











 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink1. Introduction
Programming production involves assigning workloads, sequencing jobs and timing them. Of these activities, sequencing is perhaps the most studied and is defined as the priority of service or processing of the jobs that are in the waiting line of the production system [1].
This activity is possibly the most complex of the process of programming operations due to its nature of combinatorial problem, especially if it is about intermittent production systems (job shop), which are characterized by manufacturing a wide variety of products in batches (batch), through several operations in different routes and processing times.
One of the first to study and propose a method of heuristic solution to this problem was Jackson [2]. Since then, the different methodologies that have been designed to solve the problem have been classified as heuristics and exact methods [3], see Table 1.

Exact methods can only be used in the solution of small problems due to the large number of variables that must be defined, and the excessive computational time required in their solution. The most common approach to the intermittent production is to use dispatch rules with priorities [3].
Most methods focus on models that satisfy only a single goal, but in the real world, usually, more than one of them most be satisfied simultaneously [4]. The most efficient programming systems must be able to achieve objectives concurrently such as, minimize the time of completion of all jobs (makespan), maximize the use of the machines, minimize costs of enlistment and preparation of parts and machines, maintain the balance of the workloads and meet the delivery deadline among other things.
2. Materials and methods
The problem consists in determining the sequence of operation of n jobs on m machines, to optimize a certain measure of performance that measures the efficiency of the program. The manufacture of each job requires the execution, in a certain established order, of a series of prefixed operations where each operation is assigned to one of the m machines and has a determined and known processing time. Problems such as that described above originate in the most diverse sectors of goods and/or services production.
The problem can be solved by total enumeration. However, since there are (n!) m possible sequences of operation and several performance measures or objective functions to optimize, is classified as a NP - hard problem, due to there is no algorithm that solves it in a reasonable computational time [2].
For 15 jobs on 6 machines there are (15!)6 possible sequences to be executed, here the question would be, which is the best? The answer to this question motivates the application of new solution alternatives and depends of the objective functions to optimize and the system variables. The parameters and variables of the model are observed in Table 2.

Given the difficulty of maximizing profits or minimizing costs in a programming process, termination time functions are used, where the goal is to minimize these functions [2]. Some of these are shown in Table 3.

The objective of this work is to find a production program by applying fuzzy logic for the case proposed in figure 1[5], which maximizes the use of the machines and at the same time minimize the makespan, the maximum wait time, the maximum advance, the maximum delay and the product in process.
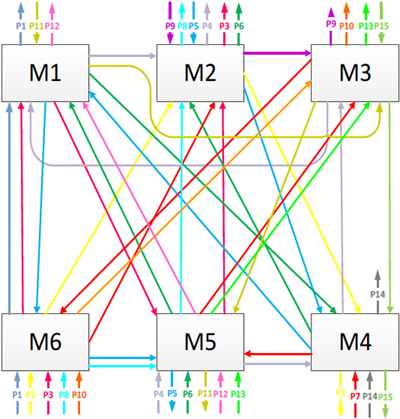
The variables to be considered in the problem are: the process time, the committed delivery deadline, the batch size, and the number of tools required in each operation, as shown in Table 4.

3. Proposed methodology
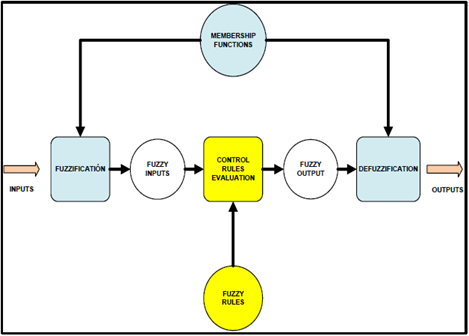
The information provided by the input variables is imprecise [6] because of its ambiguity, since they are bounded in intervals, for this reason we are in the presence of a deterministic uncertainty. Due to this, the method that is proposed involves the application of a Fuzzy Inference System (FIS), as an element of decision making. See flow diagram of Figure 2.

The FIS is comprised of the 4 input variables, a set of 81 rules of the mamdani type with the form IF - THEN (If -Then) and one output that represents the priority of the workpiece to be processed, as shown in Figure 3.

3.1 Inputs of the fuzzy logic controller
The 4 input variables that affect the problem have each one of them with a universe of discourse divided into 3 fuzzy sets, with small, medium and large linguistic variables [7] respectively, which represent the application of judgment and experience of the programmer when making a decision about the determination of the priority of the jobs.
The membership functions used are of the triangular type and right and left saturation, since they have been the ones that have shown the best behavior in similar studies [8] to this work. Figure 4 shows the fuzzy sets and the membership functions for the batch size.
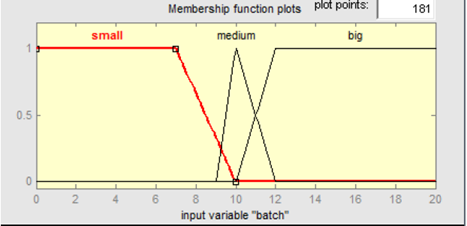
3.2 Output of the fuzzy logic controller
The output obtained corresponds to a priority value in percentage, which, ordered from largest to smallest, determines the processing sequence of the pieces. The universe of discourse is between 0 and 1 and is represented by nine fuzzy sets, seven of them are represented by triangular membership functions, and two by saturation functions (left and right) as can be seen in Figure 5.

