











 Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares em
SciELO
Similares em
SciELO  Similares em Google
Similares em Google 
 Permalink
PermalinkIntroduction
Mineral composition analysis is a key factor in determining whether or not to carry out mining. Over the years, many scholars have proposed some new ideas and methods for accurate mineral grade assessment, many of which are based on chemical or physical test equipment to obtain the data for ingredient grade analysis (Kameshwara, Rao, & Narayana, 2014; De'nan, Naaim, & Leong, 2017). Therefore, the accuracy of the data used for ore composition analysis is critical to the ore grade analysis. At present, automated testing equipment is used in ore grade analysis, such as "BOX-A type on-stream x-ray fluorescence analyzer", which uses spectral obtain by irradiating X-rays to the pulp to get the results of ore grade. It is worth noting that BOX-A type on-stream x-ray fluorescence analyzer by default is that the spectral data obtained is correct. But whether it is chemical or physical testing equipment are inevitably produced abnormal data. Those outliers directly affect the analysis results of the mineral products analysiser (Clarke, & Levis, 1998; Rivoirard, Demange, & Freulon, 2013). Therefore, the detection and elimination of these abnormal data is the premise and key to the above ore grade analysis work.
A new algorithm is proposed here to especially do outlier detection for ore inspection data which obtain from chemical or physical testing equipment. The algorithm utilizes AR model to fit the time series and makes use of HMM as a basic detection tool, which can avoid the deficiency of presetting the threshold in traditional detection methods. To update parameters of ARHMM online, the structure of traditional BDT (Brockwell-Dahlhaus-Trindade) algorithm is improved here, and a double iterative structure in which iterative calculation from both time and order is applied respectively. With the purpose of reducing the influence of outlier on parameter update of ARHMM, the strategies of detection-before-update and detection-based-update are adopted, which also improve the robustness of the algorithm. Subsequent simulation by model data and practical application verify the accuracy, robustness, and property of online detection of the algorithm.
In this paper our innovations are shown as follow:
Unlike other outlier detect method (such as the traditional AR model detection method), the outliers detect method proposed in this paper does not need to set the detection threshold.
Considering the problem that the model order of chemical or physical testing equipment's hard to be determined, the new detected method which is based on residual error has the function of model order self-learning.
In a view to avoid the influence of outliers on the test results, this paper proposes a detection-before-update and detection-based-update strategies.
The Predecessors' Achievements on Outlier detection
Many good ideas and methods are put forward for the research of outliers detection problem, such as that Barnett and Lewis proposed an outliers detected method based on statistics in their word named 'Outlier in Statistical Data (Barnett & Lewis, 1994). Outlier detection method based on distance is proposed by Knorr and Raymond (Knorr & Ng, 1999; Edwin & Raymond, 1998), an new detected method based on density is suggested by Ramaswamy et al. (2000). But for ore inspection data, the detection methods based on distance, density or variance is a lack of feasibility since an online real-time detection method be needed for the ore test data. With the research of anomaly data detection technology, many new ideas and techniques are introduced, such as clustering analysis (Almeida & Barbosa, 2007) and neural network method (Bullen, Cornford, & Nnbney, 2003; Prakobphol, & Zhan, 2008). But clustering analysis method is also not suitable for online outlier detection for extensive test data, and neural network method requires a lot of data to model learning. In 1995, Ragaran and Argrawal put forward the concept of "sequence anomaly" (Han & Micheline, 2001) and proposed the detection method based on deviation (Takeuchi, & Yamanishi, 2006). Because this method needs to know the order of the model, it can not be directly used for the outlier detection of mineral grade analysis data.
Structure of Double iteration in BDT
To make the BDT algorithm can be calculated online, the improved BDT algorithm with double repetition structure is proposed in this paper.
Traditional BDT algorithm
The traditional BDT algorithm is improved by Levinson-Durbin algorithm which is proposed by Brockwell et al. (2002). For traditional BDT algorithm, using all the data to the iterative calculation of model order, in a view to obtain the order of the forward and backward AR model.
X t ,t=1,2,··· is the test data waiting for detection, where x t is m -dimension vectors. So forward AR model can be express as Equation 1.

