











 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares em
SciELO
Similares em
SciELO  Similares em Google
Similares em Google 
 Permalink
Permalink
Introducción
Aparicio y Abril (2016) establecieron que la melina Gmelina arborea Roxb. ex Sim. (Lamiaceae) tiene la capacidad de producir 61,30 t/ha/año de forraje verde y 16,57 t/ha/año de materia seca, donde las hojas presentan un contenido de proteína cruda (PC) del 17,9 %, digestibilidad in vitro de la materia seca (Divms) del 43,8 %, fibra en detergente neutro (FDN) del 35,5 % y fibra en detergente ácido (FDA) del 31,3 %, lo que llevó a la conclusión de que la incorporación de G. arborea en bancos forrajeros evidenció una mayor producción de forraje verde al compararse con otras plantas que tienen el mismo enfoque. Asimismo, Bueno et al. (2015) determinaron el rasgo nutricional para el forraje de melina Gmelina arborea en cortes de 39, 60, 72 y 87 días, correspondiendo los niveles de PC a 7 % y 16 %, materia seca (MS) entre 24 % y 35 %, FDN entre 43 % y 58 %, FDA entre 36 % y 42 % y degradabilidad de la materia seca (DEG) entre 66 % y 77 %.
La melina es una especie arbórea forrajera de origen asiático y de gran potencial forestal por su virtud de rápido crecimiento, lo que le permite ser utilizada como cerca viva, cortina rompevientos, linderos maderables y de forma ornamental (Castañeda-Álvarez et al., 2017), aunque también, por su uso maderable, es utilizada como materia prima en la ebanistería, la carpintería, la producción de instrumentos musicales y embalajes, entre otros (Vanoye-Eligio et al., 2020). Como recurso no maderable, sus usos están vinculados a la actividad melífera, la medicina hindú, el cultivo de gusanos de seda y el uso de hojas y frutos en la alimentación de ganado (Directorio Forestal Maderero, 2018).
La melina, que parece una planta más exigente en requerimientos de suelo, ha mostrado un gran potencial de desarrollo y cobra cada vez más importancia al ser considerada entre las tres primeras especies recomendadas para la implementación de reforestación por las corporaciones de investigación: Corporación Colombiana de Investigación Agropecuaria (Corpoica), Centro Internacional de Agricultura Tropical (CIAT) y Centro para la Investigación en Sistemas Sostenibles de Producción Agropecuaria (Cipav), incluyendo los sistemas silvopastoriles, en el entendido de que estos contribuyen en un menor grado en la compactación del suelo y, por ende, mejoran las condiciones de fertilidad del suelo (Useche & Azuero, 2013), siendo conveniente adelantar estudios a través de modelos matemáticos que tengan la capacidad de estimar el área foliar (AF) de esta especie a través de métodos no destructivos.
Para la determinación del AF se deben tener varios aspectos que permiten el logro del objetivo y el nivel de precisión deseado, tales como: el diseño del muestreo, el tamaño de la muestra, la morfología de la hoja, la relación de la planimetría y las ecuaciones de regresión soportadas en los supuestos (normalidad y homocedasticidad en residuos, no colinealidad, no autocorrelación), validando el modelo seleccionado que explica y pronostica la respuesta del AF (Pentón et al., 2006).
Es necesario tener en cuenta que el índice de área foliar (IAF), al ser la parte aérea que capta la radiación solar, condiciona los procesos vitales como la fotosíntesis, la respiración y la productividad, por lo que proporciona información acerca de la cantidad de superficie fotosintética, la cantidad de oxígeno molecular liberado y la producción de forraje por la construcción de los tejidos vegetales como subproductos de la fotosíntesis en el ecosistema o área de estudio (Valcárcel et al., 2008; Ugarte, 2012; Nafarrate Hecht, 2017).
