











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares en
SciELO
Similares en
SciELO  Similares en Google
Similares en Google 
 Permalink
PermalinkIntroducción
La cobertura del suelo hace referencia a la información del material físico en la superficie de la tierra y el uso del suelo se asocia a las modificaciones hechas sobre esta cobertura por el hombre. La detección de cambios de cobertura o uso, es el proceso de identificar los cambios en un área o fenómeno ambiental mediante la observación en diferentes momentos de tiempo (Berberoglu et al., 2009). La clasificación de cobertura del suelo es importante para estudios de cambio climático y monitoreo de servicios ecosistémicos (Rodriguez et al., 2012) además de ser vital en los estudios del cambio climático global, fenómenos naturales, monitoreo y cuantificación de recursos, entre otros (Backoulou et al., 2015; Bokusheva et al., 2016; Eisavi et al., 2015).
La clasificación de coberturas del suelo, consiste en estimar los tipos de coberturas en un área determinada ya sea usando observación visual o métodos computacionales. La clasificación de coberturas, es aplicada a cartografía (Eisavi et al., 2015), monitoreo de recursos naturales (Chen et al., 2006), cambios en la biodiversidad de un área analizando los índices de vegetación (Bokusheva et al., 2016) y monitoreo de cultivos en busca de infecciones (Otukei et al., 2010).
El procesamiento de información adquirida mediante teledetección se ha utilizado para el estudio de las coberturas del suelo, en especial las imágenes satelitales (Shao et al., 2012). La teledetección usa la reflectancia de la tierra para obtener información de los materiales y características de su superficie (Warner et al., 2009). Gracias a la resolución espacial y espectral de las imágenes adquiridas, se puede cubrir áreas extensas y gracias a las bandas que poseen de las regiones del espectro electromagnético (usualmente de 2 a 10 bandas espectrales multiespectrales), se pueden estudiar aspectos fenológicos de la cobertura terrestre. Las imágenes de satélite se estudian como la representación visual de la reflectancia de la tierra adquirida por el sensor particular, en donde se han desarrollado procedimientos de representación de esta información, como las firmas espectrales y los índices de vege-tación. Las principales regiones espectrales utilizadas para el estudio de la superficie de la tierra son: visible (Azul, Verde, Rojo), infrarrojo cercano, infrarrojo de onda corta, infrarrojo de onda media, infrarrojo de onda larga o térmico, microondas y radar (Schowengerdt, 2007).
La clasificación de tipos de cobertura del suelo es una tarea que demanda capacidad de cómputo, debido a la gran cantidad de datos que se tiene que procesar, por lo cual, se establece la necesidad de aplicar métodos computacionales suficientemente rápidos y efectivos. El aprendizaje computacional es una rama de la inteligencia artificial cuyo objetivo es desarrollar técnicas, métodos y algoritmos que permiten que los computadores aprendan a reconocer patrones a partir de datos de un modelo de inferencia con propósitos predictivos (Alpaydin, 2014). Estos métodos son cada vez más utilizados en la clasificación de imágenes de teledetección en aplicaciones de monitoreo de recursos naturales (Mishra, 2015).
Entre los tipos de algoritmos de aprendizaje automático se destacan dos, el aprendizaje supervisado y el aprendizaje no supervisado. El aprendizaje supervisado ocurre cuando se proporciona al modelo de entrenamiento datos conocidos, es decir cuando se sabe a qué clase pertenece cada uno. De hecho, estos algoritmos han sido ampliamente utilizados en la clasificación de coberturas del suelo como es el caso de las máquinas de soporte vectorial (Wang, 2013). En los algoritmos de aprendizaje no supervisado el modelo de entrenamiento está formado por entradas y no se tiene información a qué clase pertenecen los datos, por lo tanto, su objetivo es agrupar los datos por características o patrones similares en un número definido de clases.