In which, г к , (t) is forward residual under k order model, which obeys Gauss distribution with zero means. a k (i) is the coefficient of forwarding AR model under к order model. So backward AR model can be written as Equation 2.

With Minimizing all data forward and backward residual as the target, so the generalized objective function written as Equation 3 (Trindade, 2003).
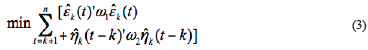
n is the number of the data. ω
1
and ω
2
are weighted coefficient matrix for forwarding and backward AR model, and in BDT algorithm, the values of ω
1
and ω
2
is 1. 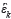 (t) and are Estimated residual values for forward and backward AR model individually.
(t) and are Estimated residual values for forward and backward AR model individually.

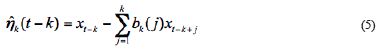
In which,  are m -dimension matrix. The traditional BDT algorithm can be written in full as followed:
are m -dimension matrix. The traditional BDT algorithm can be written in full as followed:
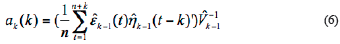
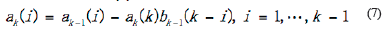

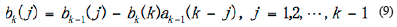
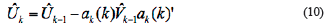
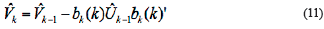
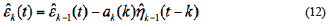
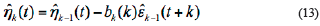
In Equation 6 to Equation 13, 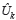 and
and 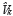 are estimated variance for forwarding and backward noise. The initial condition for traditional BDT algorithm are:
are estimated variance for forwarding and backward noise. The initial condition for traditional BDT algorithm are:
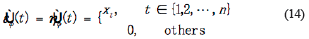


The subscript ø express that when the initial iteration, the model order set is empty.
The objective function of improved BDT algorithm also is Equation 3. The dynamic performance of the algorithm is enhanced by the forgetting factor . The improved BDT algorithm has double loop structure which model order is inner loop and time is the outer loop.
We set 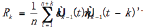 which is part of Equation 6. So:
which is part of Equation 6. So:
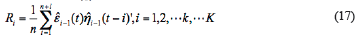
In Equation 7, k a set maximum value for model order. Considering the time-varying characteristics of the model parameters, the forgetting factor is added to the outer loop(time loop) updates.
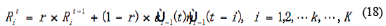
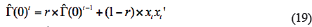
In Equation 18, Rit is the mean of the covariance matrix for 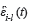 and
and 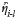 (t-i) in time. Similarly, Equation 13 can be rewritten as:
(t-i) in time. Similarly, Equation 13 can be rewritten as:
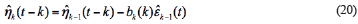
So the calculation process of double iteration algorithm is illustrated in Figure 1.
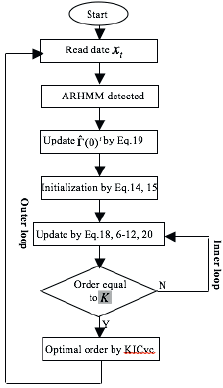
Implementation of Order Self-learning ARHMM Detection Algorithm
The traditional ARHMM structure is composed of two parts (Wang, & Chiang, 2008): one is Markov chain, which is expressed as initial state probability π and state transition matrix 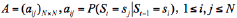 in which St is the state at time t, N is the total state for HMM, and
in which St is the state at time t, N is the total state for HMM, and 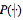 is a conditional probability. The other is expressed as observation probability matrix
is a conditional probability. The other is expressed as observation probability matrix 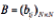 calculated by AR model.
calculated by AR model.
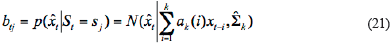
In Equation 21, Ν(
*
) is Gauss function, and 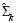 is estimated the variance of Gauss distribution.
is estimated the variance of Gauss distribution.
ARHMM outlier detection algorithm also composed of two steps:
One step-- Preliminary detection
From Equation 1, we can see that there is a deviation between estimated process data by AR model and real process data.

If the deviation E k (t) is only noise, it obeys Gauss distribution. So the preliminary criteria for outlier detection are to determine the probability that the deviation follows Gauss distribution.
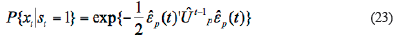
In Equation 23, s t = 1 indicates that the real data detected is normal, s t = 0 means it is the outlier. So the detection criteria can be expressed that:
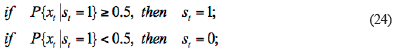
In Equation 23, the subscript p is the optimal model order calculated by KICvc criteria whose expression is:
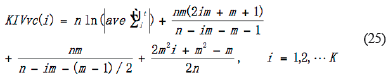
In Equation 25, ave 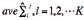 is the mean of residual ε
k
(t) under various model order (Bilmes, 2006).
is the mean of residual ε
k
(t) under various model order (Bilmes, 2006).