Al estimar el AF de árboles del bosque seco tropical mediante un modelo matemático, Alvarez et al. (2012) encontraron la relación entre el AF y las dimensiones largo (L) y ancho (A), como variables predictoras, y se analizaron mediante regresión lineal con las variables transformadas logarítmicamente para seleccionar el modelo de mejor ajuste estadístico. En las 13 especies de árboles, se encontró alta correlación (r = 0,983-0,999), lo que indica que existe una asociación del 98,3 % al 99,9 % entre el ln AF y el ln L*A, como también un alto coeficiente de determinación (R2 ajustado = 0,966-0,998), lo que señala que el ln L*A explica en un 96,6 %99,8 % la variabilidad del ln AF. Asimismo, los datos de las 13 especies fueron agrupados en siete categorías (todas, hojas simples, hojas compuestas, AF < 50 cm2, AF > 50 cm2, AF < 100 cm2 y AF > 100 cm2), estableciéndose una alta correlación (r = 0,994-0,998) y también un alto coeficiente de determinación (R2 ajustado = 0,990-0,997); sin embargo, aunque en todos los modelos de regresión los valores de las pendientes (α) fueron altamente significativos (p < 0,001; p < 0,01; p < 0,05), en algunas especies (A. farnesiana, H. brasiletto, M. bijugatus) y categorías de tamaño del AF (AF > 100 cm2 y AF > 50 cm2), los interceptos (c) no aportaron significativamente a los modelos (p > 0,05), por lo que se concluye que como modelo lineal adecuado para realizar una estimación del AF de cualquiera de las especies de bosque tropical seco se debe establecer: In (AF) = -1,80 + 0,967 ln (L*A) (R2 = 99,5 %, p < 0,001).
De acuerdo con lo anterior, el presente trabajo tuvo como finalidad establecer que existe una relación estadística entre las variables L y A, a través de un modelo de regresión que permite estimar el AF en G. arborea del Sistema Integral de Nutrición, Pastoreo Agroecológico y Reproducción (Sinpar) en Barrancabermeja, Santander.
Materiales y métodos
El trabajo se realizó en el proyecto Sinpar, localizado en el Centro de Investigaciones Santa Lucía, propiedad del Instituto Universitario de la Paz, ubicado en la vereda El Zarzal del municipio de Barrancabermeja, Santander, que se encuentra en las coordenadas geográficas 07° 3′ 55″ N, 73° 52´ 50″ O y a una altitud de 81 m s.n.m. (Municipios de Colombia, 2022). Los parámetros meteorológicos medidos fueron: precipitación anual de 2675 mm, temperatura entre 27 °C y 36 °C, humedad relativa entre 76 % y 83 %, evaporación de 4-5 mm/día y brillo solar de 5-8 h/día (Instituto de Hidrología, Meteorología y Estudios Ambientales, s. f.). Este proyecto hizo parte del macroproyecto “Diseño de sistemas productivos sostenibles como estrategia de conservación de paisajes rurales degradados, Barrancabermeja, Santander”, financiado por el Departamento Nacional de Planeación (DNP).
Este estudio fue de tipo observacional, transversal y correlacional en un sistema silvopastoril instaurado, tomándose la información por árbol en un solo momento y corroborándose el comportamiento de modelos matemáticos del AF desde criterios de bondad de ajuste. La G. arborea está dispuesta perimetralmente en el sistema agroforestal de 5 ha, dividido en 10 radiales (0,5 ha cada uno) (figura 1), siendo seleccionado este sistema para el estudio por la altura de follaje para consumo animal (≤ 1,72 m) y la supervivencia (89 %).

La población (N) de G. arborea corresponde a 77 árboles, distribuidos en subpoblaciones (Nirx) en los 10 radiales. La toma de información se sustentó en el muestreo aleatorio simple, donde cada árbol tuvo la misma probabilidad de ser seleccionado (López, 2004).
El tamaño de la muestra aleatoria se determinó al tener en cuenta la variabilidad de los datos del último muestreo para las variables: altura total (AT), diámetro del tallo a base (DAB) y diámetro del tallo a pecho (DAP), acorde con lo señalado por Segura y Andrade (2008), y se eligió la variable de menor variabilidad a partir del coeficiente de variación (CV), lo que corresponde a la AT de la especie (tabla 1). Posteriormente, se definió una muestra piloto de n = 30 para inventarios forestales, consignándose la información correspondiente a las medidas de tendencia central (media) y de dispersión (desviación estándar y CV) (tabla 2).
