trend for the use of ML techniques in volatility, which can convert this subject into a "hot topic" in the coming years.
This article aims to perform a literature review about the topic, accompanied by a bib-liometric analysis to identify trends in the scientific production on the use of ML in volatility and recognize possible research opportunities derived from this exercise. Consequently, a classification of the works published on this theme is proposed. This classification is complemented by a statistical analysis of the temporal evolution of scientific production in this field, the production by authors and countries, collaboration between countries, and the use of the K-means methodology to define the conceptual structure of this novel research area. The results are promising. Although a large majority of studies focus on volatility forecasting through neural network techniques, deep learning, and support vector machines (i.e., Tang et al., 2009; Chen et al., 2010; Pradeepkumar & Ravi, 2017; Liu, 2019; Gon et al. 2019), there is a smaller number of publications associated with proposals for volatility calibration (Zeng & Klabjan, 2019; Horvath et al., 2021), options valuation (Amornwattana et al., 2007; Fadda, 2020; Jerbi, & Chaabene, 2020), projects valuation (Jang et al., 2021), and some theoretical works related to stochastic processes and their use in volatility issues (Peng & Liu, 2011).
The remainder of this paper is structured as follows. Section 2 presents the methodology adopted to perform this exercise. Subsequently, section 3 shows the main obtained results.
Finally, a discussion related to the main findings and the principal conclusions are presented in sections 4 and 5, respectively.
Methodology
The developed exercise was carried out through two stages. In the first stage, corresponding to the literature review, data were collected from the Web of Science database1 using the search equations described in Table 1. 906 documents were obtained by this procedure. It is worth mentioning that the performed exercise corresponds to a narrative review of the literature. In this sense, it focuses on summarizing and identifying previous publications to find areas of study not covered in the literature. Posteriorly, as suggested by Ferrari (2015), we employed as inclusion criteria articles published in English and classified in the social science citation index (SSCI). Subsequently, articles that were not related to the financial area were excluded. Finally, at this step, each article was reviewed manually to propose a classification of the works that made use of ML techniques in volatility according to the topic, the machine learning technique and the type of assets that were studied. We obtained 338 articles. Moreover, in this section, a conceptual structure was defined through the K-means technique. In the second stage, a bibliometric analysis was conducted. In this stage, the trends in scientific production were identified by author, country, journals and collaborations between countries.
Step 1. Collecting Data
The first step corresponded to obtaining the articles that were related to the use of machine learning techniques in volatility. For this, a search was made in the cited database using different terms related to machine learning models, together with the term returns volatility (table 1). Following this procedure, 338 articles were identified and downloaded for the period 2001-2023.
Table 1 Search Equations
Step 2. Literature Review
The objective of the second step was to propose a classification of the articles to make a literature review of them. In this case, documents were analyzed one by one, placing special emphasis on the type of ML technique used, the task that was developed in the paper (i.e., volatility forecast and option valuation), the obtained results, and the financial asset class used in the document. Based on the above, a classification of the founded proposals was elaborated. This classification is detailed in the results section.
Step 3. Statistical Analysis
In this step, a statistical analysis was conducted on the results. For this goal, the Data.Table, DPLYR, and Bibliometrix packages, available at the R software, were employed. Through the used tools, the trend in the number of products associated with the studied subject was identified. Moreover, the main authors, the authors' nationality, the journals in which the developed articles were published, the authors' countries, and the collaborations between authors of different nationalities were recognized and analyzed.
Step 4. Conceptual structure using K-means
In this stage, an analysis of the documents was conducted through the ML model known as K-means. This method is identified as a clustering technique to "address the [ML] task of clustering, which involves finding natural groupings of data" (Lantz, 2019, p. 271). In this type of procedure, a specific result associated with the data is not required, as is the case in other ML techniques. The main objective of K-means is to establish groups from data that do not have a particular label but have similar characteristics which can be exploited to conform a defined number of groups. Each cluster is defined taking into consideration the similarity between the data that is used to perform the analysis.
The k-means algorithm involves assigning each of the n examples to one of the k clusters, where k is a number that has been defined ahead of time. The goal is to minimize the differences within each cluster and maximize the differences between clusters (Lantz, 2019, p. 272).
