











 Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares em
SciELO
Similares em
SciELO  Similares em Google
Similares em Google 
 Permalink
Permalink
I. INTRODUCTION
Artificial vision is a relevant research field that involves multiple applications, such as robotics, industrial processes, and devices for people with visual disabilities, among others. Artificial vision is contained within the artificial intelligence field, which makes use of different algorithms, techniques, and methods, achieving the processing of information contained in digital images. In particular, in order to provide a solution to object recognition, multiple algorithms have been proposed [1], which involve different morphological operations allowing to adapt the captured images, which have high variability due to: i.) light conditions, ii.) device for capturing the image, and iii.) object itself, among many other possibilities. Additionally, the proposed methodology involves artificial intelligence algorithms, particularly Hopfield´s neural networks [2,3,4,5,6,7,8,9,10].
Then, it becomes necessary to propose an artificial vision algorithm that recognizes objects collection, such as polyhedral and non-polyhedral, under variable luminosity conditions. The proposed procedure involves two main phases: i.) capture image processing, and ii.) neural network application. First step images are reduced and adjusted, following this procedure: i.) Segmentation, ii.) Intelligent recognition, iii.) feature extraction. The second step is related to the use of a Hopfield neural network, and it is trained with patterns, then new images are presented to the network; it will automatically and autonomously recognize objects presented. Consequently, the article is divided into three sections; first, the methods and materials are introduced, detailing the digital processing of images and the artificial intelligence model. Then the results section shows the experimental procedure to validate the model, testing the artificial intelligence system. Finally, the discussion and conclusions section is presented.
II. METHODS AND MATERIALS
Conventionally the recognition of objects in a scene is achieved by digital image processing [11], whose purpose is directly related to artificial vision or computer vision. Artificial vision aims to detect, segment, locate, and recognize particular objects. Thus, the following methodology is proposed: (a) segmentation, (b) intelligent recognition, and, (c) extraction of characteristics.
A. Segmentation
The proposed image processing consists of converting the image to grayscale, obtaining a lighter image format. To obtain a lighter image format is needed to convert on grayscale images. Then, edges of the images are detected by the derivative method; before the image is enlarged and eroded to close the found edges. Finally, the borders are filled, achieving a mask that identifies the position of the object inside the image. Each step is described in detail below:
1) Greyscale Transformation. It consists of determining the equivalent of the luminance, which is defined as the light received on a surface being defined as the relation of the luminous flux on the illuminated area [12], luminance concept is associated with human eye perception of different light intensity [13]. The luminance is calculated based on the weighted average of the color components of each pixel, as shown in Equation 1, where L corresponds to the luminance, R is the red component. G the green component and B the blue component.
 (1)
(1)
Equation 1 should be used for calculation grayscale to each pixel; this process is required for the image edge detection.
2) Images Edges Detection. The image obtained in the previous step can be represented as a discrete function in 2D, which is defined by the coordinates of each pixel m and n. The discrete value of the function is evaluated at a specific point; its procedure is known as brightness or pixel intensity. An edge is defined as tone changes between pixels, in cases where changes exceed a threshold value, it is considered an edge. Different methods to identify edges have been proposed, one of them is the intensity gradient of each pixel, using a convolution mask, then magnitude is calculated finally, the threshold process is applied [14].
The most used edge detection techniques employ local operators [15], using discrete approximations of the first and second of grayscales images, hereunder it will be described the proposed operator, which is based on the first derivative of the image.
3) First Derivative Operators.
The derivative of a continuous signal provides localvariations for the coordinate, so the obtained values are higher when variations arefaster. In the case of two-dimensional functions. 𝑓 (𝑥, 𝑦), The derivative is a vectorpointing in the direction of the maximum variation of 𝑓 (𝑥, 𝑦) and the module of whichis proportional to that variation. This vector is called gradient [16] and is defined as  its magnitude is defined as
its magnitude is defined as  and its address is given by
and its address is given by 
4) Morphological Operations. The contour and shape of objects are studied by morphology, applying a set of mathematical operations to images [17]. The sets represent the shape of the objects contained in an image, so to extract a geometric structure from a set, using known shape as structuring elements. Then, each pixel is compared with its neighborhood pixels [18]. The morphological operations commonly used are dilation and erosion, among others; these operations are described below.
5) Dilation. It allows increasing the size of the objects, reducing the size of the background, results depend on structural elements applied. For example, in order to expand the image shown in Fig. 1a, a red cross (+) was used as a structuring element, subsequently, the structuring element matchs with each of the elements of the input image, as shown in Fig. 1b, obtaining Fig. 1c the dilated pixels appear in pink, as shown in Fig. 1d.

