











 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares em
SciELO
Similares em
SciELO  Similares em Google
Similares em Google 
 Permalink
Permalink
Introducción
Hoy en día las organizaciones que toman ventaja de sus datos y documentos son más competitivas. Es así como los sistemas de gestión documental (SGD) se han convertido en una herramienta fundamental para las organizaciones, ya que permiten un mejor acceso y organización de los documentos que se manejan en los diferentes procesos de negocio (Ismael y Okumus, 2017). Debido a la creciente demanda de búsquedas rápidas, precisas y oportunas de información en grandes volúmenes de datos y documentos, en los últimos años ha crecido la necesidad de incorporar estos sistemas en las organizaciones sin importar su sector económico (Rangel Palencia, 2017). Estos datos y documentos apropiadamente organizados y almacenados han empezado a ser objeto de análisis inteligente para facilitar los procesos en las organizaciones y para apoyar la toma de decisiones (Lacunza, 2020). En resumen, los SGD resultan de vital importancia para estos dos objetivos: facilitar procesos y apoyar la toma de decisiones (Rodríguez, Castellanos y Ramírez, 2016).
Dado que los procesos de negocio de una organización pueden apoyarse con diferentes tipos documentales y que estos tipos pueden estar representados en documentos estructurados, semiestructurados y totalmente desestructurados, existe el riesgo de que los usuarios carguen documentos con un tipo documental erróneo. Esto afecta la calidad de la información que se recupera en el SGD e involucra demoras en el desarrollo de los procesos empresariales. Es por esto que se hace necesario realizar un proceso de clasificación automática de documentos que permita validar que el documento concuerda con el tipo documental que el usuario ha seleccionado, y en caso de que no corresponda, le advierta inmediatamente al usuario para que tome los correctivos necesarios. Con esta validación se puede aumentar la calidad de los documentos almacenados en el SGD, se aumenta la precisión de la información que se retorna cuando se hace una consulta, se disminuyen los retrasos en el desarrollo de los procesos de negocio y se tiene una fuente de datos de mayor calidad para el desarrollo de futuros trabajos de analítica de datos.
La clasificación de documentos es un proceso que involucra varias etapas, y las decisiones tomadas en cada una de estas etapas junto con los documentos que se manejan define la calidad del resultado. Las etapas son: (i) preprocesamiento y limpieza del texto, que incluye tokenización, conversión a minúsculas, eliminación de palabras vacías, stemming o lematización, entre otras; (ii) extracción de características que representan los documentos basados en tokens, palabras, n-gramas, incrustaciones, frases, párrafos u otras y cálculo de los pesos de estas características en los documentos; (iii) reducción de la dimensionalidad con técnicas como análisis de componentes principales, análisis discriminante lineal, factorización de matrices no negativas, descomposición en valores singulares, wrappers y filtors, entre otras (Villegas et al., 2018; Dorado et al., 2019), que buscan reducir el tamaño de la representación y eliminar ruido de la colección de documentos; (iv) definición de los modelos con base en clasificadores como K-NN (Qin et al., 2019), arboles de decisión (Taloba y Ismail, 2019), bosques aleatorios (Lagrari, Ziyati y El Kettani, 2019), clasificadores bayesianos ingenuos (Qu et al., 2018), redes bayesianas, máquinas de soporte vectorial (Hapsari, Utoyo y Purnami, 2020), regresión logística (Gitanjali y Lakhwani, 2019), algoritmo de Rocchio (Selvi et al., 2017), campos aleatorios condicionales (Chen et al., 2017) y redes neuronales como perceptrón multicapa (Yang et al., 2016), redes de aprendizaje profundo o deep learning (Kowsari et al., 2017; Chen, Yan y Wong, 2020; Jiang et al., 2018), o combinaciones de estos; (v) evaluación y comparación de los modelos obtenidos para seleccionar el mejor y definir si es apropiado para su implementación y uso en producción; y (vi) despliegue en el ambiente de producción, que implica, además monitoreo del rendimiento del modelo durante su uso para realizar la actualización de este cuando sea indicado.