Tabla 1 Medidas de tendencia central y de dispersión para las variables dendrométricas AT, DAB y DAP provenientes de los datos del último muestreo de G. arborea
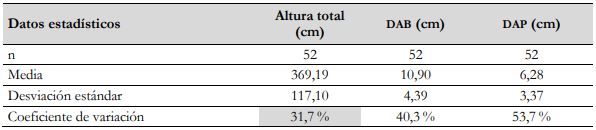
Fuente: Elaboración propia
Tabla 2 Medidas de tendencia central y de dispersión de la muestra piloto para la variable altura total de G. arborea
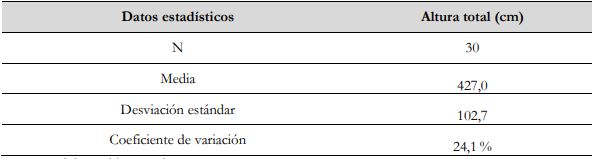
Fuente: Elaboración propia
El CV % junto con el error máximo admisible de muestreo (ε %), correspondiente al 10 % en inventarios forestales (Da Cunha & Guimaraes, 2008), permitieron establecer el tamaño de la muestra (ni) a partir de la ecuación formulada por Yepes et al. (2011), cuando el inventario forestal se va a desarrollar sobre un mismo tipo de cobertura con base en un muestreo aleatorio simple (MAS), relacionándola en este caso con el cálculo del número de árboles para poblaciones finitas de la especie forrajera en estudio (ecuación 1) (tabla 3).
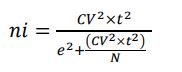 (ecuación 1) (Yepes et al., 2011)
(ecuación 1) (Yepes et al., 2011)
Donde:
-
n = tamaño de la muestra en número de unidades por especie forrajera t = valor de t α/2, gl especie
CV % = coeficiente de variación de la variable AT en la muestra piloto por especie forrajera
e = error máximo admisible (10 %)
Tabla 3 Información de datos estadísticos para el cálculo del tamaño de muestra de G. arborea
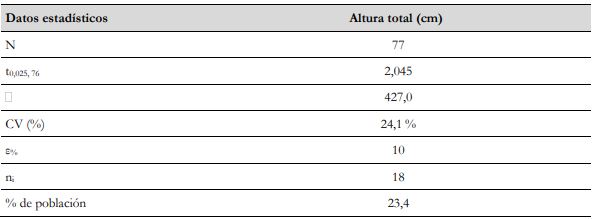
Fuente: Elaboración propia
Posteriormente, se determinó el tamaño de la muestra por radial nirx (nir1, nir2… nir10) desde su proporcionalidad a partir de la ecuación 2, consignándose dicha información en la tabla 4.
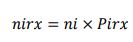 (ecuación 2)
(ecuación 2)
Donde>
-
nirx = tamaño de la muestra en número de unidades por especie forrajera en cada radial
ni = tamaño de la muestra en número de unidades por especie forrajera
Pirx = proporción por radial, es decir, tamaño del radial / tamaño de la población

Las actividades en campo consistieron en la obtención de hojas, llevándose a cabo un muestreo destructivo por árbol de melina, consistiendo esto en el corte de las ramas y la recolección de hojas/ramas por debajo de la altura de consumo del animal (≤ 1,72 m), podando así 93 ramas y recolectando 3368 hojas en total, es decir, 36,2 hojas/rama/árbol en promedio.
Las actividades de laboratorio estribaron en la medición de las variables foliares de largo máximo (sin incluir el peciolo) (cm) y ancho máximo (cm) para establecer el AF (cm2) de acuerdo con lo señalado por Cabezas-Gutiérrez et al. (2009), Cardona et al. (2009), Hernández (2020), Pentón et al. (2006) y Ruiz-Espinoza et al. (2007).
El análisis estadístico se realizó desde la información de largo, ancho y AF por rama, fundamentado en estadística descriptiva e inferencial, donde la estadística descriptiva se abordó desde medidas descriptivas de tendencia central (media, mediana), posición (mínimo, máximo), dispersión (varianza, desviación estándar, CV, error estándar (EE)), normalidad (prueba de Shapiro-Wilk), gráficas descriptivas (diagrama de caja y probabilidad normal) y asociación (correlación r).
La estadística inferencial se soportó en la estimación y la selección del modelo de regresión simple linealizado (lineal 𝑌 = 𝛽0 + 𝛽1𝑋, cuadrático 𝑌 = 𝛽0 + 𝛽1𝑋 + 𝛽2𝑋2, cúbico 𝑌 = 𝛽0 + 𝛽1𝑋 + 𝛽2𝑋2 + 𝛽2𝑋3) y no linealizado (logarítmico 𝑌 = 𝛽0 + 𝛽1𝑙𝑛𝑋, potencial 𝑌 = 𝛽0𝑋𝛽1, exponencial Y= 𝛽0𝑒𝛽1𝑋), donde Y es la variable que define el área foliar, acorde con lo señalado por Pentón et al. (2006) y Vallejos et al. (2019).
