











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
INTRODUCCIÓN
La localización es una tarea importante que cada día toma más fuerza en diferentes áreas del conocimiento. Algunos autores coinciden en que uno de los componentes críticos de las aplicaciones actuales de internet de las cosas (IoT, por su sigla en inglés) y las redes de sensores es la localización o el tracking del sensor o de los nodos móviles (Pahlavan, Krishnamurthy y Geng, 2015; Paul y Sato, 2017). Actualmente, en diversas áreas del conocimiento se emplean robots autónomos para completar tareas que antes eran desarrolladas por seres humanos (Becerra-Mora, 2020; Martínez-Sarmiento y Giral-Ramírez, 2016); para ello, esos robots requieren sistemas de localización que les permitan conocer su posición exacta o la de otros objetos dentro de una región de interés.
En los sistemas de radiolocalización, el objetivo es determinar la posición de transmisores desconocidos mediante la explotación de parámetros de propagación de las señales emitidas (Hincapié et al., 2018). Para ello se emplean diferentes algoritmos, entre los cuales se encuentran aquellos basados en ángulos, denominados algoritmos de ángulo de llegada (AOA, por su sigla en inglés) o dirección de llegada (DOA, por su sigla en inglés).
Los sistemas de DOA han generado un considerable interés en las últimas tres décadas, debido a su importancia en múltiples campos de aplicación como radar, sonar, sismología, comunicaciones inalámbricas, entre otros (Gu, Zhu y Swamy, 2011). Este tipo de sistemas emplean arreglos de antenas para determinar la dirección de llegada de una señal, aplicando técnicas basadas en subespacios y estimación de parámetros (Gross, 2005; Zhu y Chen, 2013). Sin embargo, estos algoritmos presentan inconvenientes y bajo desempeño en los casos en los que la relación señal a ruido (SNR, por su sigla en inglés) es baja y las fuentes tienen alto grado de correlación, además de que requieren un alto número de mediciones (Xenaki, Gerstoft y Mosegaard, 2014). Cabe mencionar que los sistemas de DOA tienen altos requerimientos en cuanto al arreglo de antenas, y la separación entre los elementos no debe ser mayor a la mitad de la longitud de onda, con el fin de evitar la aparición de lóbulos fantasmas (grating lobes) que pueden resultar en la estimación de falsos positivos, limitando de esta manera la apertura del arreglo. Lo anterior implica que si se quiere tener un sistema con mayor apertura es necesario tener arreglos con muchos elementos de antena, lo cual es problemático porque se requiere un mayor número de circuitos de front-end, trayendo implicaciones de hardware y software, ya que el tamaño de las matrices usadas es muy grande y genera alta carga computacional (Wang, Leus y Pandharipande, 2009).
Recientemente, debido a la naturaleza de esparcidad existente en los sistemas de posicionamiento, se ha propuesto usar la teoría de sensado comprimido (CS, por su sigla en inglés) para formular la tarea de localización como un problema de reconstrucción dispersa (Malioutov, Çetin y Willsky, 2005).
El sensado comprimido es una técnica de muestreo, que ha surgido en los últimos años, que permite disminuir la tasa de muestreo de la señal sin perder información, siempre y cuando la señal posea una representación dispersa en alguna base o diccionario conocido (Donoho, 2006). Dicho esto, el CS es especialmente atractivo para los esquemas de localización donde debido al esquema centralizado de procesamiento en banda base, un alto volumen de datos debe ser transmitido y procesado. Ahora bien, para poder formular el problema de localización basado en la teoría de reconstrucción dispersa, es necesario encontrar una base de representación adecuada, la cual permita estimar la posición de una o múltiples fuentes mediante proyecciones adaptativas no lineales de las mediciones sobre dicha base.
Por otra parte, teniendo en cuenta que muchos de los sistemas de posicionamiento emplean varios receptores de manera simultánea, es posible aplicar los algoritmos de sensado comprimido conjunto distribuido (JDCS, por su sigla en inglés), los cuales buscan explotar la inter- e intracorrelación de la señal, lo que permite mejorar la precisión del sistema (Lagunas, Sharma, Chatzinotas y Ottersten, 2016).