Por otro lado, el actual escenario tecnológico en el que los servicios en la nube se han convertido en una alternativa muy ventajosa por su relación costo beneficio, ha permitido a muchas compañías contar con la última tecnología al menor costo posible. Es así como el diseño de los SGD está migrando a arquitecturas multicliente (multi-tenant) en la nube, facilitando que una instancia del sistema almacene información de muchas compañías o clientes, eso sí, con el apropiado aislamiento y la seguridad que permiten a cada cliente tener sus propios procesos y, dentro de cada uno de sus espacios, tener sus propios tipos documentales, que en algunos casos pueden ser similares a los de los otros clientes.
Con base en lo anterior, el presente trabajo propone un modelo de aprendizaje de máquina que basado en el motor de indexación y búsqueda de ElasticSearch, apoye los procesos de clasificación documental en un SGD multi-tenant, permitiendo a las organizaciones realizar el proceso de clasificación con el modelo (Perceptrón Multicapa, Random Forest, K-NN, Naïve Bayes, o Decision Tree) más apropiado a los documentos que esperan clasificar. Además, presenta los resultados experimentales de dos clientes y una comparación con una adaptación al español del modelo de representación más reciente propuesto por Google, denominado BERT (BETO para español).
A continuación, en la sección siguiente, se presentan algunos trabajos previos de interés para la investigación y luego se resume la metodología seguida para el desarrollo de esta. Después se presentan los resultados obtenidos en cada una de las fases de la metodología y finalmente se presentan las conclusiones de la investigación y el trabajo futuro que se espera realizar en el corto plazo.
Trabajos relacionados
En relación con el proceso de clasificación, además de las referencias presentadas en la sección anterior de introducción, se precisa resumir las siguientes: en Vijayan et al. (2017) se presentan las ventajas y desventajas de varios algoritmos al momento de clasificar textos, lo que es muy importante conocer para elegir el más apropiado en un contexto especifico. Aliwy y Ameer (2017) presentan cinco algoritmos que consideran esenciales para el proceso de clasificación, a saber: árboles de decisión, k vecinos más cercanos (K-NN), Naïve Bayes (NB), máquinas de soporte vectorial (SVM) y un modelo oculto de Markov; sus resultados evidenciaron que la manera más práctica para mejorar el proceso de clasificación es mediante la reducción de características, lo que hace que el proceso sea más rápido y eficiente. Y en Rasjid y Setiawan (2017) se comparan dos métodos de clasificación: K-NN y NB, concluyendo que K-NN se desempeñó de una mejor manera, a pesar de que el proceso de clasificación puede ser más lento si se tiene un gran volumen de documentos (este clasificador es perezoso, no establece un modelo sino que usa los datos de entrenamiento para definir la clase de una nueva instancia o registro).
Por otra parte, el procesamiento de lenguaje natural (NLP) también ha hecho grandes aportes a la clasificación de textos o documentos. Además de los diferentes esquemas de representación de documento basados en conteos (modelo binario, modelo de bolsa de palabras, modelos probabilísticos, entre otros), los modelos de lenguaje pre-entrenados (modelos que capturan la sintaxis y la semántica del lenguaje) han demostrado una gran utilidad para la representación de los documentos, generando buenos resultados en varias tareas de entendimiento del lenguaje natural (Cao et al., 2019). Uno de ellos es el modelo BERT, un transformador bidireccional multicapa propuesto por investigadores de Google en 2019 (Devlin et al., 2019) que se puede ajustar para crear modelos de vanguardia para una amplia gama de tareas como la respuesta a preguntas y la inferencia de lenguaje. Aunque este modelo fue entrenado inicialmente con datos en inglés y chino, se han desarrollo propuestas para otros idiomas como el español, el cual es abordado en Cañete et al. (2020) y se denomina BETO (presentado en 2020).
Metodología
El presente trabajo fue realizado utilizando CRISP-DM (Cross Industry Standard Process for Data Mining) (Wirth, 2000), debido al impacto que ha tenido tanto en la industria como en el contexto investigativo en donde se ha empleado para el desarrollo de diversos proyectos de minería y ciencia de datos (Schröer, Kruse y Gómez, 2021). CRISP-DM es un proceso iterativo e incremental que se desarrolla con las siguientes fases: primero, entendimiento de las necesidades del negocio que permiten definir los objetivos del proyecto de minería de datos (o big data) que se espera desarrollar. Seguidamente se realiza un proceso de entendimiento de los datos y su calidad. A continuación, se procesan los datos para obtener datasets que puedan ser usados por los algoritmos que crean modelos o extraen patrones o tendencias en la fase de modelamiento . Con los modelos generados y la experiencia ganada en el proceso, se realiza una evaluación de la calidad y desempeño del modelo, de las cosas que se hicieron bien y de las que se deben mejorar, así como el cumplimiento de los objetivos establecidos en la primera fase. Finalmente, de ser aceptado el modelo, se realiza la planeación y la ejecución de su despliegue en el entorno de producción. Este modelo no es lineal, algunas fases se pueden realizar en paralelo o en ciclos, como cuando se está entendiendo el negocio que en muchos casos requiere en paralelo entender los datos.