Para la selección del modelo propuesto, se establecieron como criterios de bondad de ajuste: coeficiente de determinación (R2), error cuadrático medio (ECM), p-valor de coeficientes [(p)βx], análisis de residuos (normalidad prueba de Shapiro-Wilk, homocedasticidad prueba de BreuschPagan, dispersión de residuos vs. valores ajustados y criterio de información de Akaike (AIC)), en concordancia con lo planteado por Cardona et al. (2009), Martínez-López y Acosta-Ramos (2014) y Vallejos et al. (2019). Los datos fueron procesados con los softwares STATA MP 14.0 y RStudio.
Resultados y discusión
La estadística descriptiva estableció que la distribución de los datos de largo, ancho y AF presentaron una distribución normal soportada en la prueba de Shapiro-Wilk (tabla 5 y figuras 2) y el gráfico de probabilidad normal (figuras 3).
Tabla 5 Datos estadísticos descriptivos del largo, ancho y AF de G. arborea

Fuente: Elaboración propia
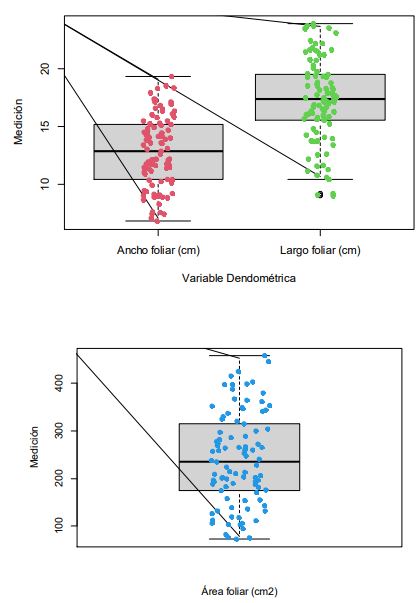
Fuente: Elaboración propia
Figuras 2 Diagramas de caja para las variables largo (cm), ancho (cm) y AF (cm2) de G. arborea
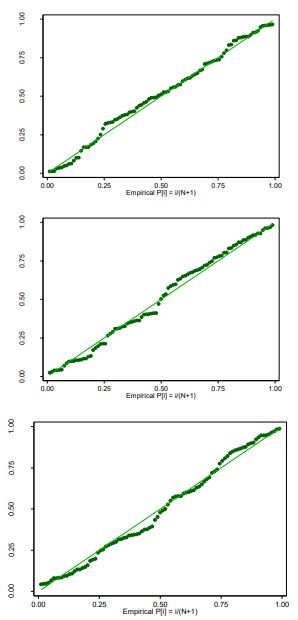
Fuente: Elaboración propia
Figuras 3 Gráficos de probabilidad normal para las variables largo, ancho y AF de G. arborea
Las variables de largo y ancho foliar presentaron una correlación con la variable AF correspondiente a 0,954 y 0,979 (figura 4), respectivamente, lo que indica que el grado de asociación de cada variable con el AF es equivalente al 95,4 % y el 97,9 %, respectivamente (Szretter, 2013).

Fuente: Elaboración propia
Figura 4 Correlación entre las variables largo, ancho y área foliar de G. arborea
Las ecuaciones de regresión para el área foliar estimada (AFE), entre las variables área foliar real (AFR) vs. largo foliar (LF), soportadas en los criterios de bondad de ajuste, corresponden a los modelos lineal, cúbico y exponencial (ecuaciones 3, 6 y 8), descartándose los modelos logarítmico, cuadrático y potencial (ecuaciones 4, 5 y 7) (tabla 6). Las ecuaciones de regresión para la AFE entre las variables AFR vs. ancho foliar (AnF), basadas en los criterios de bondad de ajuste, competen a los modelos lineal, potencial y exponencial (ecuaciones 9, 13 y 14), excluyéndose los modelos logarítmico, cuadrático y cúbico (ecuaciones 10, 11 y 12) (tabla 7).
Tabla 6 Ecuaciones de regresión correspondientes al área foliar estimada AFE vs. LF de G. arborea

Notas aclaratorias: *valor crítico
AFE: área foliar estimada, LF: largo foliar, AnF: ancho foliar, R2: coeficiente de determinación, ECM: error cuadrático medio, (p) βx: p-valor en coeficientes de regresión, Nr: normalidad de los residuos (prueba de Shapiro-Wilk), Hr: homocedasticidad de los residuos (prueba de Breusch-Pagan), AIC: criterio de información de Akaike y V(+/-): validez de la ecuación.