Con el fin de disminuir el costo y el error humano, se han investigado métodos computacionales para mejorar el rendimiento y la precisión de la clasificación de coberturas del suelo (Thonfeld et al., 2011) Previamente se han empleado entre otros métodos de aprendizaje computacional: los árboles de decisión (Rodríguez-Galiano et al., 2012), las cadenas de Markov (Halmy et al., 2015), la diferenciación de imágenes y cambio del vector de análisis (Berberoglu et al., 2009), determinados a través de la matriz de transición de los mapas de cobertura (Romero-Ruiz, 2012), el análisis de componentes principales (ACP) (Romero et al., 2012), las firmas espectrales y los índices de vegetación (Backoulou et al., 2015).
El método de clasificación automática de Máxima Verosimilitud (en inglés, Maximum Likelihood ML) ha sido uno de los más usados en los últimos 40 años en coberturas de la tierra (Warner et al., 2009), (Otukei et al., 2010). En la actualidad, los algoritmos de aprendizaje computacional como las máquinas de soporte vectorial (en inglés, Support Vector Machine SVM) y Bosques Aleatorios (en inglés, Random Forest - RF), han sido ampliamente utilizados para la clasificación automática con resultados de precisión general de 86.5 % (Eisavi et al., 2015) y 95.10 % de precisión de clasificación (Liu et al., 2013). Entre las medidas de desempeño y evaluación en la clasificación de coberturas y uso del suelo se utiliza el coeficiente de Kappa de Cohen (Wang et al., 2016) y en algoritmos de aprendizaje computacional se utiliza el promedio de exactitud sobre la matriz de confusión de los datos de salida (Al Obeidat, 2015).
Las Redes Neuronales Convolucionales (en inglés Convolutional Neural Networks CNN), son un método bio-inspirado de aprendizaje computacional, y han demostrado ser eficientes en diferentes áreas, como en el reconocimiento de voz (Huang, Li, y Gong, 2015), así como en clasificación automática de imágenes de personas por género, ropa inferior y superior (Perlin et al., 2015), aplicaciones en imágenes médicas como en la detección de cáncer de mama invasivo (Wang et al., 2014), (Cruz-Roa et al., 2014) y diferenciación de tumor meduloblastoma (Cruz-Roa et al., 2015).
En Colombia, la investigación de métodos automáticos para la creación de mapas de coberturas de suelo es escasa; el alto costo y el tiempo invertido en su creación están vinculados a la calidad y disposición de imágenes de productos de sensores remotos satelitales, y al juicio del profesional a cargo de la realización del mapa (IDEAM, IGAC, & CORMAGDALENA, 2008). Como ejemplo de estos procedimientos de gran esfuerzo, se tiene la información de los mapas de Parques Naturales Nacionales (PNN) de Colombia (Acevedo, 2012) y del Sistema de Información Ambiental de Colombia (SIAC) (Axesnet S.a.S, 2012); que son utilizados en esta investigación.
Este trabajo presenta el desarrollo y evaluación de un método computacional basado en redes neuronales convolucionales para la clasificación de suelos con la definición de clases del segundo nivel: bosques, áreas con vegetación herbácea y/o arbustiva, áreas abiertas, sin o con poca vegetación y áreas húmedas continentales. Clases definidas por leyenda nacional de coberturas de la tierra metodología CORINE Land Cover, adaptada para Colombia, escala 1:100.000 (Ministerio del Medio Ambiente, 2010).
El método propuesto empieza con la construcción de un conjunto de entrenamiento con el mapa de cobertura de suelo del parque nacional el Tuparro realizado por PNN, con el cual se entrenó una Red Neuronal Convolucional de arquitectura ConvNet, mientras que en el conjunto de validación se evaluó con los mapas de coberturas del Amazonas del 2007 realizado por el SIAC. De esta forma, se generaron predicciones de mapas de cobertura con el modelo entrenado y validado de la ConvNet.