6) Erosion. Erosion is a morphological operation that functions in a way similar to dilation but obtaining an inverse result. This process reduces the size of objects by extending the limits of the background and eliminating small objects.
7) Filling Edges. It consists of completing those rough edges, the edges are defined as the transition between two regions of considerably different levels of grey, from these, it is possible to determine the boundary or contour of an object.
Fig. 2 presents the synthesis of the image segmentation process. This methodology allows to identify the position of the object within the image, however, as observed in the right figure, the result of the segmentation is not forceful, and it is not yet possible to identify the edge of the object, being the system highly sensitive to errors, for this reason, the use of artificial intelligence becomes necessary.

B. Artificial Intelligence for Object Recognition
The image is reconstructed using a Hopfield neural network; the network eliminates noise in edge image, improving accuracy and precision, and obtaining a proper segmented image.
Artificial intelligence is known as "the science and engineering of making intelligent machines, especially intelligent computer programs", this definition was proposed by Professor John Mccarthy, in 1956 [19]. The target of artificial intelligence is to think, evaluate or act according to certain inputs to exercise some specific function, to achieve this, different processes could be performed: i.) Genetic algorithms, ii.) Artificial neural networks and iii.) Formal logic.
For the specific problem, artificial neural networks are employed, it uses elements information processors, where local interactions depend on overall system performance.[20] Networks consist of a large number of simple processing elements called nodes or neurons that are arranged in layers [21]. Each neuron is connected to other neurons by communication links, which have a weight associated. Weights represent the information that will be used by the neural network to solve a given problem [22]. Now, there are various types of neural networks, such as self-organization, recurrent, among others.
Hopfield Network is part of recurrent networks, which is a network of probabilisticadaptation, recurrent and with associative memory, it learns to reconstruct the inputpatterns memorized during training [23], patterns may be presented incompletely orwith noise. Also, Hopfield networks are characterized by the fact that each neuroncan be updated an indefinite number of times, independently of the rest of theneurons, and the network is interconnected in parallel. Figure 3 shows the structureof the Hopfield Network where N1, N2 and N3 corresponds to neurons, X isassociated with inputs, D corresponds to the distribution node, F is the activationfunction, 𝑙𝑖 is the input polarization, 𝑊𝑖𝑗 corresponds to the weights and finally 𝑌𝑖 isthe exit.

The model consists of a monolayer network with N neurons, with analog inputs and outputs, using neurons with activation functions F (Fig. 4), the mathematical model describing the behavior of the neural network is represented mathematically by equations 2 and 3.

 (2)
(2)
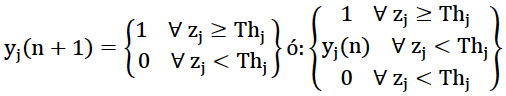 (3)
(3)
The Hopfield network employs the basic structure of individual Adaline perceptrontypeneurons. However, it departs from the usual neural network designs in itsfeedback structure. Note that a binary Hopfield Network of two neurons can beconsidered as a system of 2n state, i.e., 22, with outputs belonging to the set of fourstates {00, 01, 10, 11}. When the network receives an input vector, it will stabilize inone of the above states, and the output state will be determined by the networkweight configurations.
For the implementation of the Hopfield network, it is necessary to propose a modelof weights based on the self-associative memory [24], This is characterized becauseit presupposes that the input must approach a value stored in the memory in such away:  Achieving that for an arbitrary entry
Achieving that for an arbitrary entry  that is closer to x compared to anentry
that is closer to x compared to anentry  that is closer to x compared to an entry
that is closer to x compared to an entry  , obtaining equation 4.
, obtaining equation 4.
 (4)
(4)
In this way, the network weights will be calculated using equation 5.
 (5)
(5)
A partially incorrect input will produce in the network an output close to the most similar pattern stored in the memory, achieving a correct output in the presence of distorted information. This latter property makes the Hopfield Network the most suitable for the expected solution (Fig. 5) since the input is a partially incorrect image due to noise conditions, the output from the network will be the corrected image.

