











 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink1. Introduction
The World Health Organization (WHO) reports in the Global status report on road safety 2018 that more than half (54%) of the road traffic deaths corresponds to Vulnerable Road Users (pedestrians, cyclists, motorcyclists) [1]. From this rate, 28% corresponds to Motorcycles. The annual report Traffic Accidents of the Andean Community (Bolivia, Colombia, Ecuador and Perú) [2] documented 347,642 traffic accidents, 88% of them occurred in urban areas. In this region, for year 2017, Colombia has 57.35% of the total traffic accidentally rate, reporting 171,571 occurrences with 6,479 fatal victims. Although for 2017 deaths due to transport accidents were reduced by 7.23% compared to 2016, these numbers still high compared to world statistics [3]. Motorcyclist are the road users most affected by traffic accidents in Colombia, reporting 49.82% of deaths and 56.36% injured victims [3]. This high accidentallity rate can be partially explained due to that 58% of the 14.880.823 total vehicles registered in Colombia for 2019 2Q corresponds to Motorcycles [4], and 76.64% of these motorcycles belongs to the street sport segment which is used as a regular transport mean.
Air quality is also an issue in the main cities of Colombia. The National Planning Department (DNP) estimated that, during 2015, the effects of air pollution were associated with 10,527 deaths and 67.8 million symptoms and diseases [5]. The contaminant with the greatest potential for affectation is Particulate Material Less than 2.5 microns (PM2.5), which is made up of very small particles, produced mainly by heavy vehicles that use diesel as fuel, and which can carry very dangerous material for human body such as heavy metals, organic compounds and viruses, thus affecting the respiratory tract [6]. In Colombia, 59% of PM2.5 is produced by land transportation, from which 40% corresponds to motorcycles. It is therefore desirable to monitor urban motorcycle traffic to reduce incidents and air pollution on what are becoming very congested roads.
Video analytic techniques for vehicle detection have been used in urban traffic analysis, reporting success for detecting regular vehicles (bus, cars, trucks), but there is scarce literature on the analysis of motorcycles as major users in many urban environments, characterised by frequent occlusion between vehicles in congested traffic conditions.
In this paper, we introduce EspiNet V2 a deep learning model based on the two-stage detector Faster R-CNN [7] (Faster Regions with Convolutional Neural Networks features). The model is used to detect motorcycles in congested urban traffic scenes. The paper is structured as follows; section 2 reviews the literature on motorcycles detection, section 3 gives a brief introduction to deep CNN and Faster R-CNN, section 4 explains the proposed EspiNet V2 model, detailing its architecture and main differences w.r.t Faster R-CNN. Section 5 describes the different experiments done employing the UMD-10K and SMMD datasets, providing a results analysis. The article finishes with section 6 with conclusions and proposed future work.
2. Motorcycle detection
Video analytics supports most of the current urban traffic analysis and vehicle detection systems. Traditional approaches for vehicle detection extract discriminative features for vehicle representation, which later implement classification, usually using classifiers trained on those features. Features are generally extracted from object appearance or derived from motion information [8].
Motorcycle detection works based on appearance features such as edge maps are introduced in [9] using Gabor filters and the Sobel operator [10] to reduce illumination variances. Other approaches use corner detection with Harris corners [11], or even using Haar-like features [12,13], despite the poor correlation under different view angles. Feature descriptors such as Histogram of oriented gradients (HOG), Scale-invariant feature transform (SIFT), and Local binary patterns (LBP) are compared in [14] and [15] for motorcycle detection. For helmet detection in motorcycles riders Speeded up robust features (SURF), Haar-like features (HAAR) and HOG [16] have been used as feature descriptors. Meanwhile, in [17], they use hybrid descriptor based on colour for helmet identification. Appearance features based on computer-generated 3D models are used to discriminate between motorcycles and bicycles in [18], and between car/taxi, bus/lorry, motorbike/bicycle, van, and pedestrian in [19]. Background subtraction uses spatio-temporal information for detecting a moving object in a giving scene. Motorcycle detection [20,21] starts with this technique and uses segmentation to detect and separate motorcycles in the analysis. In some works, a similar approach is used, even to detect motorcycle riders without a helmet [24-29].