El artículo está divido en secciones, en Materiales y Métodos se presenta la metodología de la técnica propuesta para la clasificación de las coberturas del suelo, así como el conjunto de datos generados para el entrenamiento y validación para la CNN, en Resultados se presentan los resultados obtenidos en gráficas y tablas, mientras que en la sección Discusión se analizan estos resultados obtenidos de los experimentos realizados. Finalmente, en la última sección Conclusiones se dan a conocer las principales conclusiones del método de clasificación y mapeo automático de coberturas del suelo en imágenes satelitales utilizando redes neuronales convolucionales.
Materiales y métodos
Método computacional para la clasificación de coberturas del suelo a partir de imágenes satelitales
La implementación de las CNN en la tarea de clasificación de coberturas del suelo presenta un reto completamente nuevo y diferente a los trabajos anteriormente mencionados, con pocos o ningún trabajo realizado en el área de coberturas de suelos, por lo que en esta sección se describirá la metodología utilizada para la implementación de las CNN, desde la generación del conjunto de entrenamiento y validación hasta la implementación y comparación con métodos tradicionales actuales.
Para el desarrollo de este trabajo se realizó el procedimiento explicado en la Figura 1. Inicialmente se diseñó e implementó un algoritmo de preprocesamiento de la información espectral de imágenes satelitales Landsat 5 TM que permitiera obtener los mapas útiles como conjunto de entrenamiento y validación, teniendo en cuenta los aspectos relacionados con la georreferenciación y la corrección de defectos tanto en imágenes como en mapas de insumo. Luego se desarrolló la etapa de extracción de muestras de regiones cuadradas de terreno de las clases sobre las imágenes satelitales para la generación del conjunto de entrenamiento y validación. Posteriormente, se realizó el algoritmo de CNN para los procesos de entrenamiento y validación para poder entrenar el modelo final. Finalmente se realizaron predicciones de mapas de cobertura con el modelo de la CNN y se calculó la similitud entre los mapas reales anotados por expertos y los generados automáticamente.
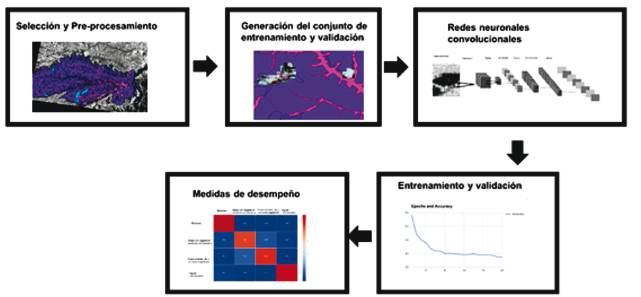
Selección y Preprocesamiento
Se utilizó información de cobertura correspondiente a mapas del parque el Tuparro realizado el 2007 por Parques Nacionales Naturales de Colombia (PNN).y los mapas de coberturas del Amazonas del 2007, realizados por el Sistema de Información Ambiental de Colombia (SIAC). Los mapas utilizados en este proyecto se pueden observar en la Figura 2. Se descargaron las imágenes satelitales utilizadas para realizar estos mapas de cobertura compuestas por imágenes Landsat 456 21/01/2008, las cuales se utilizaron como insumo para el mapa del parque el Tuparro. De la misma manera para el mapa de cobertura del Amazonas del 2007, se descargaron las imágenes Landsat 658 2008/04/08, que cuentan con cobertura de áreas de interés para el estudio. Para garantizar que la información corresponda espacialmente, se homogeniza el sistema de referencia de coordenadas (SRC) de imágenes y mapas a Magna-Sirgas de Colombia. El mapa del parque el Tuparro y la imagen satelital se le asignó el SRC Magna-Sirgas 3118 y a las demás imágenes y mapas se le asignó el SRC Magna-Sirgas 3117. Las imágenes Landsat 658 2008/04/08 y Landsat 456 21/01/2008 contenían píxeles con gran cantidad de nubosidad, lo cual introducía errores a la hora de procesar la imagen. Por lo tanto, se utilizó el programa QuantumGIS1 para la eliminación de las áreas que coincidían con las que corresponden con estos comportamientos. Con la ayuda del programa ENVI2 se realizó la corrección atmosférica de las imágenes utilizadas en este trabajo y por último se calculó la media y desviación estándar de los datos de entrenamiento. Esta información es necesaria para los procedimientos de normalización de los datos.