In particular, in this paper, we employed the K-means technique using the Bibliometrix package in R. In this case, the analysis aims to define the clusters according to co-occurrences of words in the set of employed documents identified in Step 1. This task is carried out by a routine of natural language processing2 in which the words contained in the titles and the abstracts of the analyzed papers are extracted to define clusters by the K-means technique. This exercise results in groups of documents with similarities in the used concepts, assets and machine learning techniques. The results derived from this step are presented in the results section.3
Results
Literature review
With the development of the methodology described in the previous section, the classification of the analyzed documents is proposed based on the task on which they are focused. For this purpose, a narrative review method was used since our exercise focuses on summarizing and identifying previous publications to find areas of study not covered in the literature (Ferrari, 2015). In this line, the Web of Science database was used as an electronic source, using as inclusion criteria articles published in English and classified in the social science citation index (SSCI). Articles that were not related to the financial area were excluded and an additional final manual debugging was performed to obtain the definitive database.
Forecast Volatility
The main application of ML methodologies in volatility corresponds to volatility forecasting. In this line, there is a marked trend towards the use of neural networks, deep learning and support vector machine methodologies.4 This last technique has received the most attention in recent years. Although most of the articles focus on the use of stock indices, some proposals use energy assets or individual stocks. Most of the articles use data daily, although some exercises employ intraday information.
In this regard, most of the analyzed articles focus on this type of task. In this context, the most applied machine learning methodology corresponds to the use of neural networks. The foregoing is a consequence of the relative ease in the use of this type of method and the evidence of offering satisfactory results in other types of prediction exercises. Most of the works in this group focus on the use of daily data employing stock indexes from the main financial markets in the U.S.A. and Asia. This can be explained by the availability of data for this type of market and the high academic production that characterizes these countries. For example, a large part of the body literature analyzes the volatility prediction for U.S.A. markets (Liu, 2019; Wang et al. 2019; Petneházi & Gáll, 2019; Ramos Pérez et al. 2019; Kaushik et al. 2019; Bucci, 2020; Jia & Yang, 2021; Wang et al. 2021; Chkili & Hamdi, 2021). Similarly, papers that used similar techniques for stock market indexes from countries different from the U.S.A. were identified. In this group, are worth mentioning applications to the Turkish, European, Taiwanese, Chinese markets, and the case of a few Latin American countries: Chile, Brazil y México (Slim, 2004; Tseng et al. 2008; Mo & Wang, 2013; Sermpinis et al. 2013; Kristjanpoller et al. 2014).
A third group of proposals used neural networks to forecast volatility for other types of assets. This is the case with the use of these techniques to predict volatility in exchange rates (Liu & Liu, 2006; Pradeepkumar & Ravi, 2017; Baffour et al. 2019; Liao et al. 2020), Bitcoin (Seo & Kim, 2020; Othman et al. 2020), oil prices (Bildirici & Ersin 2015; Kristjanpoller & Minutolo, 2016; Al-Fattah, 2019, Bouteska et al., 2023), and individual stocks for different markets (Calôba et al. 2001; Fong et al. 2005; Wang et al. 2012; Kristjanpoller & Minutolo, 2015; Kaushik et al. 2019).
In a different approach, articles that dealt with the modeling and forecasting of volatility for high-frequency data and the analysis of implied and realized volatility were identified (Hamid & Iqbal, 2004; Cai et al. 2013; Vortelinos, 2017; Kim & Baek, 2018; Zhai et al. 2020). In this group of proposals, most of the exercises used stock market indexes from U.S.A. and Asia. Other documents focused on the volatility analysis for decision-making and asset allocation (Kim & Enke; 2018; Weerasingha et al. 2021)
A second strand in the literature is related to works in which volatility is forecasted using hybrid models.5 In this case, the forecast of the interest variable is made through the ensemble of the outcomes obtained from at least two individual models. In this group, it is relevant to highlight the exercises developed by Ou & Wang (2014), Jung & Choi (2021), Liu and Fu (2016), Hu et al. (2020), and Kakade et al. (2022). In these articles, authors used hybrid models to forecast volatility related to copper Price, Chinese interbank offered rate, commodities, Nasdaq composite index and Exchange rates. The proposals employed combinations of support vector machines, chaotic genetic algorithms, extreme learning machines, deep learning and neural networks.