The most used algorithm for background subtraction is Gaussian Mixture Models (GMM) [22], used in [23,24]. For dealing with object shadows and for continuous update of parameters, Self Adaptive GMM [25] is used in [26] or adaptive background modelling used in [14] and [15]. Nevertheless, background subtraction may fail in congested scenarios or where the objects overlap each other, difficulting their detection, with camera movements, or when objects tend to become part of the background, after a prolonged static sequence as typical in traffic jams.
Motorcycle detection in [24] uses spatial features in conjunction with motion features obtained from optical flow, this type of features is useful for obstacle detection in a Lane Change Assistant (LCA) system [10].
The most frequently classifiers used for motorcycles classification are Support Vector Machines (SVM), used for classifying and counting motorcycles in [9], where object occlusion is avoided capturing images from a top-view point. For helmet detection, different types of kernels are compared in [14] and [15] using background subtraction for object detection. Head regions described by histograms are also used for helmet detection in [27], which are later classified by a linear SVM. This method may fail with drastic changes of illumination. SVMs are also used for classifying a multi-shape descriptor vehicle [25,26] demanding high computational resources for the descriptor construction and evaluation. There is also a proposed Real-Time on Road Vehicle Detection system [10], which uses a binary SVM classification by hierarchies, boosting its performance thanks to an Integrated Memory Array Processor (IMAP) architecture. Nonetheless, the model can fail in adverse weather conditions with low illumination. SVMs for motorcycles detection are also used in conjunction with Bag of Visual Words (BoVW) [28] with a Radial basis function kernel (RBF) or using HOG as a feature descriptor [29], even with 3D models as appearance features [18,19].
Other classifiers used are decision trees for Overhead Real-Time Motorbike Counting [30], where the method relies on the camera specification for decision tree rule construction. Neural networks (NN) such as the Multilayer Perceptron (MLP) have been proposed for motorcycle detection and classification, even though their architectures require tuning of many parameters and the implemented loss function may not converge to a local optimum. Nevertheless, NN are used for helmet detection in [16,31]. There is also Fuzzy neural network (FNN) [24], but without a significant number of motorcycles to detect in their dataset. Finally, K-Nearest Neighbor (KNN) is also used for Helmet detection [23]; nevertheless, this model relies on the background subtraction accuracy for motorcycle individualisation, which may fail in occluded scenarios.
2.1. Deep learning for motorcycle detection
In recent years deep learning has erupted in the field of computer vision showing impressive results, mainly due to the computing capacity that GPUs (Graphics Processing Units) provide for training models, as well as the creation of vast manually labelled datasets of generic objects.
The work of Vishnu et al. [32] use Convolutional Neural Networks (CNNs) as feature extractors in combination with background subtraction for object detection. Once the object is detected, for instance using GMM, the features extracted using the CNN model (e.g., AlexNet), are used to perform classification [33]. Instead of background subtraction, object localisation uses selective search as in [34]. Nevertheless, the work in [35] proposes a straightforward CNN for detecting and classifying motorcycles. The input image is passed through the feature extraction layers generating a motorcycle score map. This score map is thresholded followed by non-maximal suppression for individual motorcycle detections. Most recent works are oriented to detect helmet violation for motorcycle users. For instance, in [36], motorcycles are detected using HOG+SVM, and later, the riders head area is supplied to a CNN model for helmet presence detection. The work in [32] proposes a similar approach. Meanwhile, in [37], moving objects are detected using motion detection algorithms, a pedestrian CNN model is used to detect humans, later a CNN is used again to detect the presence of helmet and the colour of it.
Unfortunately, the analysed literature lacks a unified metric for reporting results and most of the methods use proprietary datasets which are seldom available for comparison and use by the research community.