Extracción de muestras
(regiones cuadradas o parches)
El conjunto de entrenamiento se generó utilizando el mapa del parque el Tuparro con un área de total de 5,564 km2 del cual se utilizaron 4,299 km2 para realizar la extracción de parches (muestras de las clases) de 20 x 20 píxeles. Para realizar la extracción de los parches se realizó un algoritmo en el lenguaje de programación Python, el cual se encarga de leer las imágenes satelitales y los mapas de cobertura. Los mapas se separaron por clases y se desarrolló el procedimiento de extracción de parches de 20 x 20 x 7 píxeles (Ancho, Alto, Bandas), con pasos (strides) de 20 píxeles menos el solapamiento de 50 %, se verificaba que los parches cuadrados tuvieran al menos un 80% de su área perteneciente a una clase, de acuerdo con las regiones anotadas por los expertos en el conjunto de entrenamiento, para que el parche sea asociado a la clase. Para las clases Áreas abiertas, sin o con poca vegetación y Áreas húmedas continentales se les hizo un sobre-muestreo y solapamiento del 80% entre muestras, debido a que las áreas de interés eran muy pequeñas o delgadas (cuando correspondían a ríos). A cada parche de las clases Áreas abiertas, sin o con poca vegetación y Áreas húmedas continentales se le realizaron rotaciones de 90 grados e inversiones para generar 8 parches adicionales por clase. A la clase Áreas con vegetación herbácea o arbustiva, no se le realizó solapamiento para la extracción de muestras, debido a que era la clase que tenía mayor cantidad de área. Se generó un total de 56,935 parches, correspondientes a 683.22 km2; el número de parches por clases se aprecia en la Tabla 1. Los parches generados no son diferenciables a simple vista ya que las imágenes satelitales de cada banda están representadas en escala de grises, como se observa en la Figura 3.

Fuente: Autores.
Figura 3 Imagen del satelite Landsat TM 5. B: Azul, G: Verde, R: Rojo, NIR: infrarojo cercano, IIR: Infrarojo intermedio, TIR: Infrarojo termico y MIR: Infrarojo medio.

Los parches generados de cada clase contienen las siete bandas de la imagen original como se puede apreciar en la Figura 4. Los parches sin información en alguna de sus bandas son desechados. El conjunto de entrenamiento para la CNN necesita estar balanceado (i.e. similar proporción de parches de ejemplo por clase) para que el modelo predictivo no se incline a la clase con el mayor número de muestras (sobreentrenamiento). Por lo tanto, se descartaron datos de algunas de las clases para obtener una cantidad de parches por clase más homogénea, tal como se observa en la Tabla 2.


La información que se utilizó para elaborar el conjunto de validación corresponde a áreas de interés del mapa de cobertura del Amazonas del 2007 con una extensión total de 7,243 km2; se corrió el algoritmo para la extracción de parches generando un total de 21,584 parches, distribuidos como se muestra en la Tabla 3.

Note que el conjunto de validación no tiene que ser balanceado. Se calcula la media y desviación estándar de todos los parches de entrenamiento para realizar una normalización puntual estándar sobre todos los parches tanto de entrenamiento como de validación.