Fuente: Elaboración propia
Tabla 7 Ecuaciones de regresión correspondientes al área foliar estimada AFE vs. ancho foliar AnF de G. arborea

Notas aclaratorias: *valor crítico
AFE: área foliar estimada, LF: largo foliar, AnF: ancho foliar, R2: coeficiente de determinación, ECM: error cuadrático medio, (p) βx: p-valor en coeficientes de regresión, Nr: normalidad de los residuos (prueba de Shapiro-Wilk), Hr: homocedasticidad de los residuos (prueba de Breusch-Pagan), AIC: criterio de información de Akaike y V(+/-): validez de la ecuación.
Fuente: Elaboración propia
Así, los modelos exponenciales presentan una mejor estimación del AFE, tanto en LF (𝐴𝐹𝐸 = 28,0105𝑒0,1192𝐿𝐹) como en AnF (𝐴𝐹𝐸 = 35,2523𝑒0,1421𝐴𝑛𝐹), acorde con los criterios de bondad de ajuste, tales como el R2, al explicar la proporción de la variación total en la variable dependiente Y (AF) por las variaciones en la variable (única) explicativa X (largo o ancho foliar) (Gujarati & Porter, 2010), es decir, la variabilidad del AF estimada AFE es explicada en un 92,9 % y 94,1 % por las variaciones en el LF y el AnF, respectivamente (figuras 5).
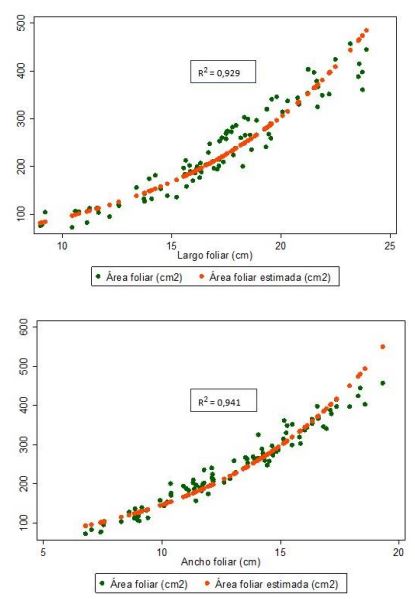
Elaboración propia
Figuras 5 Gráficos de regresión exponencial de AFE vs. LF y AFE vs. AnF de G. arborea
De manera paralela, es necesario comparar estos modelos alternativos para la misma variable endógena, para lo cual se utiliza el criterio de información de Akaike (AIC), ya que elige el modelo que tenga menor valor de criterio y, de esta forma, prima la capacidad predictiva del modelo (Jeréz, 2017), por lo que el AIC corrobora la escogencia de los modelos exponenciales como mejores predictores del área foliar respecto al largo y el ancho foliar, al estos presentar los valores más bajos de AIC (-126 y -144) respecto a los modelos lineal (893) y cúbico (868) en la relación AF vs. LF, como también en los modelos lineal (822) y potencial (-194) en la relación AF vs. AnF.
Además, el ECM en los dos modelos exponenciales es muy bajo, lo que hace más precisa la estimación en términos de la dispersión de la distribución de la variable dependiente (AF) alrededor de su verdadero valor (Gujarati & Porter, 2010).
Igualmente, el p-valor (p ≤ 0,05) permite establecer que los coeficientes de regresión son consistentes y eficientes estimadores lineales en ambos modelos.
También, la prueba de Shapiro-Wilk establece que los residuos presentan una distribución normal en estos modelos (p = 0,0761 y p = 0,8353). En el contexto anterior, dependiendo del tamaño de los datos (n = 93 ramas) se pueden detectar incluso desviaciones leves de la no normalidad, siendo el valor de p no muy útil como indicador de la acción a seguir, por lo que es recomendable el acompañamiento con un gráfico de distribución normal (Faraway, 2009), el cual evidencia dicho comportamiento (figuras 6).