3.3 Fuzzy Rules
The fuzzy rules also known as a blurry rules, combine input fuzzy sets or premises through logical conjuncts (and, or) that are associated with an output fuzzy set or consequence. These rules allow us to express the acquired knowledge about the relationship between antecedents and consequences of the problem under study [9].
The rules are the result of applying the decisions commonly made by the programmers of these production systems based on their experience [5]. Two of the eighty-one ("A" ~^"x " "=" "3" A"4" ) rules designed in the solution of this problem are described below.
3.4 Operation of the FIS
The fuzzification stage of the values of the input variables for each job consists of obtaining the fuzzy variables or belonging degrees of the input value x of the variable to each of the fuzzy sets "μ" _("A"_"i") "(x)" . See figure 6.
The second stage is the evaluation of the control rules, which consists of determining the rules that are activated in the face of a certain input value. Each rule has an associated weight i, that is calculated with the equation (1). This weight sets the belonging degree of the diffuse output variable in the fuzzy sets"μ" _("E"_"i") "(y)" .
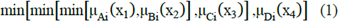
Finally, the defuzzification consists in finding a numerical value for the output from the fuzzy sets that compose it. Here the centroid method is used which consists in creating for the output (y) a membership "μ(y) " function to a new set resulting from the union of fuzzy sets to which the output value belongs partially [10]. These are obtained from the equation (2).

Where:
y = Centroid.
yk= Centroid of the membership function on the output set k.
Δk(y)=Subarea de k where is k.
For the implementation of the algorithm the pseudo-code shown in table 5 is developed, this provides a general description of the steps of how the fuzzy logic controller calculates the output (y) from the inputs (x1, x2, x3, x4).

3.5 Simulation and software
For the simulation of the FIS, the fuzbatch.mat file was created in ®Matlab with the information of the input variables and the fuzbatch.m file that executes the program of the operating instructions of the system.
With ®Fuzzy logic toolbox[11], the membership functions of membership for the inputs and the output were designed, as well as the control rules. Finally, the fuzbatchcdm block diagram was developed in ®Simulink shown in figure 7, which allows to simulate and obtain the process priority of the pieces.

4. Results and Discussion
The results obtained by running the program and the simulation, indicates that the pieces with highest priority value should be processed first.
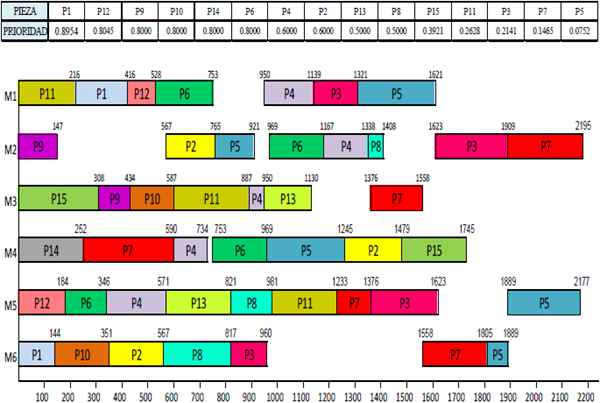
Initially there is the case for the fuzzy sets of the inputs with equal relative weight. Here, the piece that must be processed first is 1, then 12, 9,..., until finish with the work 5, as seen in figure 8, achieving a makespan of 2195 minutes. In table 6 shows that this program reaches better results than those obtained with the application of dispatch rules in five of the six objective functions to be optimized.

If the relative weight is increased for the batch size, the makespan is reduced to 1945 minutes. In this case the piece that must be processed first is 3, then 7, 15,..., until finishing with piece 5. See Figure 9.

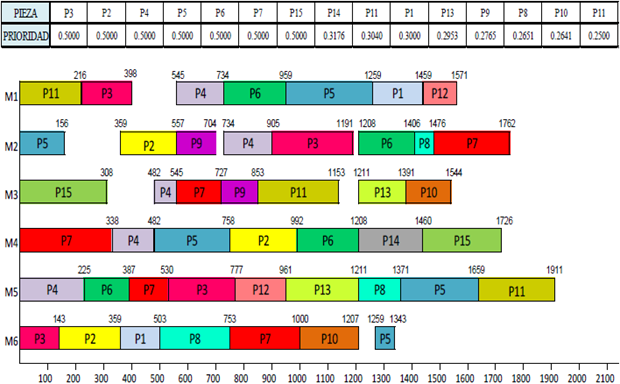
Finally, the optimal solution is obtained by simultaneously increasing the relative weight for the batch size and the processing time. Here piece 3 must be processed first, followed by 2, 4,..., until finishing with piece 11, achieving a makespan of 1911 minutes. See Figure 10.
The results obtained in the three simulations are condensed in Table 6. It shows that the objective functions initially proposed are satisfied, and the optimal solution is achieved that minimizes the total flow time.
For the solution with inputs of equal relative weight with respect to the dispatch rules, the completion time is improved by 2.96%, the maximum wait time by 9.51%, the maximum advance by 0.11% and the use of the machines by 2.06%, with no backlog, see Table 7.
Table 7 Comparison of results with inputs of equal relative weight with respect to the dispatch rules.
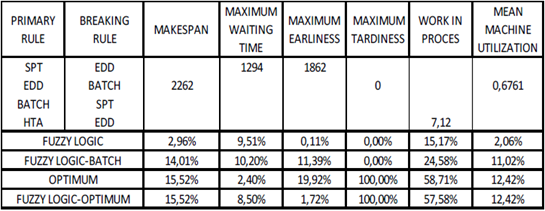
When the relative weight of the batch size is increased, improves the completion time by 14.01%, the maximum wait time by 10.20%, the maximum advance by 11.39% and the use of machinery in 11.02%, without any delay. It is then evident, that the relative weights of the inputs (batch size and processing time) directly influence the priority of the processing jobs in the job shop production system.