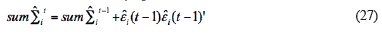
Two step-- Final detection
In final detection, the result of Preliminary detection is the observed value of HMM. So the final detection result obtained by Viterbi algorithm (Abd-Krim, 2006):
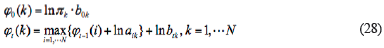
For improved ARHMM algorithm, when the data at t time is detected, the data before t time already is detected. So the traditional Viterbi algorithm is request into:
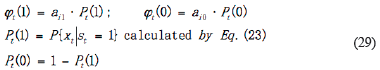
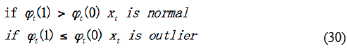
Parameters Updating by Outlier
The parameters of order self-learning ARHMM algorithm need update online, and the parameters are estimated residual mean 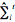 , State transition matrix A,
, State transition matrix A, 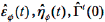 and in improved BDT algorithm. Specific update algorithm is as follows:
and in improved BDT algorithm. Specific update algorithm is as follows:
(A) 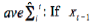 : If is normal data, then αve
: If is normal data, then αve 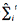 maintained by Equations 30, 31, otherwise, αve not updated at time t.
maintained by Equations 30, 31, otherwise, αve not updated at time t.
(Β) 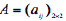 : since there are two states in ARHMM algorithm. So the updated algorithm is:
: since there are two states in ARHMM algorithm. So the updated algorithm is:
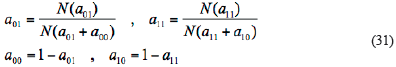
In Equation 31, N (αy) indicates the times of the situation that St-1 = i, St =j, appears (Lou, 195).
(C) 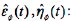 If x
t
,: is normal data, then
If x
t
,: is normal data, then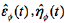 , calculated by Equation(14), otherwise, Using data means to replace x
t
.
, calculated by Equation(14), otherwise, Using data means to replace x
t
.
(D) 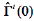 : If xt, is normal data, then calculated by Equation 19; otherwise, it calculated by Equation (32).
: If xt, is normal data, then calculated by Equation 19; otherwise, it calculated by Equation (32).
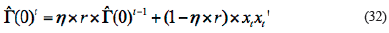
(E) 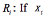 is normal data, then
is normal data, then 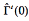 calculated by Equation (18); otherwise, it calculated by Equation 33.
calculated by Equation (18); otherwise, it calculated by Equation 33.
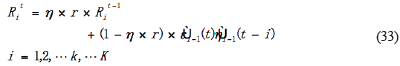
Results and Discussion
Model-Based Validations
To verify the accuracy of the algorithm to detect the order of the model, the three order model which reacting ore detection interference process are used to generate the data. The data is shown in Figure 2-(a), and the order detection results are shown in Figure 2-(b).
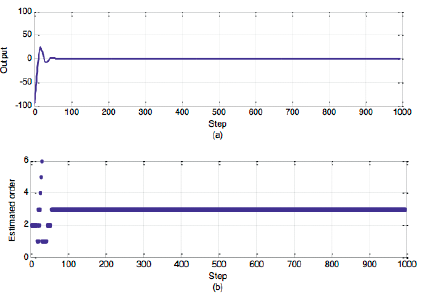
As can be seen from the order detection results, the proposed algorithm can accurately detect the model order through the short-term adjustment process.
With a view to verify that the proposed algorithm not only can identify the optimal model order but also can detect the abnormal data accurately. We modified the open-loop model mentioned in the Alex Alexandridis paper to get the second set of data (Alexandridis, Sarimveis, & Bafas, 2003). Rabiner 1989). The modified model is as follows:
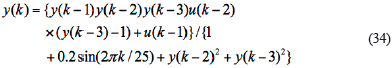
In which:
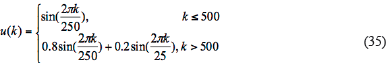
As can be seen from (34), there are time vary parameters on the denominator. To verily the robustness of the algorithm, we add 10% of the white noise and eight anomalies. The data is shown in Figure 3-(a), and the order detection results and outliers detected results are shown in Figure 3-(b) and Figure 3-(c).
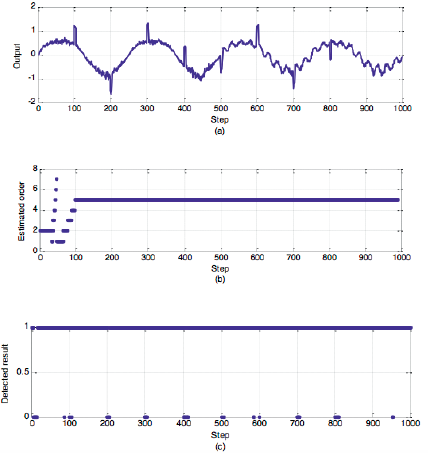