Red neuronal convolucional
Las redes neuronales convolucionales son el estado del arte en la clasificación automática de imágenes naturales (Krizhevsky et al., 2012). Las CNN tienen una fase de extracción de características y de clasificación. La extracción de características consta de una capa de convolución de la imagen de entrada con el filtro (kernel) con un número determinado de neuronas y una capa de sub-muestreo o pooling, en la cual se reduce la salida de la convolución. Posteriormente continúa una etapa de reducción de dimensionalidad y selección de características relevantes por medio de la capa de Fully-connected, y finalmente el modelo entrenado clasifica a qué clase pertenece una imagen en particugation) usando el gradiente estocástico con la CNN, el cual ajusta los pesos de los filtros y reduce el error de clasificación.
Las CNN requieren de conjuntos de datos de entrenamiento grandes, con el fin de ser más robustas a la hora de clasificar automáticamente. También es necesario que los datos de las clases estén balanceados si es un problema de múltiples clases. Tensorflow3 es una librería de código abierto de Google que fue seleccionada como herramienta de trabajo para elaborar el algoritmo de aprendizaje automático de CNN de arquitectura ConvNet con el fin de entrenar un modelo para la clasificación de coberturas. El algoritmo cuenta con dos capas de convolución y pooling. La primera capa realiza la convolución entre la imagen de entrada y el filtro (kernel) donde la imagen de entrada es de 20 x 20 x 7, donde siete es el número de bandas de la imagen satelital, el filtro de 5 x 5 x 7 @ C1 donde C1 es el número de neuronas por capa. A continuación, se realiza la etapa de pooling que para este caso corresponde a la función de Max-pooling, que hace un submuestreo eligiendo los valores máximos de la imagen en una ventana de 2 x 2. Se realiza una vez más las etapas de convolución y pooling, esta vez la convolución se realiza con los datos de la primera convolución y pooling de tamaño 8 x 8 x 7 @ C1 y un segundo filtro kernel de 5 x 5 x C1 @ C2 donde C2 es el número de neuronas de la segunda capa, otra capa de Max-pooling y por último se aplica la capa de neuronas totalmente conectadas (en inglés fully connected) que serían los datos que entran en el clasificador. Los parámetros definidos para entrenar la CNN se pueden ver en la Tabla 4.

Entrenamiento
Para realizar el entrenamiento de la CNN se desarrolló un módulo en Python que lee los conjuntos de datos, un 10% para probar el rendimiento de la CNN en entrenamiento y el resto para entrenar el modelo. Devuelve un objeto con atributos (imágenes y etiquetas) con un método que retorna un lote de estos parámetros, los cuales entrarán a la CNN; una vez completada un ciclo o época, los datos se barajan y vuelven a pasar por la CNN hasta completar el número de once épocas. La primera fase de entrenamiento se realizó a lo largo de once épocas, una época es cuando todos los datos de entrenamiento pasan por la CNN, en la época número once se realizó una prueba de rendimiento sobre los datos de entrenamiento y validación sobre sus matrices de confusión como se puede apreciar en la Figura 5.

Fuente: Autores.
Figura 5 Matriz de confusión para las primeras 11 epocas. a: clase bosques, b: áreas con vegetación herbácea o arbustiva, c: áreas abiertas sin o con poca vegetación y d: áreas húmedas continentales [Izquierda Entrenamiento / Derecha Validación].
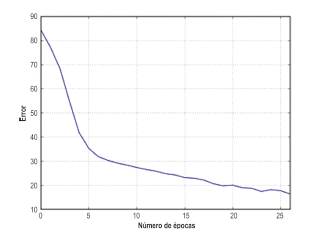
Se continuó entrenando el modelo hasta llegar a la época 27, donde se alcanzaron los datos con mejor desempeño de entrenamiento y validación como se muestra en la Figura 6. Al no encontrar mejora en los resultados obtenidos se detiene el procesamiento, observando una disminución en el error cuadrático medio (EMC) de la clasificación conforme transcurre cada época, como se aprecia en la Figura 7.

Fuente: Autores.