La investigación se realizó sobre el SGD multi-tenant de la empresa Nexura Internacional S.A.S. denominado GFiles. La empresa había determinado que era necesario definir una forma de asegurar que los documentos que se subían como soporte a los procesos correspondían con lo requerido, buscando con esto evitar reprocesos, disminuir el tiempo de ejecución de los procesos y mejorar la satisfacción de los usuarios.
En referencia a las herramientas utilizadas para el almacenamiento y el análisis de la información, se destacan soluciones como Elaticsearch, Hadoop y Spark (Shah, Willick y Mago, 2018). Respecto a la primera, entre sus ventajas están las funcionalidades de búsqueda en tiempo real, sus capacidades para escalar y su facilidad para ser configurada (Zamfir et al., 2019). A pesar de que su velocidad de indexación y búsqueda es ligeramente menor en comparación con otras herramientas como Sphinx, actualmente es un sistema muy completo con varias capacidades para dividir los datos entre varias máquinas logrando con esto realizar tareas con alto desempeño, poco uso de memoria e indexación incremental rápida cuando se trabaja con varios documentos a la vez (Voit et al., 2017). Las anteriores características lo convierten en una gran opción para utilizarlo en procesos de analítica, especialmente en aquellos contextos en los que se requiera analizar datos en tiempo real y por eso fue la herramienta que se usó en GFiles para el almacenamiento y la búsqueda de los documentos, trabajo que se realizó como una fase “0” o previa al proceso de CRISP-DM y de la cual no se dan muchos detalles, ya que corresponde a actividades más de ingeniería y desarrollo que de investigación.
Resultados obtenidos por cada fase de CRISP-DM
A continuación se presentan los resultados obtenidos en el proceso de construcción del modelo de clasificación documental.
Entendimiento del negocio
Para llevar a cabo esta fase, se realizó un análisis de las necesidades y requerimientos de GFiles desde el punto de vista de Nexura como su empresa desarrolladora, la cual además tiene contacto directo con los usuarios de las diferentes organizaciones cliente. Aunque desde la perspectiva de minería de datos se observaron diferentes necesidades, se decidió priorizar la validación de los documentos que se cargan en el SGD en relación con su tipo documental, dado que con esto se mejora la calidad de los datos almacenados, se mejoran los tiempos de respuesta de los procesos y se mejora el nivel de satisfacción de los usuarios finales y las empresas clientes. Por otro lado, como GFiles tiene una interfaz web y se estaba implementado una interfaz móvil, se consideró importante resaltar que el modelo de validación de los documentos se implementara como un microservicio independiente del resto de la aplicación, facilitando así su administración y uso desde diferentes interfaces. De igual forma, implementar el motor de indexación y búsqueda basado en ElasticSearch como un microservicio que sirva de base para la validación de los documentos como para otras tareas propias de GFiles.
Entendimiento de los datos
Originalmente, los datos de GFiles se encontraban almacenados en un sistema de archivos e indexados por ciertos campos en una base de datos relacional; con la inclusión del microservicio de ElasticSearch, los documentos se indexaron en índices específicos de cada organización cliente facilitando al usuario su búsqueda a texto casi completo (máximo 10 páginas por documento) y mejorando los tiempos de respuesta a los usuarios. El texto de los documentos (generalmente en formato PDF) se extrae con el servicio de OCR de Google y luego se organiza la información en ElasticSearch. La primera empresa que se denominará índice_1 cuenta con 6.096 documentos indexados a texto completo y la segunda, índice_2, cuenta con 2.167 para un total de 8.263. En este punto, y por diferentes razones fuera del alcance de la investigación, no se logró contar con la totalidad de los documentos de estas dos empresas, el cual asciende a 178.971 documentos. Después de revisar la calidad de los documentos indexados se consolidó un total de 3.670 documentos en los dos índices.