A partir de lo anterior, muchos autores han propuesto trabajos que permiten estimar la dirección de llegada de una o múltiples señales, realizando una discretización del espacio angular para aplicar las técnicas de reconstrucción dispersa y sensado comprimido. Gran parte de los trabajos relacionados buscan reducir la complejidad tanto en hardware como en software que puede generar el uso de grandes arreglos de antenas. Es el caso de Li y Huang (2014), quienes proponen una matriz de compresión para aplicar al factor de arreglo de tal manera que sea posible estimar el DOA, empleando algunos elementos de antena elegidos de manera aleatoria. Trabajos similares son presentados por Gürbüz, McClellan y Cevher (2008); Jouny (2011); Wang, Leus y Pandharipande (2009), y Xenaki, Gerstoft y Mosegaard (2014). Por su parte, Cotter (s. f.) aprovecha las múltiples muestras de la señal como mediciones diferentes con el fin de expandir el alcance del algoritmo y mejorar la precisión en la estimación. De otro lado, Asghar-Sayed y Ng (2019), y Pazos, Hurtado y Muravchik (2014) evalúan el desempeño de sistemas DOA con arreglos de antena que no son lineales uniformes (ULA) a los cuales se les aplica matrices de sensado comprimido en el dominio angular para estimar la dirección de llegada. Finalmente, Hincapié et al. (2018) diseñan un sistema híbrido DOA/TDOA (time difference of arrival) para estimar la posición de múltiples fuentes transmisoras.
Ahora bien, este trabajo evalúa el desempeño de un sistema de DOA aplicando la teoría de sensado comprimido a la matriz de covarianza de la señal usada tradicionalmente en los algoritmos clásicos de DOA, tal y como lo proponen Zhu y Chen (2013).
Al elegir el sensado comprimido a la matriz de covarianza, se brinda mayor estabilidad al sistema, en especial en condiciones en las que el canal es altamente ruidoso. Después de múltiples pruebas por simulación con la matriz de compresión a la señal recibida, se observa que el sistema pierde precisión, pues arroja estimaciones imprecisas en varias ocasiones, mientras que al hacerlo con la matriz de covarianza la precisión del sistema se conserva cuando se varían los niveles de ruido del canal.
Sin embargo, el mayor aporte y elemento diferenciador con los demás trabajos expuestos radica en que el sistema propuesto estima las coordenadas dentro de la región de interés (ROI, por su sigla en inglés) de múltiples fuentes transmisoras; de esta manera se obtiene una posición exacta dentro de un área y no solo un ángulo de llegada como sucede en la mayoría de los casos. Para ello se considera un sistema compuesto por múltiples nodos de referencia (RN, por su sigla en inglés), cada uno equipado con un arreglo de antenas, los cuales toman mediciones de la señal recibida y las envían al centro de fusión (FC, por su sigla en inglés) donde se aplica un algoritmo de JDCS para estimar la posición de los transmisores dentro de la ROI. Cabe mencionar que durante el trabajo se varían parámetros como el número de sensores, el ruido del sistema y las tasas de compresión, con el fin de evaluar el impacto de esto sobre la precisión en la estimación.
MODELO DEL SISTEMA
El modelo propuesto considera un sistema compuesto por Q fuentes transmisoras denominadas nodos objetivo (TN, por su sigla en inglés) y R receptores llamados nodos de referencia (RN, por su sigla en inglés), cada uno de los cuales tiene un arreglo de antenas compuesto por M elementos. Tanto los RN como los TN se ubican aleatoriamente dentro de una ROI, la cual se discretiza en K celdas, cada una de las cuales tiene coordenadas bidimensionales (BSk x, BSk Y) Adicionalmente, se cuenta con una entidad central denominada centro de fusión (FC, por su sigla en inglés) en la cual se lleva a cabo la estimación final de la posición empleando información recolectada y enviada por los RN mediante una red de backbone que los conecta.
Cada uno de los RN tiene coordenadas (Xr, Yr) dentro de la grilla, mientras que los TN tienen coordenadas (Xq, Yq), las cuales son desconocidas y serán estimadas a través del método propuesto.
A partir de lo anterior, se define un modelo de señal en el que se considera un canal simple sin multitrayectoria, el cual solamente considera efectos de atenuación y retardo sobre la componente de línea de vista (LOS, por su sigla en inglés) de la señal transmitida. Por tanto, cada RN recibe una señal Xr(n) dada por la ecuación (1), donde Sq es la señal transmitida por la fuente q-ésima; αq,r es el factor de atenuación, y Tq,r es el retardo en número de muestras que sufre la señal por la propagación entre el TNq y el RNr, y n(n) es el vector de ruido blanco gaussiano (AWGN, por su sigla en inglés) con media cero y varianza σ2:

Sin embargo, si consideramos que cada RN tiene un arreglo de antenas compuesto por 𝑀 elementos entonces, la señal recibida está dada por la ecuación (2):

Donde: xr [n] es la señal recibida después de haber pasado por el canal, y Ar
 es la matriz de los vectores de dirección propia del factor de arreglo. Cada uno de los elementos de Ar indica la dirección de llegada de cada una de las fuentes presentes en el sistema al RNr y está dada por la ecuación (3), donde λ = c/f es la longitud de onda de la señal recibida y dq es la distancia que hay entre el transmisor q-ésimo y cada elemento del arreglo de antenas del RNr:
es la matriz de los vectores de dirección propia del factor de arreglo. Cada uno de los elementos de Ar indica la dirección de llegada de cada una de las fuentes presentes en el sistema al RNr y está dada por la ecuación (3), donde λ = c/f es la longitud de onda de la señal recibida y dq es la distancia que hay entre el transmisor q-ésimo y cada elemento del arreglo de antenas del RNr:

Representación dispersa y sensado comprimido
En la mayoría de casos prácticos de los sistemas de localización, el número de fuentes es mucho menor al de posiciones desde las cuales puede provenir una señal; es decir, al discretizar la región de interés, la cantidad de celdas que efectivamente contienen fuentes transmisoras es mucho menor al tamaño de la grilla como tal, razón por la cual es posible plantear el problema de localización como de reconstrucción dispersa (Zhao, Irshad, Shi y Xu, 2019). Además, basados en la teoría de sensado comprimido desarrollada por Candès y Romberg (2006); Candès, Romberg y Tao (2006ª), 2006b), y Donoho (2006), la señal recibida ỹr [n[ se puede aproximar correctamente como una combinación lineal de algunos pocos elementos de una base de representación conocida o diccionario (Marín-Alfonso, Betancur-Agudelo y Alguello-Fuentes, 2017). Por consiguiente, es posible proponer un estimador ỹr [n[ para la señal recibida en cada RN dada por la ecuación (4), donde
 es el diccionario conocido con dimensiones N x K , siendo K la cantidad de celdas dentro de la grilla y N la longitud de la señal, y br es el vector disperso, con dimensiones K X 1, que tiene tantos coeficientes diferentes de cero como número de fuentes existen en el sistema (Schmitz, Mathar y Dorsch, 2015):
es el diccionario conocido con dimensiones N x K , siendo K la cantidad de celdas dentro de la grilla y N la longitud de la señal, y br es el vector disperso, con dimensiones K X 1, que tiene tantos coeficientes diferentes de cero como número de fuentes existen en el sistema (Schmitz, Mathar y Dorsch, 2015):