Another group of proposals employed support vector machine techniques to forecast volatility. In this type of exercise, most of the works use this technique to forecast volatility for daily and intraday data of U.S.A., European and Asian markets and Exchange rates (Tang et al. 2009; Chen et al. 2010; Ou & Wang, 2012; Wang et al. 2013; Santamaria-Bonfil et al. 2015; Chung & Zhang, 2017; Gong et al. 2019; Yang et al. 2020).
A recent trend in the literature associated with volatility forecasting through machine learning techniques corresponds to the use of Deep learning. In simple terms, Deep learning can be understood as an extension of neural networks with several hidden layers greater than one. In this case, most of the analyzed works are published between 2020 and 2021. Even though most of the articles focus on market indexes, it seems that this type of technique offers a higher degree of accuracy than those obtained from the previously exposed techniques. In this group it is worthwhile to mention the works of Kyoung-Sook and Hongjoong (2019), Kandem et al. (2020); Lei et al. (2021a), Lei et al. (2021b), Li et al. (2021), Petrozziello et al. (2022) and Di-Giorgi et al. (2023), considering that these publications correspond to proposals in which innovative use of deep learning algorithms is made for the forecast of volatility for different financial assets and markets.
Finally, there are a reduced number of proposals that used ML techniques different from the ones presented. These articles include the use of particle swarm optimization, adaptive heterogeneous autoregressive models, random forests and principal component analysis (Tung & Quek, 2011; Hung, 2011; Wei, 2012; Qu & Ji, 2014; Hung, 2015; Qu & Ji, 2016; Jobejarkol et al., 2018; Kristjanpoller & Minutolo, 2018; Ewees et al., 2020; Gupta et al., 2021). In a total of 86 analyzed articles, this group contributes with 9 publications. Although this number is reduced, this fact is suggestive in terms of looking for new research proposals that exploit the benefits of these models in volatility prediction exercises.
Volatility calibration and Surface construction
Another topic in which ML techniques have been applied to volatility analysis is the volatility calibration and the construction of volatility surfaces. While the Black-Scholes-Merton proposal has received great acceptance by the financial industry for the valuation of options, one of its main limitations corresponds to the assumption that volatility is constant for different strike prices with a defined time of maturity. Empirically, it has been shown that the graph which relates these two variables has a smile shape. Although different methods have been proposed in the financial literature for the calibration of volatility and the subsequent construction of volatility surfaces, this exercise presents considerable computational challenges. Recently, different proposals have been presented in which ML techniques are used to fulfill this task (Zeng & Klabjan, 2019; Cao et al., 2020; Stone et al.,2020; Horvath et al., 2021, Kwak et al., 2022), between the years 2020 and 2022 and make use of neural networks, deep learning, and support vector regression using options on financial indexes to conduct this exercise.
Derivatives pricing
One of the most interesting topics in finance corresponds to derivatives valuation. Even though there are numerous proposals in the literature to value different types of derivative contracts, some authors have made use of ML techniques to develop this task. Particularly, Amornwattana et al. (2007) proposed the use of neural networks to price call options. Liu et al. (2019) employed neural networks to price options and compute implied volatilities. Fadda (2020) made use of modular neural networks to value options and Jarbi and Chaabene (2020) proposed a stochastic volatility model which employed neural networks for price options.
Other Applications
From the conducted analysis, we found several papers in which ML techniques are used in volatility topics different from the previously studied ones. These documents do not correspond to clear trends in this literature area, but rather to isolated cases of applications in certain issues related to volatility. In this regard, Dash and Kajiji (2008) used generalized neural networks to analyze volatility spillovers in the European market of bonds. Jang et al. (2021) employed neural networks to analyze the risk level of a set of projects. Peng and Liu (2011) studied the PTH moment stability of stochastic Grossberg-Hopfield neural networks. Besides the mentioned articles, there are other applications in which ML is used to forecast direction volatility, predict requirement change volatility, analyze the profitability of a trading strategy and other applications (Tino et al. 2001; Bekiros & Georgoutsos, 2008; Medeiros et al., 2008; Xia et al., 2011; Zhu et al., 2013; Ge et al., 2019; Wang & Liu, 2020; Patnaik, 2020; Vrontos et al., 2021; Hein et al., 2021; Arvin et al., 2021; Rahman et al., 2018; Xu, 2021).
