











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares en
SciELO
Similares en
SciELO  Similares en Google
Similares en Google 
 Permalink
Permalink
I. Introducción
Actualmente muchas compañías en sus sistemas de información registran todas las transacciones que se realizan. La gran cantidad de datos almacenada sobrepasa con creces las capacidades humanas para su procesamiento y análisis manual; limitando las capacidades de detección de fraude en la institución. Una de las soluciones planteadas para el apoyo a la detección de fraude ha sido la identificación de anomalías o datos atípicos para analizar aquellas transacciones de los clientes que no corresponden a lo que habitualmente este hace [1,2,3]. Para lograr este objetivo se hace necesario la utilización de herramientas informáticas, que permitan identificar dentro de miles o millones de transacciones y registros, patrones de comportamiento que son inusuales y corresponden a actividades potencialmente fraudulentas. En [1] se presenta un breve estudio de las diferentes técnicas que han sido aplicadas. Las técnicas utilizadas se enfocan fundamentalmente en la detección de anomalías [4, 5], las cuales pueden depender de factores como la naturaleza de los datos, la disponibilidad de los datos etiquetados y el tipo de anomalías que se desee detectar.
Cuando los datos no están etiquetados se han utilizado técnicas descriptivas basadas en algoritmos de agrupamiento [6, 7] y técnicas basadas en vecino más cercano . Dentro de las técnicas basadas en el vecino más cercano [8], se encuentran los algoritmos cuyo cálculo del índice de anomalía se basa en el cálculo de las distancias y en el de las densidades. El incremento del uso de la tecnología representa un reto para los algoritmos tradicionales de detección de anomalías. El reto se debe a que los datos se han caracterizados por el incremento de su volumen, la velocidad con la que se generan y la variedad en su estructura y formato. Estas tres características continúan creciendo, lo que imposibilita que sistemas tradicionales almacenen y procesen los datos. No existe un tamaño específico que determine los datos en big data. A partir de lo anterior surge como concepto “big data”. La fortaleza de big data radica en la capacidad de procesar grandes volúmenes de información en un tiempo razonable [9,10,11,12].
Entre las diversas herramientas que aplican la minería de datos y ejecutan sus técnicas sobre grandes volúmenes de información se encuentra Spark. Una plataforma de clúster de computadoras diseñada para ser rápida y de propósito general [13,14,15]. La cual no presenta algoritmos para la detección de anomalías.
En este trabajo se propone un diseño MapReduce de un algoritmo de detección de anomalías para grandes volúmenes de datos. Por esta razón, el resto del trabajo está organizado de la siguiente manera. En la sección 2 se aborda toda la explicación referente a las diferentes técnicas de detección de anomalías y fu funcionamiento además de un estudio comparativo de los diferentes algoritmos de detección de anomalías basados en vecindad. En la sección 3 se demuestra un diseño MapReduce para la detección de anomalías en grandes volúmenes de datos donde se explican las diferentes etapas del algoritmo propuesto. Posteriormente, en la sección 4 se exponen los resultados obtenidos de la comparación del algoritmo para big data y el algoritmo secuencial para detección de anomalías. Finalmente, en la sección 5 se muestran las principales conclusiones alcanzadas en este trabajo.
II. Técnicas de detección de anomalías
Dentro de las técnicas de detección de anomalías puntuales se encuentran las basadas en agrupamiento, en el vecino cercano, en estadísticas y en la teoría de la información. Las técnicas de detección de anomalías basadas en la vecindad plantean que las instancias normales ocurren en vecindades densas, mientras las anomalías ocurren lejos de sus vecinos más cercanos. Estas técnicas requieren de una distancia o una medida similar definida entre dos instancias de datos [4, 5]. La distancia que se emplean en los algoritmos de vecinos más cercanos es la distancia Euclidiana [4, 5].
Las técnicas de detección de anomalías basadas en la vecindad se pueden agrupar en dos categorías:
Técnicas que emplean las distancia a su k vecino cercano como índice de anomalía.
Técnicas que determinan el índice de anomalía a partir del cálculo de densidad de cada instancia.
El índice de anomalía es una puntuación o valor numérico que se le asigna a cada instancia de los datos en dependencia del grado de anomalía en que es considerada dicha instancia [4, 5]. Por lo que la salida de las técnicas de detección de anomalías basada en la vecindad es un listado de posiciones de acuerdo con el índice de anomalía. Para ambos casos se define una etapa inicial común que trata de determinar la k vecindad de cada instancia. La k vecindad está dada por la k_distancia del objeto [4, 5]. La cual cumple con la siguiente definición:
Definición 1. Dado un conjunto de datos D la k_distancia de un objeto p para cualquier entero positivo k, es definida como la distancia d(p,o) entre p y el objeto o∈D. Esta distancia debe cumplir las siguientes restricciones [16]:
Para al menos k objetos o′∈D\{p} se mantiene que la d(p,o′)≤d(p,o).
Para lo sumo k−1 objetos o′∈D\{p} se mantiene que la d(p,o′)
Por lo que la k_distancia de la vecindad de p no es más que aquella que se define a continuación:
Definición 2. Dada la k_distancia de p, la k_vecindad de p contiene cada objeto cuya distancia desde p no es mayor que la k_distancia. De esta forma los objetos q son llamados los k vecinos más cercanos de p.
 (1)
(1)
La Figura 1 muestra la k vecindad para la instancia P definida por k_distancia(P)=d (P, O_1) para k=4. Donde O 1, O 2, O 3 y O 4 son los k vecinos cercanos de P. En el caso que el objeto presenta duplicados se puede incorporar una nueva restricción en la que debe haber como mínimo k objetos con diferentes coordenadas espaciales. Esto se debe a que los duplicados pueden traer consecuencias graves para el cálculo de las densidades como la obtención de valores infinitos.