Como se esperaba, los tipos documentales de las dos empresas tuvieron similitudes y diferencias, también se observó que de algunos tipos documentales había más registros que de otros (problema de clases desbalanceadas), pero algo que llamó mucho la atención fue que en una misma empresa se contaba con varios tipos documentales muy relacionados entre sí. Por ejemplo, el índice_1 contaba con varios tipos documentales para Sugerencias, además en algunos tipos documentales se encontraba un número muy bajo de registros (Respuestas y Cartas con solo tres documentos cada una) por esto se removieron y al final quedaron 3.664 documentos en el proceso. Teniendo esto en mente, se construyó una vista minable que agrega los tipos documentales relacionados en una misma clase conforme se aprecia en la Tabla 1.

Preparación de datos
Con los datos identificados, se realizó el proceso de limpieza y procesamiento. Inicialmente, la construcción de los datasets y la creación de los modelos se realizaron con RapidMiner, debido a las ventajas que ofrece para prototipar y evaluar de una manera ágil y práctica proyectos de minería de datos. Las tareas aplicadas a cada documento fueron: tokenización, filtrado de tokens por tamaño, transformación de tokens a minúscula, remoción de palabras vacías (stopwords), transformación de tokens a su raíz léxica (stemming), generación de n-gramas (unigramas + bigramas + trigramas). Con los tokens procesados, se creó la matriz de términos por documento con ponderación TF-IDF y en conjunto con la clase respectiva para cada documento se generó la vista minable, la cual quedó conformada por 3.664 registros (documentos) y 14.004 atributos.
Modelamiento
La fase de modelamiento se realizó en dos pasos importantes, en el primero se utilizó RapidMiner como apoyo al prototipado y la evaluación rápida de modelos, y luego en el segundo paso se utilizó Python con las librerías NLTK y Scikit-Learn, buscando obtener los modelos definitivos que pudieran ir a despliegue.
En el primer paso, haciendo optimización de parámetros, se crearon varios modelos con un árbol de decisión (Decision Tree, DT) (Kowsari et al., 2019) y con el algoritmo K-NN (Rasjid y Setiawan, 2017) a través de en un flujo de trabajo en RapidMiner, recibiendo como entrada la matriz de términos por documentos (basada en TF-IDF), creada previamente también con un proceso de RapidMiner. La evaluación de los modelos se realizó con validación cruzada de cinco folders. Los mejores resultados obtenidos se presentan al lado izquierdo de la Tabla 2, donde se observa en la parte superior el valor de exactitud (accuracy) para cada algoritmo y luego el valor de recuerdo (recall) para cada clase, esto último con el objetivo de analizar el efecto del desbalanceo de las clases sobre cada clasificador. En rojo se muestran los valores de recuerdo más bajos por clase y en naranja los valores mayores o iguales a 60% y menores a 90%. A pesar de que K-NN es más lento en la fase de predicción, sus resultados de exactitud a nivel global y de recuerdo por clase son muy competitivos y en la clase “Solicitudes” son mejores, aunque igualmente desfavorables. Es preciso comentar que los resultados obtenidos con K-NN concuerdan con la literatura en el hecho de que la similitud de cosenos (cosine similarity) es una de las mejores opciones para comparar documentos de texto.
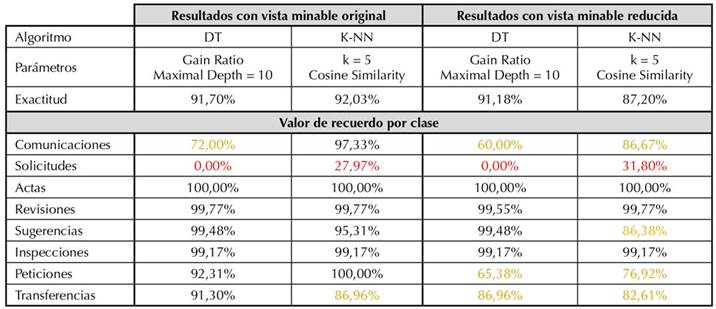
Teniendo en cuenta que con el DT se pudieron determinar los atributos más significativos del dataset de entrenamiento, con estos atributos se definió un vocabulario controlado y se incluyó en el proceso de creación de la matriz de términos por documento. La nueva matriz denominada vista minable “reducida” tan solo conservó 427 atributos de los 14.004 originales. Luego, se realizó nuevamente la optimización de parámetros de DT y K-NN usando la vista minable reducida y validación cruzada de cinco folders y los resultados obtenidos se pueden observar al lado derecho de la Tabla 2. En general los valores de exactitud y recuerdo por clase disminuyeron, hecho que se atribuye al cambio de los pesos en el momento del cálculo de la matriz TF-IDF, por lo cual se desechó la realización de otros procesos de selección de atributos, ya que se presentaría la misma situación. Por otro lado, realizar el proceso de selección de atributos incluyendo el proceso de creación de la matriz TF-IDF resulta muy costoso computacionalmente e inconveniente para el servicio que se ofrecería a los usuarios del SGD GFiles.