La ecuación (4) se puede resolver mediante la minimización de la norma l
0
buscando los valores diferentes de cero en el vector br; sin embargo, esto es un problema NP-hard, lo cual implica que el número de combinaciones posibles para encontrar una solución óptima tiende a infinito, por lo cual se busca simplificar el problema, mediante una relajación de la norma l
0
. Esto se puede dar bajo condiciones adicionales que se asumen sobre la matriz
, obteniendo de esta manera una posible solución mediante la minimización de la norma l
1
(Schmitz, Mathar y Dorsch, 2015). En consecuencia, se plantea el problema de minimización siguiendo la ecuación (5), que puede ser resuelta mediante esquemas de optimización convexa o algoritmos codiciosos como orthogonal matching purtsuit (OMP):
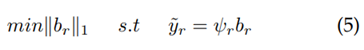
Por su parte, la teoría de sensado comprimido permite incorporar una matriz φ
r
de dimensiones P X N con P N, que reduzca el tamaño del vector de mediciones ỹr. Además, bajo la teoría de sensado comprimido es posible reconstruir br usando un menor número de muestras mediante proyecciones lineales no adaptativas sobre una matriz de observaciones φ
r
que es incoherente con
(Bougher, 2015; Foucart y Rauhut, 2013). Por consiguiente, el vector de mediciones ỹr está dado por la ecuación (6):

La matriz φ r se genera como una matriz de submuestreo, en la cual se toman P filas de una matriz identidad de N X N con el fin de tomar P muestras de la medición original. Ahora bien, reformulando la ecuación (5), se obtiene que el problema de optimización está dado por la ecuación (7), y se resuelve aplicando el mismo algoritmo OMP.

Sensado comprimido conjunto distribuido
Teniendo en cuenta que el sistema propuesto considera un esquema centralizado con múltiples nodos de referencia para estimar la posición, es posible aplicar la teoría de sensado comprimido conjunto distribuido (JDCS, por su sigla en inglés) y explotar tanto la inter- como la intracorrelación de la señal, como lo sugieren Duarte et al. (2005) a . JDCS considera la esparsidad conjunta de una señal para obtener una reconstrucción precisa de la señal (Nikitaki y Tsakalides, 2011).
En un escenario típico de DCS, cada sensor mide señales que son dispersas individualmente en alguna base de representación y a su vez están correlacionadas entre sí. Por eso, cada sensor de manera independiente codifica su señal mediante proyecciones incoherentes sobre su base de representación dispersa, y en las condiciones adecuadas un decodificador en el centro de fusión puede reconstruir de manera conjunta y precisa la señal, de lo que se obtienen las coordenadas (Xq, Yq) de los transmisores dentro de la región de interés (Duarte et al., 2005b).
METODOLOGÍA
El método propuesto para estimar la posición de varios transmisores, mediante sensado comprimido y reconstrucción dispersa a la matriz de covarianza usada en los algoritmos tradicionales de dirección de llegada, se realiza en dos etapas: offline y online.
En la primera etapa, offline, se construye el diccionario o base de representación dispersa
para cada uno de los nodos de referencia del sistema. Mientras que en online se toman las mediciones que son enviadas al FC para realizar la estimación de la posición. A continuación se describen en detalle estas etapas.
Etapa offline: construcción de diccionarios
Cada RN construye su propio diccionario
 , que contiene la versión vectorizada de la matriz de covarianza del factor de arreglo para cada una de las k posiciones dentro de la grilla. Cada elemento se calcula empleando la ecuación (8), donde α(θ) se calcula con la ecuación (3), y (.)H denota la hermitiana de un vector:
, que contiene la versión vectorizada de la matriz de covarianza del factor de arreglo para cada una de las k posiciones dentro de la grilla. Cada elemento se calcula empleando la ecuación (8), donde α(θ) se calcula con la ecuación (3), y (.)H denota la hermitiana de un vector:
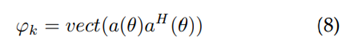
Para construir el diccionario, una vez se tenga discretizada la región de interés, se ubican los RN dentro de esta y se fijan en las coordenadas (Xr, Yr). Posteriormente se ubica una única fuente transmisora en la primera celda de la grilla cuyas coordenadas corresponden a (BS1 X,BS1 Y) y se aplica la ecuación (8). En este caso, la distancia dq de la ecuación (3) se reescribe como dr m,1, la cual corresponde a la distancia entre el elemento m del arreglo de antenas del r-ésimo receptor y la k=1 posición dentro de la grilla. Este proceso se repite para cada una de las posiciones dentro de la grilla hasta finalizar la construcción del diccionario. Por tanto, el tamaño de la base de representación es de M2 x K, donde M es el número de elementos de antena del arreglo y K es la cantidad de celdas de la grilla.
Etapa online: medición
En esta etapa se toman las mediciones de las fuentes reales, las cuales son enviadas al centro de fusión para aplicar el algoritmo OMP y estimar las coordenadas (Xq, Yq). Para realizar las mediciones, cada RN calcula la matriz de covarianza de la señal recibida dada por la ecuación (9) (Gross, 2005), donde N es la longitud de la señal recibida y Yr está definida por la ecuación (2).