Para el cálculo del índice de anomalía basado en la densidad se realizan los siguientes pasos:
Se determina la densidad de cada instancia.
Se obtiene el índice de anomalía a raíz de la comparación de la densidad de la instancia con las densidades de los otros vecinos cercanos.
Para el caso en que el índice está basado en la distancia:
Se determina el índice de anomalía con una operación sobre las distancias de la instancia a sus vecinos cercanos.
Ejemplo de ello es el KNNW que el índice de anomalía de una instancia es la suma de las distancias a sus k vecinos cercanos. Estudio comparativo de los algoritmos de detección de anomalía basada en vecindad
Las comparaciones se realizaron con distintas configuraciones de los algoritmos y empleando distintas bases de datos clasificadas en anómalo o normal. Los algoritmos se compilaron con distintos valores para la búsqueda del vecino cercano con k = {1,2,3,4,5,6,7,8,9,10,15,20}. Las bases de datos que se emplearon para la compilación de cada algoritmo presentan atributos numéricos y un atributo que es la etiqueta que clasifica al objeto como anómalo o normal. Estas bases de datos se describen en la Tabla 1.

Para evaluar cada resultado arrojado por los algoritmos por cada valor de k y la comparación entre ellos se empleó la métrica de evaluación área bajo la curva ROC. La comparación de los resultados se realizó con la herramienta Keel utilizando el procedimiento esta dístico Friedman 1xN y los métodos post hoc Holm y Finner. La Tabla 2 muestra los lugares que toman los algoritmos de acuerdo con las pruebas de Friedman, y se destaca que el KNNW es el algoritmo con mejor resultados.
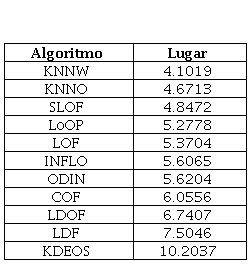
En la Tabla 3 se puede apreciar la comparación del algoritmo KNNW con respecto a los restantes algoritmos empleando la prueba estadística de Friedman, en la que se fija un α=0.05. En la columna marcada con “P” se muestra el p-valor ajustado para determina si existe diferencia significativa. En el caso del KNNW existe una diferencia significativa con los algoritmos cuyo valor P sea menor que 0.05. Por lo que los algoritmos que se comportan semejante al KNNW son el SLOF y el KNNO. A partir de los resultados de las pruebas se determina emplear el KNNW como base para la detección de anomalías en big data.