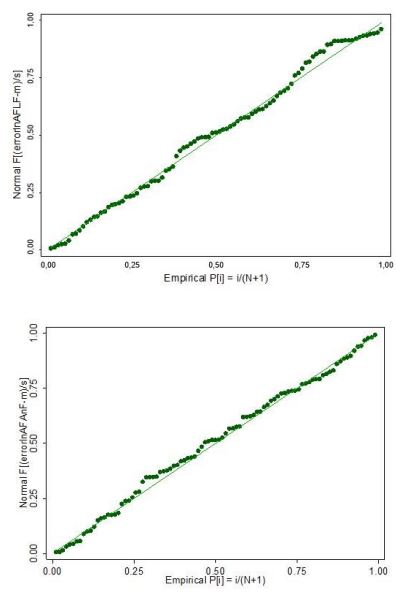
Fuente: Elaboración propia
Figuras 6 Gráficos de probabilidad normal de residuos de los modelos exponenciales AFE vs. LF y AFE vs. AnF de G. arborea
De la misma forma, la prueba de Breusch-Pagan señala homocedasticidad en los residuos (p > 0,05), es decir, la varianza del error o de perturbación es la misma sin importar el valor de X (largo o ancho foliar), o en otras palabras, las poblaciones Y (AF) tienen la misma varianza para los diversos valores de X (largo o ancho foliar), lo que se traduce en que la línea de regresión (la línea de la relación promedio entre X y Y) la variación es la misma para todos los valores de X, ya que no aumenta ni disminuye conforme varía X (Gujarati & Porter, 2010). De manera gráfica se presenta un patrón de residuos al azar y, por ende, una ausencia de tendencia (sesgo) en los residuos de los dos modelos exponenciales que presentan una correlación igual a cero (r = 0,0000), lo cual concuerda con lo señalado por Fox y Weisberg:
Los residuos ordinarios no están correlacionados con los valores ajustados o, de hecho, con cualquier combinación lineal de los regresores, incluidos los propios regresores, y así los patrones en las gráficas de los residuos ordinarios versus las combinaciones lineales de los regresores pueden ocurrir solo si uno o más supuestos del modelo son inapropiados. (2019)
Ello se evidencia en los gráficos de dispersión de residuos vs. los valores ajustados (figuras 7).
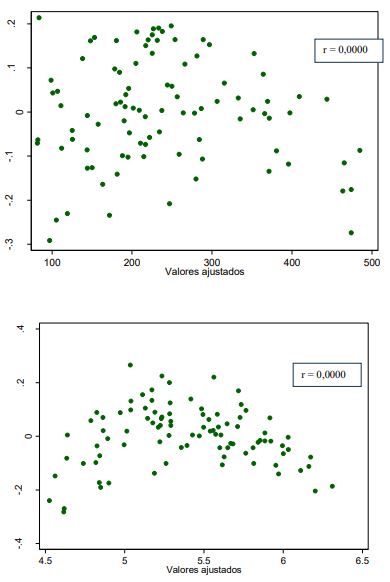
Fuente: Elaboración propia
Figuras 7 Dispersión de residuos vs. valores ajustados de las regresiones exponenciales de área foliar vs. largo y área foliares vs. ancho foliar de G. arborea
Asimismo, se determinaron las ecuaciones alométricas que relacionan el AFE basado en el modelo exponencial 𝐴𝐹𝐸 = 28,0105𝑒0,1192𝐿𝐹 y el AFR, como también el AFE soportado en el modelo exponencial 𝐴𝐹𝐸 = 35,2523𝑒0,1421𝐴𝑛𝐹 y el AFR con el cumplimiento de los criterios de bondad de ajuste: R2, ECM, p-valor de coeficientes [(p)βx], análisis de residuos (normalidad prueba de Shapiro-Wilk, homocedasticidad prueba de Breusch-Pagan) y AIC (tabla 8 y figuras 8).
Tabla 8 Modelo exponencial correspondiente a AFE vs. AFR en relación con el LF y AnF de G. arborea

Fuente: Elaboración propia
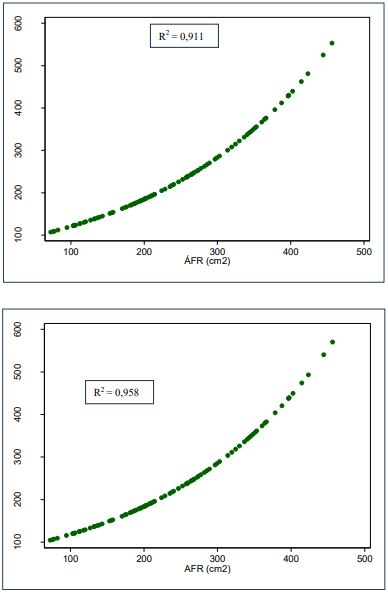
Fuente: Elaboración propia
Figuras 8 Gráficos de regresión exponencial de AFE basada en el LF vs .AFR y AFE basado en el AnF vs. AFR de G. arborea
Lo anterior señala que el AFR explica la variabilidad del AFE basado en el LF en un 91,1 %, lo cual indica que el modelo exponencial 𝐴𝐹𝐸 = 78,2762𝑒0,0042𝐴𝐹𝑅 tiene un alto grado de confiabilidad. Asimismo, el AFR explica la variabilidad del AFE basado en el AnF en un 95,8 %, lo que muestra que el modelo exponencial 𝐴𝐹𝐸 = 75,6996𝑒0,0044𝐴𝐹𝑅 tiene un alto grado de confiabilidad.