Una vez se tenga la matriz de covarianza se vectoriza y se comprime aplicando la ecuación (10), que es la medición que cada RN calcula y envía al FC. La versión vectorizada de la matriz de covarianza es de dimensiones M2X1, mientras que la versión comprimida es de PX1, donde P M2.

Estandarizando la notación de las variables, decimos que ỹr = Rr xx es la medición sin comprimir, y que ŷr = Rr XX es la medición comprimida.
Estimación de la posición
Para realizar la estimación se debe contar con los dos insumos recolectados en las etapas previas: los diccionarios y la medición, para proceder a aplicar el algoritmo OMP que nos permite obtener las coordenadas de los transmisores.
El algoritmo OMP construye de manera iterativa una estimación de un conjunto soporte desconocido. β Si β es estimado en la iteración (i _ 1), se usa el residual
 de la aproximación por mínimos cuadrados de Θrbr, donde sup(br) ? β, para elegir una actualización para β. Esto se logra seleccionando el índice donde el vector de la proyección definida por la ecuación (11) es máximo (Schmitz, Mathar y Dorsch, 2015).
de la aproximación por mínimos cuadrados de Θrbr, donde sup(br) ? β, para elegir una actualización para β. Esto se logra seleccionando el índice donde el vector de la proyección definida por la ecuación (11) es máximo (Schmitz, Mathar y Dorsch, 2015).

En el caso de JDCS, se hace una combinación no coherente de los valores máximos de correlación obtenidos para cada RN con el fin de medir que tanto un transmisor está presente en una determinada celda k. Lo anterior supone una modificación en el algoritmo OMP que ha sido ampliamente estudiado por diferentes autores (Baron et al., 2009; Eldar, Kuppinger y Bölcskei, 2010).
El algoritmo usado se detalla en la figura 1, el cual puede tener como criterio de parada un número de iteraciones igual al número de fuentes del sistema, siempre y cuando este sea conocido como en el caso de los ambientes colaborativos, o si se cumple una condición de parada usualmente relacionada con la energía del residual, la cual implica que la norma del residual actual es menor que un umbral definido, que usualmente es una función de la relación señal a ruido de la señal.