III. Diseño MapReduce para la detección de anomalías en big data
La información almacenada que genera una empresa o un sistema informático crece exponencialmente. Esta información almacenada puede contener conocimientos valiosos que le permitan a la entidad dueña obtener ventajas. Pero cuando los datos almacenados crecen día a día exponencialmente, implica un reto en el procesamiento y extracción de conocimiento para los sistemas informáticos. Las herramientas tradicionales que comúnmente analizan la información no son capaces de trabajar con grandes volúmenes de datos. Estos datos son conocidos actualmente con el término big data. Se definen como big data a datos cuyo volumen, diversidad y complejidad requieren nueva arquitectura, técnicas, algoritmos y análisis para gestionar y extraer conocimiento.
A raíz de esta situación surgen diversas herramientas y framework que proponen una solución a esta problemática. Una de las soluciones más populares para abordar algunos problemas de big data es MapReduce, un modelo de programación utilizado por Google para dar soporte a la computación paralela sobre grandes colecciones de datos en grupos de computadoras. Este paradigma procesa datos estructurados en pares clave-valor y consta de dos fases: map y reduce.
En términos generales, los datos se dividen en sub-problemas más pequeños que son distribuidos por los nodos de un clúster para ser procesados de forma independiente en la fase Map. Las soluciones parciales obtenidas por cada proceso Map se combinan de alguna forma en la fase Reduce para obtener una solución. Muchas son las plataformas que han adoptado MapReduce como una solución para problemas de big data, como ejemplo se encuentran Hadoop y Apache Spark.
A. Diseño MapReduce del algoritmo KNNW
En esta sección se muestran y describen las distintas fases del diseño del algoritmo KNNW para problemas de big data. El algoritmo KNNW mantiene la estructura de los algoritmos basado en distancias planteados anteriormente. La función que calcula el índice de anomalía del KNNW no es más que las sumas de las distancias de cada objeto a sus k vecinos más cercanos como se muestra a continuación:
 (2)
(2)
El diseño MapReduce del algoritmo KNNW consta de dos fases. La primera fase se encarga del particionado de los datos y del cálculo de los valores de anomalía local (con respecto a los puntos de su partición) de todas las tuplas que se analizan. Como muestra la Figura 2 inicialmente distribuyen los datos en distintas particiones. Posteriormente a cada partición se le aplica una función map para obtener de cada elemento de la partición las distancias de sus k vecinos más cercanos en la partición. Luego se realiza un map para obtener el índice de anomalía normalizado. El resultado final de esta fase son los elementos como llave y el índice de anomalía lo mismos.

Un índice de anomalía elevado luego de la primera fase puede indicar dos cosas: que estos objetos son anómalos o que en su partición no se encontraban sus vecinos cercanos. Es por ello que en la segunda fase se seleccionan el P porciento de los objetos con mayor valor de anomalía de cada partición (generalmente el 1%) para reajustar el índice de anomalías. De esta manera se pueden evitar gran cantidad de falso positivos y es el objetivo principal de la segunda fase del algoritmo. Para ello se diseña una etapa MapReduce calcula las distancias a todos los objetos de la base de datos de los elementos seleccionados en cada partición y luego determina los vecinos cercanos a estos.
Por último, se realiza una etapa de map para calcular los nuevos valores de anomalía de los elementos seleccionados al principio de la segunda fase. De esa forma aquel objeto que no es anómalo corrige su índice de anomalía y el que es anómalo su índice quedara ajusto al valor real. Los resultados del reduce se combinan con el resto de los elementos que no fueron filtrados en la primera etapa y se devuelve la lista ordenada de los objetos con respecto a su valor de anomalía. En las Figuras 3 y 4 se muestra este proceso.


B. Análisis de la eficiencia y eficacia del diseño MapReduce para KNNW - Diseño de los experimentos
En este caso de documento se aborda cómo se comporta la implementación big data del algoritmo KNNW frente a su versión secuencial. El diseño los experimentos se encuentran en la Tabla 4, la cual se muestra a continuación:

Para validar los resultados se realizaron experimentos con una base de datos clasificadas del Kdd99 de 500000 transacciones aproximadamente. Esta base de datos se divide en distintos subconjuntos de 100000, 200000, 300000 y 400000 manteniendo para cada subconjunto la cantidad de instancias anómalas. Donde se compara el tiempo de ejecución y la eficiencia de cada algoritmo para las distintas cantidades de datos. Para los algoritmos se definió una k = 10. En caso del KNNW_Big Data se establece por ciento para la segunda fase igual a 0.01 y para cada aumento de los datos en 100000 se aumenta la cantidad de particiones en 4.
IV. Resultados experimentales
A. Comparación entre KNNW-Big Data con KNWW secuencial
Para los algoritmos KNNW y KNNW-Big Data se asignó para la variable de entrada K=10 Y p=0.01 la cual representa a los K vecinos más cercanos. Los experimentos de los algoritmos se realizaron con un total de 40 cores y 40 GB de memoria RAM. En caso del algoritmo secuencial los experimentos se realizaron en una PC donde se utilizó 1 core y 8 GB RAM.
A demás se muestran en la Tabla 5 las características de la base de datos que se empleó para los posteriores experimentos. Esta base de datos se extrajo del sitio web de la universidad de Harvard. Esta base de datos cuenta con una etiqueta que clasifica si a una instancia en normal y anómala. Esta etiqueta es el único atributo nominal que presenta y que para la comparación entre los algoritmos de los algoritmos se excluyó.