Respecto a la selección de los mejores modelos de estimación del objeto de estudio por diversos autores, la determinación de áreas foliares desde ecuaciones de regresión simples se han formulado a partir del modelo lineal simple, estimando el AFE desde el LF (𝐴𝐹𝐸 = 𝛽𝑜 + 𝛽1𝐿𝐹) en especies vegetales como la albahaca (R2 = 0,73) (Ruiz-Espinoza et al., 2007), el níspero (R2=0,90) (Portillo et al., 2004) y la papaya (R2 = 0,93) (Cardona et al., 2009) (tabla 9), concordando las dos últimas especies con el modelo de regresión simple que estimó el AFE con el LF con un R2 = 0,91 en melina de este trabajo (tabla 7).
Tabla 9 Modelos alométricos simples para la determinación del AF en diversas especies vegetales
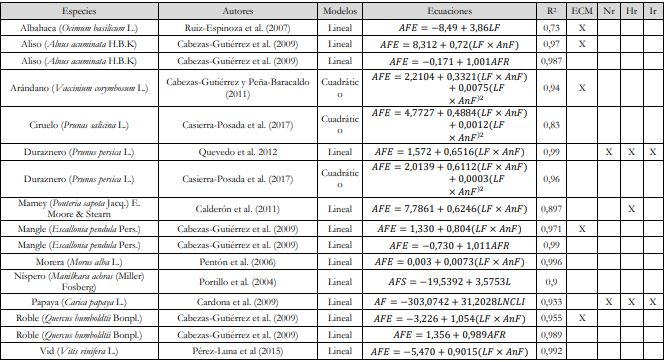
Notas aclaratoriasECM: error cuadrático medio, Nr: normalidad de residuos, Hr: homocedasticidad de residuos e Ir: independencia de residuos.
Fuente: Elaboración propia
Asimismo, al seguir el modelo lineal simple se ha estimado el AF a partir del producto 𝐿𝐹 × 𝐴𝑛𝐹 (𝐴𝐹𝐸 = 𝛽𝑜 + 𝛽1𝐿𝐹 × 𝐴𝑛𝐹) en las especies de aliso (R2 = 0,97) (Cabezas-Gutiérrez et al., 2009), duraznero (R2 = 0,99) (Quevedo et al., 2012), mangle (R2 = 0,97) (Cabezas-Gutiérrez et al., 2009), mamey (R2 = 0,89) (Calderón et al., 2011), morera (R2 = 0,99) (Pentón et al., 2006), roble (R2 = 0,95) (Cabezas-Gutiérrez et al., 2009) y vid (R2 = 0,99) (Pérez-Luna et al., 2015) (tabla 9).
Además, Cabezas-Gutiérrez et al. (2009) relacionaron el AFE y el AFR a partir del modelo lineal simple (𝐴𝐹𝐸 = 𝛽𝑜 + 𝛽1𝐴𝐹𝑅) en las especies de aliso (R2 = 0,98), mangle (R2 = 0,99) y roble (R2 = 0 ,98) (tabla 9), difiriendo de los dos modelos exponenciales 𝐴𝐹𝐸 = 𝛽𝑜𝑒𝛽1𝐴𝐹𝑅 que relacionaron tales variables en melina de este trabajo: modelo 1. 𝐴𝐹𝐸 = 78,2762𝑒0,0042𝐴𝐹𝑅 (tabla 8), donde el AFE proviene del producto exponencial del AFR vs. LF, 𝐴𝐹𝐸 = 28,0105𝑒0,1192𝐿𝐹 (tabla 7) y modelo 2. 𝐴𝐹𝐸 = 75,6996𝑒 0,0044𝐴𝐹𝑅 (tabla 8), donde el AFE proviene del producto exponencial del AFR vs. AnF, 𝐴𝐹𝐸 = 35,2523𝑒 0,1421𝐴𝑛𝐹 (tabla 7).