C. Feature Extraction
The feature extraction phase consists of dilating and eroding the image resulting from the Hopfield network, generating a new, improved mask that when applied to the original image will result in the segmentation of the image extracting the object to be analyzed (Fig. 6).

III. RESULTS
The proposed methodology was validated, carrying out an experiment, which evaluates the effectiveness. The materials are described below and the results obtained are presented.
A. Materials
1) Capture Device. A Handycam® Sony camera with Carl Zeiss® lens, ith optic zoom of 40x, DCR-HC52 reference, it was selected because it delivers 720 x 480 images, which is the right size to process the image quickly without loss of information. Also, the selected camera has self-calibration, allowing it to improve the focus. Additionally, the camera is fixed on a tripod, with a tilt of 33,75°.
2) Working Space. The working space consists of boxes of dimensions of the width of 47 cm, height of 40 cm, and depth of 38 cm, internally these were lined with papers of red, green and blue color because these are the basic colors (Figure 7). Inside were located three LED arrays: 3 x 4 white light, these arrays were located on the top, right and left side internally in the boxes, the arrays were located centered on each of the faces, the LED light was polarized to different voltages: 12v, 9v, 7.5v, 6v and 4.5v.

3) Objects. Two types of small and large objects were selected as follows: i.) Polyhedral: prismatic (Fig. 8), hexahedron, orthohedron and ii.) Non-polyhedral (Fig. 9).



C. Samples
150 images were taken, corresponding to prismatic, hexahedron and octahedron, cylindrical, and spherical objects. 5 different photographs were taken considering: i.) the intensity of light, represented in different voltages, when the voltage decreases, the images get darker, as the consequence noise is more significant. Samples of the photographs collected for prismatic objects are presented in Table 1.

IV. Discussion
A. Image Segmentation
The segmentation procedure was carried out on the 150 images see Figure 11, errors are highlighted in red, only 4 cases were not recognized. Therefore, uncertainty is 2,6% during noised image recognition. It is important to note that the errors occurred under the less favorable conditions when the light intensity was low, thus considering that the mathematical model worked properly, offering an acceptable response to light conditions, variable shape, and color.

B. Artificial Intelligence
Since the goal of the neural network is to reconstruct an unknown pattern, based on information stored in memory, a network with associative memory is required, this concept is quite intuitive, associating two patterns, the input pattern with one stored in memory, as explained above.
Segmented images measure 720x480 pixels, so the input vectors should measure 1x345600, and the weights matrix 345600x345600, these values are considerably high to be processed by a conventional computer. This is way before processing the image in the neural network, the image was dilated and its size was changed by reducing 10 times, the patterns used to train the network are shown in Figure 12.

The patterns shown have dimensions of 72x48 pixels, so the W weight matrix has a dimension of 3456x3456, so it is possible to process the network on a conventional computer.
C. Results
The tests of effectiveness on the neural network evidence that the network reconstructed the expected pattern, Figure 13 shows the matrix of confusion of the neural network, evidencing the capacity of classification of the network. Consequently, the only error of recognition of an object comes from the uncertainty of 2.6% found in the segmentation stage. Therefore, the complete methodology shows the overall efficiency of 97.4%.

V. CONCLUSIONS
The proposed methodology demonstrated to be able to identify basic shapes of objects from images; this methodology can be extrapolated to different applications, such as the grip of objects by using robotic arms, aids for visually impaired persons, among others.
On the other hand, the use of hybrid methodologies and image processing techniques combined with artificial intelligence techniques, specifically Hopfield network, constitutes an essential contribution in the area of artificial vision.