El propósito del primer experimento es evaluar la calidad de los resultados y el tiempo de ejecución de los algoritmos KNNW y KNNW-Big Data a medida que aumenta el volumen de los datos. Para ello se dividió en distintos subconjuntos la base de datos clasificada kdd99. A demás se definió para cada partición de datos de la variante KNNW-Big Data, alrededor de 25000 instancias a procesar en cada iteración de las distintas bases de datos. Partiendo de 4 particiones para 100000 instancias hasta 20 map para la base de datos original de 578764 instancias. En la Tabla 6 se muestra la calidad de los resultados obtenidos por ambos algoritmos, donde a mayor valor mejor calidad obtenida. En la tabla se puede apreciar como la variante big data obtiene mayor área bajo la curva que el KNNW para cada base de datos. Esto se debe a que las instancias anómalas que no pasaron a la segunda fase del algoritmo obtuvieron un mayor valor de índice de anomalía. Ocasionando que las anomalías ocuparan un mejor puesto en la lista de posiciones. El alto índice de anomalía se debe a que en las particiones donde se encuentran las instancias, no aparecen sus vecinos cercanos o algunos de ellos.

En la Figura 5 se muestra la relación entre el área bajo la curva ROC y el número de instancias para los algoritmos KNNW y KNNW-Big Data en cada base de datos. Donde se puede apreciar una mejor representación de la comparación de ambos algoritmos con respecto al área bajo la curva ROC. El área del algoritmo KNNW-Big Data aumenta a la par que se incrementan la cantidad de instancias. Pero disminuye para la base de datos kdd99_400000, lo que se puede interpretar que las nuevas instancias normales que se incorporaron pueden presentar un mayor índice de anomalía que instancias anómalas. Esto se debe a que en las particiones de estas instancias no se encuentran sus vecinos cercanos. Además, su índice de anomalía puede no ser ajustado en la segunda fase porque no fueron seleccionados. Lo que influye en la disminución del área bajo la curva ROC.

Fig. 5 Relación entre el área bajo la curva ROC y el número de instancias para los algoritmos KNNW y KNNW-Big Data.
La Tabla 7 describe los resultados de ambos algoritmos con respecto al tiempo de ejecución en cada base de datos. Donde se puede observar a primera vista que los resultados del algoritmo KNNW-Big Data ofrecen menores tiempos de ejecución que los resultados del KNNW. También se aprecia que a medida que aumenta la cantidad de registros, los tiempos de ejecución en ambos algoritmos se incrementan. Por lo que los tiempos de ejecución se corresponden con la cantidad de instancias de las bases de datos de forma proporcional. Se muestran valores de medidas de rendimiento del tiempo de ejecución del algoritmo big data respecto al algoritmo KNNW.
A pesar de que ambos algoritmos no sean equivalentes, se utilizó al KNNW como referencia para determinar los valores de medida de esta tabla. Con el fin de tener una visión más amplia del comportamiento del tiempo de ejecución del algoritmo KNNW_Big Data. Una de las medidas que se describe es la aceleración, que demuestra que tan rápido es el KNNW_Big Data, llegando a ser hasta 31 veces más rápida. Por último, se observa la eficiencia del algoritmo MapReduce, demostrando hasta un 155% del uso de los recursos de los procesadores.

En el caso de la Figura 6 se representa la relación grafica entre el tiempo de ejecución en milisegundos y el número de instancias para los algoritmos KNNW y KNNW-Big Data que se muestran en la Tabla 7. En esta representación se puede observar como el crecimiento del tiempo del algoritmo KNNW tiende a ser acelerado. Por otra parte, se puede comprobar como la diferencia de tiempo de ejecución entre KNNW-Big Data y KNNW es mayor conforme el tamaño de los datos aumentan aumenta.