Figura 6 Matriz de confusión para la epoca 27. a: clase bosques, b: áreas con vegetación herbácea o arbustiva, c: áreas abiertas sin o con poca vegetación, d: áreas húmedas continentales [Izquierda Entrenamiento / Derecha Validación].
Clasificación vista al vuelo
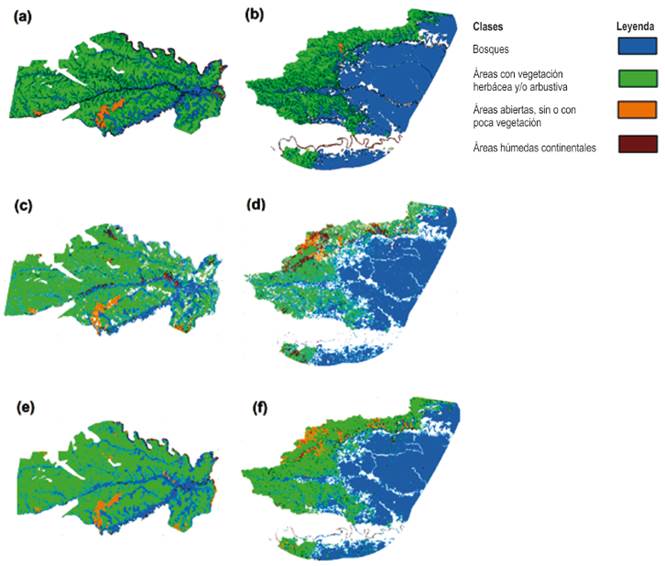
Con el modelo de la CNN entrenado se realizó la predicción a vista de vuelo de los mapas de coberturas de las imágenes del Amazonas 2007. Se recorría la imagen cada 10 píxeles y se corría el modelo de la CNN sobre una porción de la imagen devolviendo las coordinas del punto y la predicción del modelo. Con las coordenadas y predicciones de las clases se implementó una interpolación de vecinos cercanos, así mapeando el nuevo mapa predicho por la CNN como se muestra en la Figura 8. Con los mapas realizados con la CNN se calculó el coeficiente de Dice para medir la similitud de los mapas reales con los predichos como se puede ver en la Tabla 4. De esta forma, poder comparar la eficiencia del modelo de la CNN en clasificación y mapeo.
Clasificación de cobertura del suelo usando firma espectral
Las firmas espectrales han sido usadas para identificar un amplio tipo de coberturas (Martin et al., 1998). Con el fin de comparar los mapas predichos con la CNN usando métodos de clasificación tradicionales sin aprendizaje computacional, se realizó una clasificación usando las firmas espectrales de las clases usadas para entrenamiento. Se utilizó en algoritmo de distancia mínima, el cual clasifica a cada píxel y calcula la distancia mínima entre la firma espectral del píxel y cada clase, para asignar la pertenencia del píxel a la clase más cercana (Rujoiu-Mare et al., 2016). Se clasificó y mapeó un mapa con este procedimiento como se aprecia en la Figura 8.
Fuente: Autores
Figura 8 Comparación de mapas originales y los métodos computacionales usados para predecir mapas de cobertura con la CNN y con el procedimiento de firmas espectrales. Mapas utilizados en el estudio. a) Área de interés del mapa de coberturas del Amazonas 2007. b) mapa del Parque Nacional el Tuparro. Fuente: (Acevedo, 2012), (Axesnet S.a.S, 2012), c) y d) Mapas correspondientes a la clasificación usando firmas espectrales algoritmo de distancia mínima, e) y f) Mapas correspondientes a la clasificación usando CNN.
Se utilizó la exactitud promedio sobre la matriz de confusión, la cual muestra el rendimiento por clases de los modelos entrenados previamente y también se determinó la desviación estándar de la diagonal de la matriz de confusión para apreciar el grado de dispersión de exactitud de la CNN entre las clases. Se utilizó el coeficiente de Dice para comparar la similitud de los mapas predichos con el modelo entrenado de la CNN y los mapas reales anotados por expertos, como se muestra en la Tabla 5.