Fig.3-(a) is the data waiting for detecting. Fig.3-(b) is the order estimated result, and Fig.3-(c) is the outlier detection result. As can be seen from the result, for the third-order nonlinear time-varying system, the model-order self-learning algorithm proposed in this paper can find its optimal model order and accurately detect all the anomaly data.
Application
To further verify the practicality of the improved ARHMM outlier identified method, it is applied to the on-stream x-ray fluorescence analyzer, which, first of all, in the last century 70's by the Finotec Outotec company successfully developed and implemented to mineral processing practice. So far, Finland Outotec company still has more than 80% market share. In China, the Beijing Institute of Mining and Metallurgy following its analytical principles, developed in 2014 with the same function grade analyzer - BOXA type on-stream x-ray fluorescence analyzer (Hekimoglu, Eernoglu, & Kalina, 2009). According to foreign reports, the measurement accuracy of the analyzer increased by 1%, will effectively improve the metal recovery rate of 0.2 or more, and now from the hardware to improve measurement accuracy has been very difficult, or input-output serious disproportionate, so more scholars turn to the analysis of the modeling technology to improve research. Based on this situation, the accuracy of the data for the model of learning is essential
Our comparative tests are as follows:
The first set of data is obtained as follows: first of all, we use the improved ARHMM outlier detection algorithm proposed in this paper to pre-process the spectral signal which as the input of the analyzer, and get the ore grade results as the first set of data.
The second set of data is obtained as follows: we use the traditional AR outlier detection algorithm proposed in paper by Northey, Mohr, & Mudd (2014) to pre-process the spectral signal which as the input of the analyzer, and get the ore grade results as the second set of data.
Finally, the two sets of data are compared with the results of the ore grade laboratory test, the error of the two groups of test results as shown in table 1.
Table 1 The result of Comparison between with outlier detection process and without outlier detection process
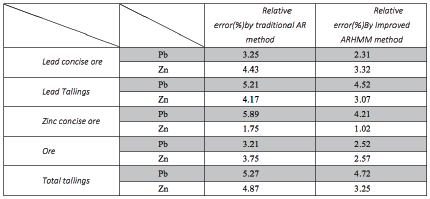
It can be seen from the table that there is higher accuracy when using the improved ARHMM outlier detection algorithm proposed in this paper to do the pre-processing of the spectrum compared to tradition AR outlier detected method, which since the improved ARHMM outlier detected algorithm have more robustness and more suitable for non-linear systems.
Conclusions
Taking into account the lack of ARHMM algorithm for ore grade analysis process, an order self-learning ARHMM algorithm is proposed in this paper, whose innovation points are summarized as: first, unlike other outlier detection method (such as the traditional AR model detection method), the outliers detection method proposed in this paper does not need to set the detection threshold. Second, considering the problem that the model order of control system's hard to be determined, the new detected method which is based on residual error has the function of model order self-learning. And third, to avoid the influence of outliers on the test results, this paper proposes a detection-before-update and detection-based-update strategies. So under above improving, ARHMM algorithm can more accurately use to analysis the data in the geological mineral grade analysis process. In other words, the application field of ARHMM algorithm has been expanded. Subsequent simulation by model data and practical application verify the accuracy, robustness, and property of online detection of the algorithm. According to the result, it is evident that new algorithm proposed in this paper is more suitable for outlier detection in the geological mineral grade analysis process.

