











 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares em
SciELO
Similares em
SciELO  Similares em Google
Similares em Google 
 Permalink
PermalinkINTRODUCCIÓN
El valor en riesgo (VaR, por su sigla en inglés) se ha convertido en una de las medidas de riesgo de mercado más utilizadas por las entidades financieras. Esta medida corresponde a la mínima pérdida esperada en el (1-θ) 100% de los peores casos para un horizonte de tiempo específico (Becerra y Melo, 2006). De este modo, se puede suponer que la pérdida esperada de su inversión no será mayor al VaR con una probabilidad θ. En términos estadísticos, el VaR θ tt-1 es el θ-ésimo cuantil de la distribución de pérdidas y ganancias futuras del activo en el siguiente período. Su fácil interpretación y aplicación lo han convertido en una medida estándar de riesgo de mercado, tanto para entidades financieras como regulatorias.
Dada su relevancia, es necesario contar con metodologías confiables para la estimación del VaR. La mayoría de las metodologías utilizadas para su cálculo tienen en cuenta varios hechos estilizados de las series financieras. Sin embargo, algunas de las limitaciones que presentan las técnicas con enfoque paramétrico están relacionadas con los supuestos que se imponen sobre la distribución de los retornos de los activos financieros.
La regresión cuantílica es un método de estimación que permite lidiar con este tipo de limitantes. Este método permite calcular el cuantil condicionado de forma directa, sin necesidad de imponer supuestos sobre la distribución del término del error asociado al modelo. Además, sus estimadores son robustos ante datos atípicos. Es de notar que la especificación del cuantil condicionado puede incluir una especificación autorregresiva con la cual se pueden modelar de forma adecuada los conglomerados de volatilidad, como lo sugieren los hechos estilizados de las series financieras. Este tipo de modelos se pueden especificar mediante procesos CAViaR (conditional autoregressive value at risk).
En general, los modelos CAViaR presentan un buen desempeño en comparación a las técnicas tradicionales usadas en la estimación del VaR. Al respecto, Engle y Manganelli (2001) llevan a cabo simulaciones Monte Carlo para evaluar el desempeño tanto de métodos tradicionales como del CAViaR. Los resultados indican que estos últimos tienen un buen desempeño para casos en los que las distribuciones presentan colas pesadas. Por otra parte, Xiliang y Xi (2009) calculan el VaR para la serie de precios del petróleo Brent y WTI. Sus resultados muestran que los modelos CAViaR y los GED-GARCH son los que presentan mejor desempeño frente a otros modelos. En otro documento, Gaglianone, Lima y Linton (2008) proponen una nueva prueba de backtesting basada en regresión cuantílica y la implementan para evaluar el desempeño del VaR de la serie S&P-500 calculado por cinco métodos de estimación. En estos ejercicios, el modelo CAViaR es el único que no muestra indicios de mala especificación y tiene el mejor desempeño de acuerdo con funciones de pérdida.
En la literatura también se tienen trabajos que estiman el valor en riesgo usando métodos de regresión cuantílica aplicados a mercados financieros colombianos. Cabrera, Melo, Mendoza y Téllez (2012) estiman el VaR y el CoVaR para el portafolio de deuda pública de las entidades financieras de Colombia usando un modelo de regresión cuantílica con efectos ARCH. Por otro lado, Londoño (2011) realiza una aproximación del modelo CAViaR sobre el índice general de la bolsa de valores, con el fin de determinar los patrones que influencian el riesgo de mercado a través de un modelo de redes neuronales de regresión cuantílica. También, Londoño, Correa y Lopera (2014) estiman varios modelos incluyendo el CAViaR usando regresión cuantílica bayesiana para el mercado de valores colombiano. Sin embargo, en los dos últimos trabajos solo se modela una de las especificaciones CAViaR.
El objetivo de este trabajo consiste en estimar la familia de modelos CAViaR propuestos por Engle y Manganelli (2004), Kuester, Mittnik y Paolella (2006) y Koenker y Xiao (2009), para tres series financieras colombianas, el índice de mercado bursátil de la bolsa de valores (Colcap), la tasa de cambio respecto al dólar (TRM) y un índice de precios de títulos de deuda pública (IDXTES); para la muestra comprendida entre el período del 12 de diciembre del 2007 y el 20 de noviembre del 2015. Estas series están asociadas a tres de los principales mercados financieros de Colombia y, por tal motivo, es importante contar con medidas confiables de riesgo relacionado con estos mercados.
A diferencia de trabajos anteriores con aplicaciones a mercados financieros colombianos, los cuales se concentran en una sola especificación CAViaR análoga a los procesos GARCH, en este documento se estiman diversas extensiones de los procesos CAViaR. Una de estas permite modelar efectos relacionados con los comportamientos asimétricos, los cuales hacen parte de los hechos estilizados de las series financieras. Otra extensión considera la modelación del primer momento de la serie. Finalmente, otra estima el valor en riesgo a partir de procesos CAViaR representados por medio de modelos GARCH lineales. Estos últimos superan algunos limitantes de la metodología de estimación asociada a los procesos CAViaR tradicionales.
Los resultados de la aplicación realizada en este trabajo muestran que al comparar el desempeño de estos modelos frente a técnicas tradicionales se obtiene que las especificaciones CAViaR presentan, en general, un mejor desempeño en términos de funciones de pérdida.
Además de la presente introducción, el documento se compone de otras cuatro secciones. La segunda contiene una definición formal del VaR. En la tercera sección se expone la familia de modelos CAViaR, basados en regresión cuantílica lineal y no lineal, y sus metodologías de estimación. En la cuarta se muestra un ejercicio empírico en el que se aplican estos modelos. Finalmente, en la quinta sección se presentan algunas conclusiones.
VALOR EN RIESGO
El valor en riesgo es una medida de riesgo de mercado y se puede interpretar como la mínima pérdida posible bajo condiciones extraordinarias de mercado (Tsay, 2005).
Sea{r t } t=1,,T una sucesión de variables aleatorias asociada a un vector de retornos financieros. En este contexto, el VaR θ tt-1 corresponde al θ -ésimo cuantil de la función de distribución futura de los retornos de un activo financiero y está dado por:

Siendo F t (.) la función de distribución de r t Si esta función es conocida, el VaR se obtiene simplemente calculando el θ -ésimo cuantil:
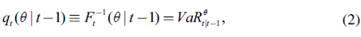
Donde F -1 t(θ|t-1) es la función inversa de la función de distribución de r t condicional a la información disponible hasta el período t-1 y se define como:

Existen diversas estrategias para estimar el VaR. El enfoque paramétrico se centra en modelar este cuantil de forma indirecta a través de momentos que caracterizan la distribución de r t . Además, este enfoque puede contemplar varios de los hechos estilizados de las series financieras, tales como la presencia de conglomerados de volatilidad, exceso de curtosis y efecto leverage, por ejemplo, usando modelos ARMA-GARCH. En general, el VaR se calcula para pérdidas extremas, asociadas a valores de θ ubicados en las colas de la función de distribución. Por tal motivo, algunas de estas metodologías utilizan la teoría de valores extremos.
Por otro lado, los modelos tipo CAViaR que se presentan a continuación se concentran en la estimación del cuantil de forma directa.
METODOLOGÍA
Esta sección se compone de dos partes. En la primera se describen los modelos de regresión cuantílica que son considerados en este documento, mientras que en la segunda se explican sus metodologías de estimación.
Modelos
Una de las primeras aproximaciones para estimar el valor en riesgo usando modelos de regresión cuantílica fue desarrollada por Koenker y Zhao (1996); esta metodología se basa en la modelación de cuantiles condicionados bajo la presencia de efectos ARCH.
Aunque los modelos ARCH tienen en cuenta ciertos hechos estilizados de las series financieras, realizan supuestos fuertes sobre las innovaciones del proceso, lo cual puede llevar a errores de especificación. Una forma alterna de realizar este tipo de modelación, sin este tipo de restricciones, es mediante regresión cuantílica con efectos ARCH.
Sea  una serie de retornos financieros definidos en la sección anterior. Adicionalmente, se supone que el proceso generador de los datos (DGP por su sigla en inglés) viene dado por la siguiente especificación:
una serie de retornos financieros definidos en la sección anterior. Adicionalmente, se supone que el proceso generador de los datos (DGP por su sigla en inglés) viene dado por la siguiente especificación:

Donde el término ũ t tiene la siguiente dinámica:

con  y
y  son variables aleatorias i.i.d con media igual a cero, varianza finita y con funciones de densidad y distribución
son variables aleatorias i.i.d con media igual a cero, varianza finita y con funciones de densidad y distribución  y
y  , respectivamente.
, respectivamente.
Con base en ello, el cuantil θ condicionado a la información disponible en t-1 está dado por:

A pesar de que esta metodología estima el cuantil directamente, no incluye una estructura autorregresiva 1. A continuación se muestran algunos modelos CAViaR que sí lo hacen y que, por lo tanto, pueden modelar directamente algunos hechos estilizados de las series financieras 2.
El proceso CAViaR (Engle y Manganelli, 2004).
Estos autores proponen modelar directamente el cuantil de una serie de retornos {rt}t=1,,T . Para ello definen  como un vector de variables observables del conjunto de información
como un vector de variables observables del conjunto de información  y
y un vector de parámetros desconocidos de dimensión p+q+1 El θ-ésimo cuantil de r
t
condicionado a la información disponible en t-1, se define como
un vector de parámetros desconocidos de dimensión p+q+1 El θ-ésimo cuantil de r
t
condicionado a la información disponible en t-1, se define como 
 .
.
De este modo, el proceso CAViaR asume que la dinámica de la evolución de los cuantiles en el tiempo es la siguiente:

Donde l(.) es una función de variables observables, x
t
. Los autores proponen cuatro formas funcionales de :
a) Adaptativo (CAViaR-AD):

Donde I(.) corresponde a la función indicadora.
b) Valor absoluto simétrico (CAViaR-SAV):

c) Pendiente asimétrica (CAViaR-AS):

con (x)+ ≡ max(0,x) y (x)- ≡ min(0,x).
d) GARCH(1,1) indirecto (CAViaR-IG) :

De este modo, en todas las formas funcionales se tiene una especificación autorregresiva del cuantil condicional. En particular, el modelo CAViaR-AD (por su sigla en inglés) descrito en (8) incorpora la siguiente regla de decisión: si la pérdida observada excede al VaR en el período anterior, el VaR se debe incrementar en el siguiente período. En caso contrario, el VaR deberá decrecer. A diferencia del modelo CAViaR-AD, las especificaciones CAViaR-SAV y CAViaR-AS incorporan la magnitud del retorno, donde esta última asigna una ponderación distinta dependiendo del signo de la serie en el período anterior.
Por otro lado, la especificación CAViaR-IG es utilizada si el proceso sigue un modelo de tipo localización-escala de la forma:

Con  sigue la especificación en (11). Kuester, Mittnik y Paolella (2006) relajan el supuesto de µ
t
=0, asumiendo que µ
t
=ar
t-1
en (12).
sigue la especificación en (11). Kuester, Mittnik y Paolella (2006) relajan el supuesto de µ
t
=0, asumiendo que µ
t
=ar
t-1
en (12).
Una forma de justificar la ecuación (11), incluyendo µ t =ar t-1 , es suponiendo el siguiente proceso sobre la desviación estándar condicional:

Al despejar  de la ecuación (12), y a su vez reemplazando este resultado en (13) y renombrando términos, se llega a la especificación del modelo CAViaR-IG, AR(1) - CAViaR-IG:
de la ecuación (12), y a su vez reemplazando este resultado en (13) y renombrando términos, se llega a la especificación del modelo CAViaR-IG, AR(1) - CAViaR-IG:

La estimación de los coeficientes de las ecuaciones (8) a (11) y (14) se lleva a cabo usando métodos de regresión cuantílica no lineal.
Sin embargo, estos modelos presentan algunos problemas relacionados con las propiedades de las funciones cuantílicas, principalmente la de monotonicidad que ocasiona el inconveniente de cuantiles cruzados (Gourieroux y Jasiak, 2008). En particular, solo el modelo CAViaR-SAV garantiza el cumplimiento de dicha propiedad, siempre que el cuantil condicionado se encuentre entre 0 y 1.
Cuantiles condicionales para modelos GARCH lineales (Koenker y Xiao, 2009)
En la estimación de los modelos expuestos anteriormente, los regresores 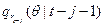 son latentes y dependen de parámetros desconocidos. Como consecuencia, la estimación por el método NLQR no es directamente aplicable en estos casos (Koenker y Xiao, 2009). A este respecto, los autores proponen un proceso de estimación de dos etapas para los modelos tipo CAViaR (p,q)-SAV, utilizando modelos GARCH lineales. La relación entre estos dos tipos de modelos se describe a continuación.
son latentes y dependen de parámetros desconocidos. Como consecuencia, la estimación por el método NLQR no es directamente aplicable en estos casos (Koenker y Xiao, 2009). A este respecto, los autores proponen un proceso de estimación de dos etapas para los modelos tipo CAViaR (p,q)-SAV, utilizando modelos GARCH lineales. La relación entre estos dos tipos de modelos se describe a continuación.
Sea u t una variable aleatoria con primer y segundo momento finitos. Por simplicidad, se supone que su primer momento es igual a cero. Entonces, u t sigue un proceso GARCH(p,q) lineal si:


Donde ∈ t es una variable aleatoria con primer y segundo momento finitos y funciones de densidad y distribución f y F, respectivamente.
Adicionalmente, los autores suponen que el cuantil condicionado a la información disponible en t -1 sigue un proceso de localización-escala y está dado por:

con 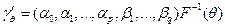 y
y  . Por lo tanto,
. Por lo tanto,  y el proceso (16) tiene la siguiente representación CAViaR(p,q) -SAV:
y el proceso (16) tiene la siguiente representación CAViaR(p,q) -SAV:

Con  . Es importante notar que los coeficientes
. Es importante notar que los coeficientes  son globales en el sentido de que no dependen del cuantil θ, mientras que los parámetros α
i
(θ ),i= 1,…,p sí dependen del cuantil y por ende son locales.
son globales en el sentido de que no dependen del cuantil θ, mientras que los parámetros α
i
(θ ),i= 1,…,p sí dependen del cuantil y por ende son locales.
Estimación
En esta sección se describe la metodología de estimación de la familia de modelos expuestos antes. Esta se lleva a cabo usando las herramientas de la regresión cuantílica (Koenker y Bassett, 1978) y la regresión cuantílica no lineal (Koenker y Park, 1996). Esta técnica es directamente aplicable para el modelamiento de cuantiles condicionales, es robusta a valores atípicos y no impone supuestos distribucionales (Koenker y Xiao, 2009).
La metodología de regresión cuantílica estándar parte del modelo:  , donde{yt:t=1, ,T} es un proceso estocástico asociado a la variable aleatoria Y,{xt:t=1,…T} es una sucesión de vectores fila de una matriz X de tamaño(t x K) y vt corresponde a un proceso i.i.d. con funciones de distribución y densidad, Fv y fv, respectivamente.
, donde{yt:t=1, ,T} es un proceso estocástico asociado a la variable aleatoria Y,{xt:t=1,…T} es una sucesión de vectores fila de una matriz X de tamaño(t x K) y vt corresponde a un proceso i.i.d. con funciones de distribución y densidad, Fv y fv, respectivamente.
El objetivo de esta técnica es estimar los parámetros del modelo asociados al θ-ésimo cuantil de yt 3, notado como βθ. Este se obtiene por medio de la solución del siguiente problema de programación lineal:

O de forma equivalente:

Sin embargo, algunos de los procesos definidos en secciones anteriores no son lineales y por lo tanto, requieren de métodos de regresión cuantílica no lineal (NLQR). En este caso, yt puede ser representado por yt=g(xt, βθ )+vt, donde g(.) es una función no lineal y la estimación del cuantil condicionado se obtiene a partir de la solución del siguiente problema:

Hasta el momento solo se ha descrito la técnica de estimación general para los cuantiles condicionales asociados a la regresión cuantílica lineal y no lineal. A continuación se describe el uso de estas metodologías para la estimación de los modelos presentados en la sección anterior.
Modelo CAViaR
La estimación de los coeficientes  se realiza por medio de la solución del siguiente problema de optimización:
se realiza por medio de la solución del siguiente problema de optimización:

Donde  depende de
depende de  y
y  de acuerdo con la ecuación (7).
de acuerdo con la ecuación (7).
Engle y Manganelli (2004) demuestran que  es consistente. Además, obtienen el siguiente resultado de convergencia en distribución:
es consistente. Además, obtienen el siguiente resultado de convergencia en distribución:

Con:

Siendo  el gradiente de
el gradiente de  de dimensión
de dimensión  ,
,  la función de densidad de ℰ
t
(θ) evaluada en cero y condicionada a la información disponible en t con
la función de densidad de ℰ
t
(θ) evaluada en cero y condicionada a la información disponible en t con  . Además, en el apéndice E se encuentran unos estimadores consistentes de
. Además, en el apéndice E se encuentran unos estimadores consistentes de  y
y  propuestos por estos autores.
propuestos por estos autores.
Por otra parte, Koenker y Xiao (2009) mencionan que la estimación NLQR de los parámetros del modelo GARCH lineal, planteado en (15) y (16), ignora la condición global de los coeficientes asociados a los rezagos (o retardos) de los cuantiles condicionales; tal como se mencionó al final de la sección del proceso CAViaR. Al respecto, estos autores proponen como alternativa un método de estimación de dos etapas que incorpora esta condición.
En la primera etapa se realiza una estimación de los cuantiles condicionales asociados al modelo GARCH lineal usando regresión cuantílica, con el fin de obtener un estimador de la serie de la desviación estándar  . En la segunda se reemplaza σt por dicho estimador y se estima por NLQR la representación CAViaR-SAV del modelo GARCH lineal.
. En la segunda se reemplaza σt por dicho estimador y se estima por NLQR la representación CAViaR-SAV del modelo GARCH lineal.
Para estimar los cuantiles condicionales del modelo GARCH lineal usando regresión cuantílica, inicialmente se representa el modelo descrito en (16) como un ARCH(∞) lineal de la siguiente forma:

Reemplazando la ecuación (15), ut= σtℰt, en la anterior expresión se obtiene:

Y, por lo tanto, el cuantil condicionado de ut está dado por el siguiente modelo QAR(∞):

Donde  Además, bajo las condiciones usuales de especificación, este proceso es estacionario y, por ende, los coeficientes δ
j
decrecen geométricamente. Por consiguiente, el modelo (26) puede aproximarse a un QAR(m):
Además, bajo las condiciones usuales de especificación, este proceso es estacionario y, por ende, los coeficientes δ
j
decrecen geométricamente. Por consiguiente, el modelo (26) puede aproximarse a un QAR(m):

Teniendo en cuenta el resultado anterior, en el cual se aproxima un cuantil condicionado del proceso GARCH lineal mediante un modelo QAR(m), la primera etapa de la metodología de Koenker y Xiao consiste en estimar los parámetros  de la ecuación (27) mediante regresión cuantílica, con el fin de estimar σ
t
. Sin embargo, el vector de parámetros δ
θ
no determina directamente a σ
t
.
de la ecuación (27) mediante regresión cuantílica, con el fin de estimar σ
t
. Sin embargo, el vector de parámetros δ
θ
no determina directamente a σ
t
.
Los estimadores de los parámetros necesarios para generar σ
t
, α0, α1,…,α
m
, y, adicionalmente,  , se pueden obtener a través de la solución del siguiente problema de distancia mínima:
, se pueden obtener a través de la solución del siguiente problema de distancia mínima:

Donde  ,
,  y A
m+1
es una matriz definida positiva de dimensión(m+1)x(m+1)4. Como supuesto de identificación, en esta estimación se asume que
y A
m+1
es una matriz definida positiva de dimensión(m+1)x(m+1)4. Como supuesto de identificación, en esta estimación se asume que  5
5
Posteriormente, los autores proponen estimar σt a partir del vector(â0, â1,…, âm) obtenido en la optimización (28) como sigue:

Finalmente, en la segunda etapa se estima mediante el método NLQR el vector de parámetros  asociado al cuantil condicional descrito en la ecuación (18); teniendo en cuenta que σ
t
es reemplazado por su estimador obtenido en (29):
asociado al cuantil condicional descrito en la ecuación (18); teniendo en cuenta que σ
t
es reemplazado por su estimador obtenido en (29):

con  . De este modo, el θ-ésimo cuantil condicional de ut está dado por:
. De este modo, el θ-ésimo cuantil condicional de ut está dado por:

Las propiedades asintóticas de los estimadores en la primera y segunda etapa se encuentran descritas en detalle en (Koenker y Xiao, 2009).
EJERCICIO EMPÍRICO
El ejercicio empírico consiste en la estimación del valor en riesgo bajo las metodologías de regresión cuantílica expuestas en la sección de metodología. Para este fin, se estimó el VaR para un horizonte de pronóstico de un día y seis niveles de probabilidad (0,005, 0,01, 0,05, 0,95, 0,99 y 0,995)6, sobre los retornos7 de tres series financieras colombianas: el índice de mercado bursátil de la bolsa de valores (Colcap), la tasa de cambio del peso colombiano con respecto al dólar (TRM) y un índice de precios de títulos de deuda pública (IDXTES)8. El tamaño total de la muestra es de 1.918 observaciones, entre el período del 12 de diciembre del 2007 al 20 de noviembre del 2015. Las primeras 1.438 observaciones se usaron para la estimación inicial del VaR y las restantes para las evaluaciones de su desempeño (en adelante, backtesting). Tal como se aprecia en la Figura 1 del Apéndice A, estas series cumplen con los hechos estilizados de las series financieras, puesto que presentan conglomerados de volatilidad y sus distribuciones presentan colas pesadas.
En particular, se estimaron cinco modelos utilizando la metodología de regresión cuantílica. Estos corresponden a tres procesos CAViaR (CAViaR-SAV, CAViaR-AS y CAViaR-IG), a la extensión del modelo CAViaR-IG (AR(1)-CAViaR-IG), y al modelo GARCH lineal con representación CAViaR(p,q)-SAV (RQ-GARCH Lineal). Con el fin de comparar las anteriores metodologías con las usadas en el literatura estándar, se estimó el VaR por medio de tres modelos adicionales: RiskMetrics® , ARMA-GARCH(1,1), y ARMA-apGARCH(1,1)9 10.
A continuación, se presentan los resultados de las pruebas de backtesting de los modelos VaR mencionados.
Con el fin de evaluar el desempeño del VaR de los modelos considerados, se implementó la prueba Pearson multinivel, propuesta por Leccadito, Boffelli y Urga (2014). Esta prueba evalúa la propiedad de cubrimiento condicional del VaR, para un conjunto de valores de θ simultáneamente11. Su estadístico es calculado sobre la serie de fallas, Jt|t-1, definida de la siguiente forma:

Con 0<θ1<…< θk< θk+1<1.
Los Cuadros 1 y 2 del apéndice B contienen los resultados de esta prueba. Estas tablas reportan los valores-p asociados a la prueba de hipótesis de cubrimiento condicional evaluada hasta el rezago m = 15 para una muestra de 480 observaciones. Los resultados indican que no existe evidencia de una mala especificación de los valores en riesgo analizados para los modelos de regresión cuantílica. El único modelo que rechaza la hipótesis nula al nivel de significancia del 1% es el RiskMetrics® en ambas colas.
Por otra parte, las Figuras 2 a 9 del Apéndice C corresponden a los gráficos de backtesting de cada metodología empleada para las tres series analizadas, y calculados a los seis niveles de probabilidad. La línea continua corresponde a los retornos, la punteada al VaR y los círculos a la serie de excesos de retorno12. En general, se observa que el valor en riesgo sigue la dinámica de los retornos en la mayoría de los modelos y presenta un número de excesos aceptable.
Finalmente, en los Cuadros 3 al 8 del Apéndice D se presentan los valores de las funciones de pérdida de López y las de Caporin (F1, F2 y F3)13. Estas funciones permiten clasificar las metodologías según su desempeño en términos del tamaño de los excesos, de tal forma que menores valores implican que se tiene un modelo con mejor comportamiento.
De acuerdo con los valores reportados en estos cuadros se puede observar que, en general, los modelos de regresión cuantílica obtienen los mejores resultados. Se destaca el desempeño del modelo AR(1)-CAViaR-IG, el cual reporta el menor valor para las tres series en el cuantil θ = 0,05. Es estos casos se tiene que la modelación del primer momento es relevante para la estimación del VaR. Este resultado es importante en la medida en que los modelos CAViaR tradicionales no consideran ninguna dinámica en el primer momento de las series.
También se observa que el modelo RQ-GARCH lineal presenta un buen desempeño en cinco de los casos considerados. Esto indica que en algunos casos también es relevante incorporar las restricciones globales dentro del proceso de estimación.
Otro resultado interesante es que, en la mayoría de los casos analizados, los mejores modelos son los que no modelan la asimetría. Además, en los pocos casos en que los modelos asimétricos presentan el mejor desempeño (tres de dieciocho), estos ocurren en la cola derecha de la TRM.
En resumen, estos resultados indican que comparados con los modelos tradicionales, en general, los modelos de regresión cuantílica presentan el mejor desempeño. De los dieciocho casos analizados, para tres series y seis niveles de probabilidad, solo en cuatro se obtienen los mejores resultados para las metodologías tradicionales.
COMENTARIOS FINALES
Este documento presenta un grupo de metodologías para el cálculo del valor en riesgo basadas en la estimación por regresión cuantílica y regresión cuantílica no lineal. Estas técnicas tienen ciertas ventajas en la modelación del cuantil condicionado, ya que sus estimadores son robustos ante valores atípicos y no imponen supuestos distribucionales. También, los modelos expuestos incluyen una especificación autorregresiva en el proceso generador de los datos con el fin de capturar uno de los hechos estilizados de las series financieras asociados a los conglomera-dos de volatilidad en el tiempo.
Posteriormente, se estima el valor en riesgo para los retornos de tres series financieras colombianas usando tanto metodologías de regresión cuantílica (RQ) como técnicas tradicionales. Los resultados de las pruebas de backtesting del VaR muestran que los modelos RQ no presentan evidencia de una mala especificación, mientras que en algunas metodologías tradicionales sí se observa este tipo de problemas.
Es importante señalar que, al comparar con las técnicas tradicionales, los mejores resultados, en términos de funciones de pérdida, se obtienen para las metodologías de regresión cuantílica en la mayoría de ejercicios realizados. Este resultado es de especial utilidad, puesto que permite obtener una medida del riesgo con mejor desempeño, que tiene el potencial de modelar directamente el cuantil sin necesidad de realizar ciertos supuestos.
En particular, se resalta el buen desempeño de dos modelos de regresión cuantílica, el modelo AR(1)-CAViaR-IG y el RQ-GARCH lineal. El primero contempla una dinámica asociada al primer momento de la serie, a diferencia de los modelos CAViaR tradicionales. Mientras que el segundo modelo supera algunos limitantes asociados a la metodología de estimación en este tipo de procesos.


