Ahora bien, con fin de confirmar las consideraciones teóricas y evaluar el desempeño del sistema propuesto, se realizan simulaciones numéricas de un ambiente de radio propagación en dos dimensiones, empleando un modelo de canal simple basado en la ecuación de Friis (Rappaport, 2001). A continuación, se describen los parámetros empleados y se explica en detalle el proceso desarrollado para la obtención de resultados.
Cada transmisor genera una señal banda base con una frecuencia de muestreo de 100 MHz, con modulación BPSK. Cada receptor recibe una señal dada por la ecuación (1), la cual corresponde a la suma de las señales transmitidas, las cuales están retrasadas en el tiempo y tienen una atenuación en potencia causada por los efectos de propagación entre cada par de transmisores y receptores. Además, esta ecuación incluye ruido blanco gaussiano n[n] con media cero y matriz de covarianza Rnn = σ2 I, el cual se asume idéntico en todos los RN.
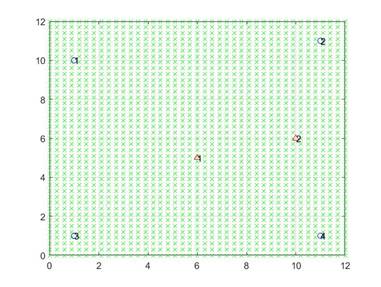
El escenario considera una ROI como la que se muestra en la figura 2, la cual tiene 4 RN (círculos azules) ubicados en posiciones fijas para todas las simulaciones, y 2 TN (triángulos rojos) los cuales se ubican de manera aleatoria dentro de la ROI en cada iteración del algoritmo. Esta figura muestra la ROI ya discretizada para llevar a cabo la construcción del diccionario. Cada una de las cruces verdes corresponde a la posición k-ésima con coordenadas (BSk x, BSk y)
Se plantean tres escenarios diferentes en los que se calcula el RMSE (root mean square error) de la estimación de la posición, a partir de 1000 simulaciones Monte-Carlo para cada caso. A continuación, se describen los escenarios propuestos.
Escenario 1: tasa de compresión vs. RMSE con 2 TN
Se establecen cuatro tasas de compresión diferentes, las cuales indican el porcentaje de muestras que se toman de la señal original para realizar la estimación de la posición, y se calcula el RMSE para diferentes valores de σ2. Esto implica más o menos ruido en la medición.
Los valores de la tasa de compresión empleados son: ρ = [ 20,40,60,80 ], y los valores de varianza evaluados son: σ2= [ 1,5,10,20,50].
Escenario 2: tasa de compresión vs. RMSE para 1 TN
Igual al caso anterior, se calcula el RMSE para cuatro tasas de compresión diferentes y cinco valores de σ2; sin embargo, aquí se estima la posición de una única fuente, con el fin de comparar los resultados con el caso en el que hay dos TN y determinar la influencia que tiene en el desempeño del sistema la presencia de múltiples fuentes transmisoras.
Los valores de la tasa de compresión empleados son: ρ = [ 20,40,60,80 ], y los valores de varianza evaluados son: σ2= [ 1,5,10,20,50].
RESULTADOS
A continuación, se detallan los resultados para cada caso de estudio y se realiza una breve discusión al respecto.
Escenario 1
La figura 3 muestra cómo el RMSE aumenta gradualmente a medida que aumenta el porcentaje de la tasa de compresión. Como era de esperarse, entre menos muestras de la señal se tomen para hacer la estimación, mayor es el error en la estimación; sin embargo, cabe mencionar que las variaciones del error son poco significativas, aun cuando el ruido de la medición es alto. El peor escenario se obtiene cuando se tiene un σ2 =50 y un ρ=80, lo cual implica que solo con el 20 % de las muestras y un canal muy ruidoso se tiene un error inferior a 4,5 metros de la posición real; mientras que para el mismo valor de ρ pero en un canal casi ideal, el error del sistema es ligeramente inferior a 1 m.
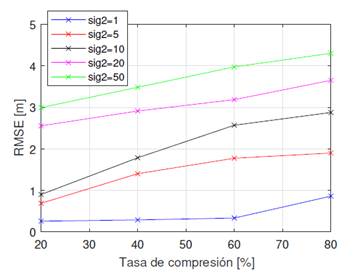
Fuente: elaboración propia
Figura 3 Tasa de compresión vs. RMSE con 2 TN para diferentes valores de σ2
Es claro que, a medida que aumentan los valores de ρ y σ2, el desempeño del sistema disminuye. Sin embargo, en términos generales, la precisión del sistema es buena incluso cuando las condiciones del canal son desfavorables.
Cabe mencionar que tener menor cantidad de muestras en la medición disminuye el costo computacional del algoritmo, ya que el tamaño de las matrices disminuye.
Escenario 2
En este caso se evalúan los mismos parámetros que en el caso anterior, pero solamente se considera un transmisor activo en el sistema. La figura 4 muestra que, como era de esperarse, el error disminuye cuando solo se considera una fuente con respecto al caso anterior. Además, es posible observar que la diferencia entre cada uno de los casos es muy pequeña, casi despreciable, teniendo un promedio de error cercano a 0,14 metros en la estimación de la posición. A diferencia del primer caso el error de la posición no se acumula en el cálculo de los residuales del algoritmo OMP, ya que solo se precisa de una iteración para calcular las coordenadas del TN, lo cual impacta directamente en la precisión del sistema.