B. Experimentos con datos de una compañía de Telecomunicaciones
Para este experimento con KNNW-Big Data se asignó para la variable de entrada K=10 Y p=0.01 la cual representa a los K vecinos más cercanos. Las características de los recursos utilizados es un clúster de computadoras que está montado sobre el sistema operativo CentOS7 sobre el cual se encuentra instalado DCOS 1.9. Respecto a recursos se posee 64 cores y 40GB RAM, de los cuales están disponible 32 cores y 20 GB de RAM.
Se utilizó como fuente de datos primaria aproximadamente 500000 transacciones de operaciones de la compañía, la Tabla 8 muestra los datos primarios utilizados

Se realizó un experimento sobre las transacciones de la compañía que tenían presente múltiples operaciones, para un total de 450236 instancias. Los datos se cargaron desde un sistema de archivos distribuidos y el algoritmo se configuro con el valor de k=10 y un umbral del 0.01.
Para las 450236 instancias analizadas se determinaron 513 anomalías en un tiempo de 25 minutos aproximadamente (1519 segundos). La calidad del algoritmo fue validada por un experto en el problema donde se obtuvo como resultado que:
Las 10 instancias más anómalas obtenidas por el algoritmo coincidían con instancia de elementos que eran sospechosos de realizar operaciones anómalas y estaban marcados como posibles instancias fraudulentas.
En las primeras 100 instancias de las anomalías obtenidas se determinó un nivel de efectividad de aproximadamente el 70%.
Se obtuvieron más instancias anómalas por el algoritmo, pero quedaron pendiente de verificar su estado anómalo por un experto debido a que se desconocía el comportamiento de dichas instancias.
El algoritmo demostró alta eficacia y eficiencia en el análisis de los datos de operaciones.
C. Optimización del algoritmo
Para la mejora del algoritmo KNNW-Big Data respecto a los tiempos de ejecución y de la capacidad del tamaño de datos que se podía analizar se realizaron diferentes cambios sobre el mismo para mejorar sus tiempos de ejecución.
Después de cada fase de map del algoritmo se especificó un nivel de persistencia en disco y memoria.
Se cambiaron las estructuras de datos necesarias a arreglos que posean un tiempo de acceso constante a cada elemento en la estructura.
Se determinó que ejecutar el algoritmo con menor cantidad de datos por partición disminuye significativamente el tiempo de ejecución, se recomienda aproximadamente 10000 elementos por partición.
Con los nuevos cambios y los datos de la compañía también se realizaron pruebas de rendimiento donde se replicaron los datos originales hasta alcanzar los 15 millones de transacciones. El experimento de rendimiento utilizo K=10, P=0.01 y el particionado se determinó un total de 10000 elementos por partición. La siguiente tabla muestra para cada replica de datos realizada los tiempos de ejecución alcanzados por el algoritmo.

La tabla anterior nos permite observar que las mejoras realizadas al algoritmo big data anteriormente expuestas nos permite procesar aproximadamente 4 veces más datos que la versión inicial del algoritmo big data. Inicialmente con 450 000 instancias tardaba 25 minutos y con las mejoras analiza 2 millones en 23 minutos lo que significa una mejora de 4 veces la velocidad de análisis.
V. Conclusiones
Con los experimentos anteriores se confirma que la versión big data obtiene mejores resultados que la versión secuencial en cuanto a calidad de los resultados y tiempo de ejecución. Esta versión big data también permite el análisis de volúmenes de datos que anteriormente era imposible su análisis en un ordenador común. Con los resultados obtenidos se mejoró el tiempo de ejecución del algoritmo KNNW. Para ello se debe tener en cuenta el valor del umbral que puede afectar en el tiempo de ejecución del algoritmo, así como en la calidad de los resultados. Dado que el umbral puede dejar sin reajustar si se selecciona un valor muy bajo a posibles candidatos anómalos, por eso se recomienda utilizar 0.01. El algoritmo propuesto demuestra que en entornos reales tiene una alta eficacia en la detección de anomalías en datos no etiquetados y que posee un tiempo de ejecución acorde al volumen de datos que se analiza. En los experimentos realizados se obtuvo como resultado que especificar 10000 elementos por partición mejoraba considerablemente los tiempos de ejecución del algoritmo sin incidir en la calidad de los datos.