Resultados
Se alcanzó un máximo de 83.27% de exactitud promedio sobre los datos de entrenamiento y un 91.02% en validación sobre sus matrices de confusión en parches como se muestra en la Figura 5. Se alcanzó un máximo de 88.7% de similitud al mapa real en la clasificación al vuelo y mapeo sobre la clase 1, un 77.4% en la clase 2, y unos valores mínimos en las clases 3 y 4 de los cuales se discutirán en la siguiente sección. Los coeficientes de Dice del mapa generado por la CNN son mayores a los coeficientes de Dice del mapa generado por las firmas espectrales y el algoritmo de distancia mínima como se aprecia en la Tabla 5.
Discusión
Los resultados finales obtenidos en rendimiento son altos para el procedimiento realizado con Redes Neuronales Convolucionales. La clasificación y mapeo de las clases 3 y 4 aunque funcionan en parches, en la aplicación práctica son muy difíciles de identificar debido a factores relacionados con la extensión espacial ocupada y la peculiaridad de sus formas, como lo es la clase 4 de áreas húmedas continentales, que hace referencia a los ríos. Las características estructurales y de forma de la clase 4, lo que hace difícil para nuestro modelo poder encontrar un río con un área de forma cuadrada de 600 m2, ya que generalmente esta clase se extiende a lo largo y muy poco a lo ancho.
La CNN en trabajos anteriores ha demostrado buenos resultados en conjuntos de datos grandes (Krizhevsky et al., 2012), por lo tanto, una cantidad de datos de entrenamiento mayor tiene el potencial de poder mejorar la clasificación y así poder aumentar el promedio de exactitud a 91.02% en validación. Los resultados obtenidos presentan respuestas acertadas y muestran avances en la aplicación de las CNN en la clasificación de coberturas de suelo, comparados con trabajos previos de clasificación de coberturas donde se logró 91.8% de precisión general (Eisavi et al., 2015)with various phenological patterns from satellite imagery, is a particularly challenging task. However, supplementary information, such as multitemporal data and/or land surface temperature (LST o un 95.10% de precisión global (Liu et al., 2013). Solo habiendo probado la arquitectura más básica de las CNN y variado unas cuantas variables de las muchas posibles en este problema, indica la posibilidad de lograr obtener mejores resultados continuando con la optimización de las técnicas de preprocesamiento y procesamiento empleadas en este estudio.
Conclusiones
Se logró entrenar un modelo de aprendizaje de redes neuronales convolucionales para la clasificación de co-berturas de la tierra capaz de distinguir entre 3 clases de bosques, áreas seminaturales y una clase de superficies de agua.
Se desarrolló un módulo para la extracción de parches que tiene métodos de lectura de imágenes y mapas de coberturas, con el cual se generó el modelo de entrenamiento y validación. Además, se generó un módulo de lectura y generación de objetos para el ingreso de lotes de imágenes y etiquetas de las clases a la CNN. Y por último un algoritmo de aprendizaje computacional de arquitectura ConvNet, el cual entrenó el modelo predictivo con un promedio de exactitud del 83.27% en entrenamiento y 91.02% en validación.
La resolución espacial y espectral es un factor determinante en la investigación de clasificación automática de cobertura del suelo. Se puede concluir que el procedimiento con CNN es capaz de clasificar satisfactoriamente coberturas de suelo, al compararlo con un método clásico de clasificación usando firmas espectrales mediante el algoritmo de distancia mínima.
Se planea trabajar con más arquitecturas de redes neuronales buscando lograr la clasificación de más clases de coberturas, además de realizar pruebas de validación de resultados mediante el uso de mapas de coberturas e imágenes de sensores remotos de otros estudios realizados en Colombia o a nivel internacional.