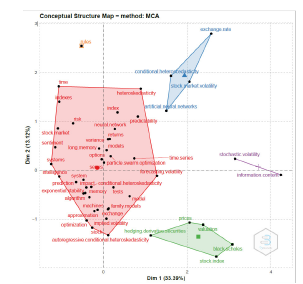
To complement the mentioned findings, we performed a K-means analysis to identify the potential conceptual structure of the use of ML in volatility (Figure 1). The details of this model are explained in section 1. We found 5 clusters related to the literature review presented in the previous section that are described as follows. The first cluster (red cluster) is related to exercises in which forecasting is the main task. In this setting, concepts such as neural network, predictability, index, and forecasting volatility are found. This cluster presents the largest size and groups most works in the performed analysis. A second cluster (green cluster) includes articles related to derivatives valuation. In this group, words such as hedging derivatives securities, valuation, and Black Scholes can be found. A third group (blue cluster) can be related to the works in which volatility calibration and volatility surface construction are developed. In this group, words like conditional heteroscedasticity and stock market volatility are present. The purple and orange clusters represent the works that do not belong to any clear trend and are classified as "other applications" in this paper.
Bibliometric Analysis
In the next part of this work, a bibliometric analysis was made in which we sought to recognize the patterns in the number of products related to the use of ML in volatility, the type of journal in which they were published, authors' nationality, collaborations between authors according to their country of origin and a proposal for the conceptual structure of the topic using K-means.
In terms of the number of academic products related to the use of machine learning in volatility, a clear growing trend is observed in recent periods, which experienced a boom towards the year 2018 (Figure 2). In the finance area, this change in the number of product slopes can be observed from 2015 onwards. This fact shows a short lag in academic production related to ML and volatility, thanks to the attention received by articles related to the analysis of returns. However, figure 1 constitutes evidence of the relevance that the use of ML in volatility is currently experiencing.

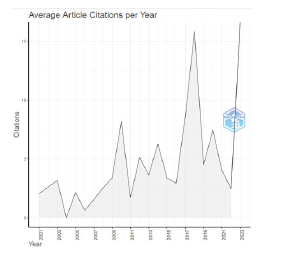
In this line, the number of citations per year (Figure 3) has experienced an increase in the previous years, particularly since 2013. This increase was expected considering the rise in the number of documents associated with ML in volatility presented in Figure 2.
When reviewing the number of articles per author, it was found that there is not a large concentration of products in a few authors. The academics who have published a higher number of articles on the studied subject do not exceed 15 manuscripts (4.4 % of the total sample) and many academics have five or fewer publications (1.5 % of the total sample) (Figure 4). These results are correlated to the H-index for the most relevant authors (Table 2), where it can be seen that a higher number of published articles implies a higher number of citations.
Table 2 H-index for Most Relevant Authors
| Author | H-index |
|---|---|
| GUPTA R | 7 |
| PIERDZIOCH C | 6 |
| KRISTJANPOLLER W | 5 |
| WANG J | 5 |
| BEKIROS SD | 4 |
| GKILLAS K | 4 |
| WANG SY | 4 |
| DUNIS CL | 3 |
| JI Q | 3 |
| KARATHANASOPOULOS A | 3 |
| KIM S | 3 |
| LI YZ | 3 |
| MEDEIROS MC | 3 |
| SANTOS AAP | 3 |
| SERMPINIS G | 3 |
| TIWARI AK | 3 |
| ZHANG YJ | 3 |

On the other hand, when reviewing the number of products according to the nationality of the authors, clear trends are observed in the application of ML to study volatility. In this case, the authors from China, the U.S.A. and the United Kingdom have 49 % of the total articles in the analyzed sample (Figure 5). It should be noted that in most cases, the articles developed by authors from these countries correspond to documents in which individuals from a single nationality participated.
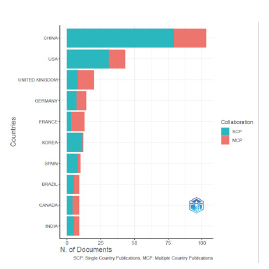
This concentration of production by country is confirmed by reviewing the network of international collaborations for the analyzed documents (Figure 6). In this case, China, the U.S.A and the United Kingdom present a greater number of collaborations. Publications including authors from different countries are evidenced not only between China, the U.S.A. and the United Kingdom. However, in the first case, there are numerous alliances with Singapore, Canada and Korea. In the case of the U.S.A., the collaborations with India, Singapore and Australia are striking. For the United Kingdom, the collaborations are presented with other European countries and some Asian nations.