Para manejar el desbalance de clases se identificaron tres alternativas, a saber: 1) creación de datos de las clases minoritarias, buscando contar con un número similar de instancias (datos o ejemplos) al que presentan las clases mayoritarias; 2) utilizar un enfoque de aprendizaje basado en costos (metaclasificador) en el que se establece una matriz de costos basada en la relación que existe de equivocarse prediciendo una instancia de una clase mientras que realmente es de otra; y 3) sacar los representantes (prototipos) de las clases que poseen un mayor número de ejemplos (clases mayoritarias). De esta forma se reduce el número de instancias y se equiparan con las clases minoritarias.
La primera opción (creación de datos con SMOTE (Fernández-Navarro, Hervás-Martínez y Gutiérrez, 2011) o similares) no se usó debido a que se pueden crear sesgos o acentuar algunos rasgos de los pocos datos que ya se tienen. La segunda opción (definición de costos manualmente, o automáticamente con SPIDER3 (Wojciechowski, Wilk y Stefanowski, 2018) o similares) también fue descartada dado que el número de clases en el problema que se va a modelar crece dinámicamente con el tiempo. Tampoco se consideró apropiado definir los costos basados en las frecuencias de los documentos por clase y la posible asignación errónea a otras clases. Por esto, se eligió la tercera opción, seleccionar de las clases mayoritarias los ejemplos más representativos (prototipos), logrando así reducir su número y disminuir la diferencia entre las cantidades que poseen las clases documentales. Para realizar este proceso se usaron los algoritmos CNN (Condensed Nearest Neighbor) (Gowda y Krishna, 1979) y RMHC (Random Mutation Hill Climbing) (Skalak, 1994) con los mismos clasificadores previamente evaluados (DT y K-NN). Los resultados del anterior proceso se observan en la Tabla 3. Como se puede ver, los porcentajes de exactitud general obtenidos por los modelos son altos (entre 87,42% y 92,03%). Sin embargo, al revisar el valor de recuerdo por clase, se puede observar que la clase “Solicitudes” sigue presentando valores muy bajos, en las 4 pruebas realizadas no ha superado el 30% y en varias ocasiones no se identificó ninguno de los documentos de esta clase (0,00%). Otras evaluaciones con un nuevo selector de prototipos, ELH (Encoding Length Heuristic) (Cameron-Jones, 1995), y la optimización de parámetros de CNN, mostraron resultados muy similares a los presentados en esta tabla.

Con base en los resultados obtenidos hasta el momento, se evidencia que la exactitud general es una buena medida del comportamiento del clasificador, pero no debe ser la única medida que se debe tener en cuenta, ya que al contar con clases bajamente representadas (pocos registros) que tienen un muy bajo valor de recuerdo, este valor bajo se oculta en los altos valores reportados por la exactitud general. Este hecho debe ser tenido en cuenta al momento de hacer el despliegue de la solución en la plataforma GFiles, en dado caso que no se logre obtener niveles aceptables en el valor de recuerdo para algunas de las clases. Esta situación también planteó otra inquietud al equipo sobre cómo manejar documentos que pertenecen a clases muy generalistas, que manejan muchos temas trasversales al negocio, es decir, clases como “Solicitudes”, en las que se puede solicitar atender una radicación, o solicitar que se acate una sugerencia, u otras similares, tema que sigue abierto a investigación.
Es preciso destacar que en relación con la clase “Solicitudes”, los resultados de K-NN tuvieron un valor de recuerdo alrededor del 30% a diferencia de aquellas que utilizaron DT. Además, a nivel general, K-NN obtuvo porcentajes levemente mayores o competitivos de recuerdo en todas las clases en comparación con los obtenidos por DT.