Escenario 3
En este caso se considera un canal ideal, sin ruido, y los mismos valores de la tasa de compresión, sin embargo, se varía el número de RN que tiene el sistema con el fin de evaluar qué tanto afecta este parámetro la precisión del sistema.
La figura 5 muestra cómo, a medida que aumenta el número de RN en el sistema, el error disminuye para todos los valores propuestos de ρ. Además, a medida que aumenta la tasa de compresión el error es mayor, lo cual es lógico pues se están tomando menos muestras de la medición para hacer la estimación. Sin embargo, cabe mencionar que la diferencia de los errores calculados es muy baja, teniendo un error promedio de 0,34 metros cuando hay 2 RN y de 0,16 metros cuando hay 5 RN. Lo anterior implica que es necesario determinar el rango de precisión que requiere el sistema considerado, dado que aumentar la cantidad de RN aumenta de manera considerable el costo del sistema y adicionalmente la complejidad computacional también se incrementa, pero la ganancia en términos del error es muy baja.

CONCLUSIONES
Este trabajo presenta un novedoso sistema de localización, basado en algoritmos de dirección de llegada (DOA, por su sigla en inglés), que explota la esparsidad espacial propio del problema de localización para aplicar la teoría de sensado comprimido con el fin de estimar la posición de una o múltiples fuentes transmisoras. El método utiliza la matriz de covarianza de la señal recibida, usada típicamente en las técnicas clásicas de DOA para calcular con una alta precisión la posición de las fuentes. Sin embargo, en este trabajo, el tamaño de esta matriz se puede disminuir hasta en un 80 %, gracias a la teoría de sensado comprimido. Los resultados demuestran que la precisión del sistema es alta, incluso en los casos en los que las condiciones de ruido son altas, al igual que las tasas de compresión. Para dos fuentes, se obtiene un error máximo inferior a las 4,5 metros con respecto a la posición real, para el peor escenario, e inferior a los 0,5 metros, para el mejor caso. Por su parte, cuando solo hay un transmisor en el sistema, el desempeño del sistema es mucho mejor, ya que no hay acumulación del error en los residuales calculados en el algoritmo OMP, de lo que se obtiene un error promedio cercano a los 14 centímetros con respecto a la posición real del TN. Adicionalmente, se evalúa el caso en el que se vería el número de RN, observando que, para un canal ideal, la precisión no mejora de forma significativa en comparación con el aumento en la carga computacional.
Este trabajo permite entonces concluir que gracias a la esparcidad presente en la naturaleza del problema de localización es posible aplicar la teoría de sensado comprimido para estimar la posición de múltiples fuentes transmisoras con alta precisión.
FINANCIAMIENTO
Los resultados presentados en este documento forman parte del trabajo de investigación doctoral titulado “Evaluación de un sistema de radiolocalización híbrido mediante el uso de la teoría de reconstrucción dispersa y sensado comprimido conjunta para la localización de múltiples fuentes transmisoras”, realizado en la Universidad Pontificia Bolivariana, sede Medellín, y financiado por la Convocatoria 727 de MinCiencias.