All in all, Figures 5 and 6 show a clear trend towards a high degree of concentration of academic products that make ML applications on volatility using collaborations between a small group of countries. The search for alliances and co-authors in this field of research is a fundamental task for countries that still do not have a high degree of production in this area.
When analyzing the type of journal in which the reviewed articles are published (Table 3), most publications are classified in quantiles 1 and 2 according to the Web of Science database. A large part of these journals is focused on topics related to computer science, statistics, econometrics and physics. Particularly, the journal with a higher number of products is classified as a computer science publication. The above shows a clear gap in the production of works in journals specialized in finance and economics.
Table 3 Number of Publications per Journal
| JOURNAL | # OF PRODUCTS | % |
|---|---|---|
| EXPERT SYSTEMS WITH APPLICATIONS | 39 | 12 % |
| QUANTITATIVE FINANCE | 16 | 5 % |
| ENERGY ECONOMICS | 15 | 4 % |
| COMPUTATIONAL ECONOMICS | 12 | 4 % |
| INTERNATIONAL REVIEW OF FINANCIAL ANALYSIS | 10 | 3 % |
| FINANCIAL INNOVATION | 9 | 3 % |
| NORTH AMERICAN JOURNAL OF ECONOMICS AND FINANCE | 9 | 3 % |
| RESEARCH IN INTERNATIONAL BUSINESS AND FINANCE | 9 | 3 % |
| OTHERS | 219 | 65 % |
| TOTAL | 338 | 100 % |
Discussion and Implications
The developed exercise suggests interesting insights to be considered in future research works related to the application of machine learning techniques to the analysis of volatility for financial assets and markets. Firstly, interesting future research opportunities are presented regarding the growing trend of publications related to the studied topic and the development of computational tools that allow the development of sophisticated ML models to analyze financial volatility.
Moreover, there is a lack of studies that applied ML tools to the analysis of volatility transmission, volatility calibration surfaces, risk analysis, and corporate finance. This suggests the development of new research lines for academics working in these areas. The foregoing becomes even more relevant for emerging markets considering that there is not a high number of works for the topics in these markets.
On the other hand, our work has practical implications that suggest action plans for agents operating in financial markets. In particular, the use of ML techniques for volatility analysis plays a fundamental role in the design of investment and hedging strategies that accurately capture the financial market dynamics. Regulatory bodies could also begin to implement these types of models to monitor financial markets based on the remarkable results obtained from these types of models.
Finally, it is pertinent to mention that our proposal has limitations that could be considered for future studies. Firstly, only the Web of Science database was used to obtain the information employed as input for the development of the bibliometric analysis and the literature review. Incorporating other databases such as Scopus could confirm and strengthen the obtained results. On the other hand, it could be interesting to delve into the factors that explain why the publication of papers related to the studied topic is concentrated in certain markets and journals. This could generate future insights to understand academic production trends and design publication strategies related to the applications of ML techniques in the analysis of financial volatility.
Conclusions
In the last years, the use of ML in finance has experienced a remarkable increase. The study of volatility using this type of technique has not been an exception. Since 2017, the number of publications related to this topic has doubled according to data downloaded from the Web of Science database. The main uses of manuscripts related to this topic include volatility forecasting, calibration and construction of volatility surfaces, and the valuation of derivatives. Many publications in this area are related to authors or collaborations between China, the U.S.A. and the United Kingdom with a clear orientation to be disseminated in journals related to computer science, statistics, and forecasting. On the other hand, the most used methods correspond to neural networks, deep learning and support vector machines.
The above suggests the following observations. Firstly, it is expected that the use of ML in volatility will increase in the next years. In this case, there is a complete panorama to explore in terms of the methods that can be employed (different form neural networks) for different tasks with a variety of assets. For example, there is a lack of studies related to topics such as contagion risks, volatility spillovers, volatility calibration, and the estimation of risk in areas related to corporate finance. In terms of methods, currently, there are very few works related to text and sentiment analysis, decision trees, principal component analysis and deep learning. The constant use of developed stock market indexes is another concern. This creates opportunities to analyze other types of assets (i.e., energy) and markets (i.e., emerging markets).
As can be seen, there is a clear outlook for the use of machine learning in volatility. Especially if one considers that the journals related to economy and finance are still beginning to publish works related to this topic. The situation described in this paper reveals a panorama in which unprecedented opportunities for those interested in these models are available and ready to be exploited.