En el segundo paso y teniendo en cuenta que el despliegue de la solución (de obtenerse buenos resultados) se realizaría en Python a manera de un microservicio que se pudiera llamar desde GFiles, se procedió a implementar todo el proceso (captura, procesamiento y generación de modelos) previamente realizado en RapidMiner en este lenguaje. Como era de esperarse, los resultados presentaron variaciones, debido a que las implementaciones de los algoritmos varían de una librería a otra. En la fase de procesamiento de los documentos para la construcción de la vista minable se usó la clase TfidfVectorizer de Scikit-Learn y se incluyó un límite para el número máximo y mínimo de caracteres permitidos en los tokens con el objetivo de obtener resultados más similares a los obtenidos con RapidMiner.
En Python, además de DT y K-NN, se incluyeron los Bosques Aleatorios (Random Forest, RT), perceptrón multicapa (MLP) y Naïve Bayes basados en la clase GaussianNB de la librería de Scikit-Learn. Los resultados de la ejecución de los cinco clasificadores en la vista minable original se presentan en la Tabla 4. La exactitud de los clasificadores está entre 88,26% (DT) y 91,18% (MLP). Los valores de recuerdo para los tres mejores clasificadores (MLP, RF y K-NN) son superiores al 80% en todas las clases, excepto “Solicitudes”, que está entre 21,84% y 35,63%, lo que contrasta con los resultados de los clasificadores DT y NB que para esta clase tienen resultados entre un 39,08% y 40,99%, castigando el recuerdo en otras clases. Con base en los resultados generados hasta el momento, se puede evidenciar que el mejor algoritmo es el MLP. Además, la clase “Solicitudes” presenta valores bajos de recuerdo en todos los modelos (similar a lo obtenido en RapidMiner). En este paso también se realizó un proceso de selección de atributos y los resultados fueron similares o de menor calidad en algunos clasificadores por lo que se siguió trabajando con la vista minable original y se descartó la reducida.

Evaluación
Los resultados obtenidos en la anterior etapa evidenciaron que los modelos construidos obtuvieron valores similares de exactitud entre el 88% y el 91% con la vista minable original y similares problemas con el recuerdo para una clase, excepto Naïve Bayes, que tuvo problemas con el recuerdo en dos clases. En este punto fue difícil seleccionar un único algoritmo como el claro vencedor en el proceso de clasificación de documentos y teniendo en cuenta que cada cliente (organización o empresa) puede tener documentos con características diferentes, se decidió ofertar el servicio con la posibilidad de que sea el mismo cliente quien selecciona el mejor modelo para su contexto.
En este sentido, se tomaron los datos de las dos organizaciones (índice_1 e índice_2) por separado, se crearon las vistas minables de cada una y se ejecutaron los modelos utilizados. Los resultados se pueden observar en la Tabla 5. Para la primera organización, los modelos reportan una exactitud que oscila entre 82% y 86%, y se escoge como mejor modelo el MLP, que no tiene la mejor exactitud (muy cercana a la mejor obtenida por RF) pero el recuerdo por clase es en general mejor, con lo que se logra un mejor balance entre exactitud y recuerdo. Por otro lado, el hecho de que el problema de recuerdo persista en la clase “Solicitudes” involucra que el modelo al pasar a producción debe establecer un proceso para advertir al usuario y recolectar información que le pueda servir en un entrenamiento futuro para mejorar su rendimiento, esto último se incluye como una historia de usuario en el desarrollo del servicio.

Los resultados de la segunda organización evidencian un alto valor de exactitud y de recuerdo por clase. Los valores son superiores a 90% en todos los casos y, a pesar de que los tres mejores son MLP, RF y K-NN, sería apropiado seleccionar RF o MLP en lugar de K-NN, buscando tener una mejor velocidad de respuesta. Por otro lado, dado que los modelos de RF y MLP se pueden volver obsoletos, se define una historia de usuario en el desarrollo del servicio para monitorear el rendimiento y hacer el registro de datos para entrenamiento. Estos resultados permiten afirmar que el cliente puede pasar a producción uno de estos modelos con entera confianza.