En cuanto a los modelos cuadráticos para la estimación del AF formulados por Cabezas-Gutiérrez y Peña-Baracaldo (2012) para arándano y Casierra-Posada et al. (2017) para ciruelo y duraznero (tabla 9), no fue posible hacer la comparación con los modelos cuadráticos de las estimaciones de área foliar para melina de este trabajo, porque estos últimos no cumplieron con algunos criterios de bondad de ajuste, lo que invalidaba la ecuación planteada.
Por otra parte, en la mayoría de trabajos se toma como criterio de bondad de ajuste el R2 y en otros se le suma el error cuadrático medio cuando hay más criterios de bondad de ajuste que son necesarios utilizar, como el p-valor de los coeficientes de regresión y el análisis de los residuos desde la normalidad, homocedasticidad, independencia y gráficos de residuos, para así tener más elementos de juicio que permitan darle validez al modelo de regresión seleccionado, como lo plantearon Quevedo et al. (2012) en la estimación de AF en duraznero y Cardona et al. (2009) en la estimación de AF en papaya (tabla 9).
Conclusiones
La necesidad de establecer, desde la estimación estadística, el AF en función de las variables dendrométricas de largo y ancho foliar en melina (Gmelina arborea Roxb. ex Sim.) en el sistema silvopastoril Sinpar en Barrancabermeja, Santander, procura impactar a nivel investigativo, social y ambiental, puesto que se persigue aportar conocimiento relacionado con el crecimiento de las plantas, por ser el AF un parámetro importante en la evaluación de variables como la tasa específica de hojas, la tasa de asimilación neta y la tasa de transpiración, entre otros. Por lo anterior, se recomienda la continuidad en este tipo de estudios en las especies arbóreas que conforman los sistemas silvopastoriles por su doble función: la restauración ecológica de paisajes degradados y la alimentación del ganado, al establecerse el volumen y la oferta de forraje.
El AFE en melina G. arborea, desde la variable LF, corresponde a la ecuación de regresión exponencial 𝐴𝐹𝐸 = 28,0105𝑒0,1192𝐿𝐹, como también desde la variable AnF compete a la ecuación de regresión exponencial 𝐴𝐹𝐸 = 35,2523𝑒0,1421𝐴𝑛𝐹, cumpliéndose en ambas regresiones los criterios de bondad de ajuste como R2, ECM, p valor de coeficientes, análisis de residuos (normalidad, homocedasticidad, dispersión de residuos vs. valores ajustados) y AIC.
Los modelos exponenciales 𝐴𝐹𝐸 = 28,0105𝑒0,1192𝐿𝐹 y 35,2523𝑒0,1421𝐴𝑛𝐹 tienen un elevado grado de confiabilidad para su uso en predicciones del área foliar a partir del LF y el AnF en la especie melina G. arborea.
La relación del AFE basada en el LF vs. el AFR se soporta en la ecuación de regresión exponencial 𝐴𝐹𝐸 = 78,2762𝑒0,0042𝐴𝐹𝑅 e igualmente la relación del AFE basada en el AnF vs. el AFR se sustenta en la ecuación de regresión exponencial 𝐴𝐹𝐸 = 75,6996𝑒0,0044𝐴𝐹𝑅, cumpliéndose los criterios de bondad de ajuste como R2, ECM, p valor de coeficientes, análisis de residuos (normalidad, homocedasticidad) y AIC en ambas regresiones.
Los modelos exponenciales 𝐴𝐹𝐸 = 78,2762𝑒0,0042𝐴𝐹𝑅 y 𝐴𝐹𝐸 = 75,6996𝑒0,0044𝐴𝐹𝑅 tienen un alto grado de confiabilidad para su uso en predicciones del AFE basado en el LF vs. el AFR y predicciones del AFE basadas en el AnF vs. el AFR en la especie melina G. arborea.
Contribución de los autores
Carlos Augusto Vásquez Rojas: supervisión del proyecto, selección de información, análisis de datos, elaboración, revisión y corrección del manuscrito; Emiro Rafael Canchila Asencio: administrador del proyecto, implementación del sistema silvopastoril SINPAR, selección de información, toma de información en campo y laboratorio, análisis de datos y elaboración, revisión y corrección del manuscrito; Jorge Humberto Contreras Castro: selección de información, toma de información en campo y laboratorio, construcción y análisis de bases de datos, elaboración, revisión y corrección del manuscrito; Javier Sarmiento Estupiñán: adquisición de recursos, logística, selección de información, análisis de datos, elaboración, revisión y corrección del manuscrito.