Finalmente y buscado evaluar y comparar los resultados obtenidos con uno de los modelos de representación de documento más actuales y de más reconocimiento en la actualidad, BERT de Google, se aplicó una versión pre-entrenada en español denominada BETO (Cañete et al., 2020) para representar los documentos de las dos organizaciones y armar la vista minable. Los documentos fueron tratados de la siguiente manera: el texto extraído fue convertido en minúscula, se removieron los signos de puntuación y, además, se omitieron las palabras vacías. Teniendo en cuenta que BETO procesa textos con una longitud máxima de 512 tokens y que el tokenizador que acompaña al modelo puede generar tokens adicionales en el proceso, se procedió a dividir cada documento en fragmentos que no superaran dicho límite. Para lo anterior, cada documento fue divido en partes de 150 palabras como máximo y, una vez procesado cada documento, se procedió a escoger el primer fragmento de cada documento para posteriormente ejecutarlo en BETO y obtener su representación.
La Tabla 6 muestra los resultados obtenidos con BETO. Se puede observar que para la primera organización los resultados de exactitud son similares a los obtenidos con la vista minable original para MLP, RF y K-NN, pero decaen notoriamente para NB y DT. También se observa un menor recuerdo en todos los algoritmos con esta representación. Para la segunda organización se evidencian valores comparables, aunque un poco más bajos en exactitud en relación con la vista minable original. Los valores de recuerdo también fueron altos y mayores al 90%, a excepción de los obtenidos por DT con las clases documentales “Inspecciones II” y “Transferencias”, y con Random Forest con la clase “Transferencias”. En resumen, el servicio pasa a despliegue con los algoritmos evaluados y debe permitir que cada cliente (organización) defina su propio modelo. Se deben definir esquemas para monitorear el rendimiento de los modelos y capturar datos que permitan enriquecer futuros procesos de entrenamiento.

Despliegue
A partir de los resultados obtenidos, se estableció un servicio de clasificación a utilizar en conjunto con el SGD GFiles. La Figura 1 muestra la interacción de los componentes del servicio. En este sentido, cada cliente de GFiles inicia el proceso de creación del modelo de clasificación con la recuperación de los documentos que están indexados en ElasticSearch, especialmente el texto extraído de los documentos junto con el tipo documental con el que se registró. Después, se realiza el proceso de preparación (preprocesamiento) de los datos implementado durante el modelado. Una vez preparados los datos, se procede a construir la matriz de términos, utilizando la técnica TF-IDF que junto con la clase documental (definida a partir de la agrupación de los tipos documentales relacionados) se usa para generar la vista minable de entrenamiento, la validación de los modelos y la selección del mejor modelo. Para realizar este proceso se usa la librería Scikit-Learn de Python. Teniendo en cuenta que este proceso puede requerir mucho tiempo de ejecución, se utiliza la librería Celery y el bróker de mensajes RabbitMQ para ejecutarlo en segundo plano. Los resultados generados en los anteriores procesos se registran en la base de datos para poder realizar un seguimiento a las acciones ejecutadas. Al comparar el rendimiento de los modelos y seleccionar el mejor se marca para que este pase a producción por la empresa cliente en GFiles.

Los pasos anteriormente mencionados pertenecen a funcionalidades de un API REST basada en microservicios, que permiten acoplarse adecuadamente con GFiles sin generar cambios a nivel de la arquitectura de este u otro SGD. A continuación, se resume cada uno de los microservicios desarrollados:
Registrar organización: crea una estructura de directorios para la organización donde se almacenarán los documentos, datasets y modelos generados. Ya que GFiles trabaja con múltiples clientes, los microservicios se diseñaron de la misma forma.
Subir archivos: carga los documentos a utilizar para la creación de la vista minable sobre la que se realiza el entrenamiento y validación de los modelos.
Crear matriz: crea la representación TF-IDF de los documentos cargados que, junto con la clase documental, se convierte en la vista minable.
Obtener clasificadores: lista los algoritmos clasificadores disponibles para el entrenamiento del modelo.
Entrenar modelo: crea un modelo de datos utilizando la vista minable y el algoritmo clasificador seleccionado por el usuario. Este microservicio usa validación cruzada.
Obtener resultado: retorna el resultado de las métricas que sirven para decidir cuál modelo desplegar: exactitud a nivel general, y precisión, recuerdo y medida F1 por cada clase, y la matriz de confusión.
Seleccionar modelo: establece (marca) el modelo que será utilizado por el sistema de gestión documental para la clasificación de los documentos de la organización cliente.
Predecir archivo: utiliza el modelo desplegado para predecir la clase documental de un documento.
Es importante mencionar que todos los microservicios a excepción de “Predecir archivo” serán ejecutados principalmente por un administrador de analítica de la organización cliente (o asesor de GFiles provisto por Nexura), debido a que el proceso de entrenamiento y evaluación de los algoritmos requiere de conocimientos en esta área para ejecutarlos apropiadamente.
Durante el uso del servicio es preciso manejar ciertas situaciones. La primera de ellas se presenta cuando se añade una nueva clase en el proceso de entrenamiento y validación. Para este caso, se establece un esquema de actualización que consiste en entrenar un nuevo modelo con los datos actualizados y, posteriormente, decidir cuál modelo se debe desplegar. Durante este proceso se debe tener en cuenta que los nuevos datos pueden venir con ruido o estar mal clasificados, lo cual afecta la calidad del nuevo modelo. Para evitar esta situación, el microservicio de entrenamiento permite construir modelos en un directorio diferente al utilizado por el modelo desplegado, evitando así que se afecte su funcionamiento. Además, los microservicios “Obtener resultado” y “Seleccionar modelo” permiten al usuario evaluar los resultados del nuevo modelo antes de decidir cuál modelo emplear en el SGD. Una vez se selecciona un nuevo modelo, se elimina el que previamente se había desplegado.
Una segunda y muy importante situación se relaciona con el monitoreo del modelo para decidir el momento en que el modelo debe actualizarse debido a la pérdida de calidad en sus resultados. Para lo anterior, se registra la retroalimentación que dan los usuarios y se calculan estadísticas de su rendimiento en producción. Cada vez que el usuario carga un documento, el modelo predice la clase documental y este valor con el tipo seleccionado por el usuario se almacena para conocer aciertos y posibles errores en predicción. Con base en los anteriores datos, el administrador de la organización cliente podrá saber qué porcentaje de los registros ha fallado en la predicción de cada clase documental y con esto decidir si se requiere o no la actualización del modelo. Cada cliente decide la forma de seleccionar el modelo, aunque se recomienda usar en forma conjunta la exactitud general del modelo y el recuerdo reportado por cada clase.
Conclusiones
En este trabajo se realizó un proceso de clasificación documental basado en diferentes modelos de aprendizaje de máquina, perceptrón multicapa, bosques aleatorios, k vecinos más cercanos, arboles de decisión y clasificadores bayesianos ingenuos con datos de dos organizaciones cliente del sistema de gestión documental GFiles. El esquema de representación usado se basó en una bolsa de palabras con n-gramas acumulativos (unigramas, bigramas y trigramas).
El perceptrón multicapa, los bosques aleatorios y los k vecinos más cercanos obtienen los mejores resultados medidos en exactitud general (alrededor del 90%) del modelo y recuerdo por cada clase. Estos resultados son muy similares y hace difícil seleccionar un modelo sobre otro. Se recomienda el uso de los dos primeros, ya que son más rápidos en producción que el modelo de los k vecinos más cercanos, en especial cuando los datos de entrenamiento tienen un alto volumen.
Los resultados de la evaluación y la comparación con BETO (red neuronal profunda BERT pre-entrenada para español) muestran que la representación por bolsa de palabras basada en n-gramas acumulativos obtiene mejores resultados con los clasificadores evaluados. Los proponentes de BERT deben eliminar la limitación que este tiene para representar totalmente el documento, la actual cantidad limitada de tokens que representan un documento hace que el modelo pierda información valiosa.
El proceso de selección de prototipos, realizado con CNN, RMHC y ELH, no sirvió como estrategia de mejora en el recuerdo de la clase “Solicitudes”, que reportó problemas en los experimentos originales, además su alto costo computacional limitó su uso en la fase de despliegue.
En relación con el despliegue, no se define un modelo único para todos los clientes de GFiles, sino que se ofrece a cada cliente la funcionalidad requerida para cargar sus documentos, tipos documentales, homologación de clases documentales, creación de la vista minable, entrenamiento, validación y comparación de varios modelos, selección del mejor y uso de este por parte de sus usuarios específicos.
La implementación desarrollada del servicio (basada en una arquitectura de microservicios) permitió que fuera integrada en GFiles sin realizar modificaciones importantes en el sistema gestor documental, lo que además lo habilita para su uso en otros SGD. Como trabajo futuro se espera mejorar el proceso de entrenamiento mediante la inclusión de otros clasificadores y técnicas para reducir el número de atributos de manera que permita aumentar la velocidad en la creación del modelo sin perder la calidad en sus resultados.