3. Deep CNN networks and Faster R-CNN
Convolutional Neural Networks (CNNs) are a type of neural network, whose architecture is based on convolutional filters able to capture spatial patterns and that reduce the computational burden of learning parameters. This approach produces features invariant to scale, shift or rotation as the receptive fields provide the neurons access to primitive features such as oriented edges and corners in the initial convolutional layers, which are then aggregated generating more complex features going deeper in the model. Features derived from CNNs often outperform feature descriptors such as HOG, SIFT, SURF, LBP [38,39].
While features obtained from CNNs are very useful for classification, the problem of object detection not only involves the classification of the objects but their localisation in the image. When Spatio-temporal information is available (video sequences), approaches such as background subtraction, optical flow or motion detection algorithms, help to identify moving objects, extracting features from the detected blobs, which are later classified. This approaches may fail due to camera movement, static objects, or even illumination changes. The lack of Spatio-temporal information as in single or static images (frames) forces the use of approaches that combine sliding window search (which slides a window e.g. from left to right, and from up to down in the image extracting patches later used for classification) with binary classifiers (object vs background). Object proposal algorithms, like Branch & Bound [40], Selective search [41] Spatial Pyramid Pooling [42] and Edge boxes [43] are approaches designed to deal with the large numbers of windows useful to cover different aspect ratios and scales.
Two-stage detectors as R-CNN (Regions with CNN features) [44] use selective search to generate up to 2,000 regions which are provided to a CNN to produce a feature vector later fed into SVM to determine the occurrence of an object and the values necessary to adjust the bounding box to the detected object. Since the number of selective search proposals is fixed and is a time-consuming task, Fast R-CNN [45] feeds the input image to the CNN to generate a feature map, identifying the proposal regions which are later warped and fed into a fully connected layer using a Region of Interest (RoI) pooling layer. This model reduces computational time due to the use of only one convolution operation per image instead of 2000 of the R-CNN model. Nevertheless, the Region Proposal is still the bottleneck during testing time.
Faster R-CNN [7] speeds up the detection process, eliminating the use of selective search and using a CNN model which simultaneously learns region proposal and perform object detection. As in Fast R-CNN, the input image is passed through the CNN model generating a feature map, over this feature map the Region Proposal Network (RPN) deploys a sliding window to generate n bounding boxes with their associated scores per window. These n boxes are called anchor boxes and represent common sizes and aspect ratios that objects can have. A RoI pooling layer is used to reshape predicted region proposals, classifying the image inside the proposed region and generating the offset values for bounding boxes using regression (Fig. 1).

4. EspiNet V2
EspiNet V2 (Fig. 2) is a deep learning model proposed here that is based on the region based detector Faster R-CNN. This model is used to detect motorcycles in congested urban traffic scenes. Occluded scenarios are frequent on urban traffic analysis (Fig. 3). General vehicle detection in urban conditions has been studied by many authors. Occluded situations has been analysed using the KITTI dataset [47], which unluckily lacks a motorcycle category. EspiNet V2 is an improved version of the one presented in [48]. This new model increases the number of convolutional layers, pursuing to capture more aggregate features that contribute to identify motorcycles in the given images.

Source: The authors.
Figure 2 EspiNet V2, the Proposed CNN Model. The same model implements RPN and classification.

Source: The Authors.
Figure 3 Example image of the Urban Motorbike Dataset. The smallest object size is 25 px. Occlusions are frequent between motorcycles and other vehicles.
EspiNet V2 is publicly available for download (https://github.com/muratayoshio/EspiNet). The model can detect motorcycles in congested urban scenarios and, as in Faster R-CNN, unifies two networks: a Region proposal network (RPN) and a Fast R-CNN [45] detector, sharing the convolutional layers between the two architectures. The main difference between EspiNet V2 and Faster R-CNN lies in the CNN implemented. The best results of Faster R-CNN are obtained working with quite deep models such as VGG-16 [49] having 16 weight layers, 13 of them convolutional and ~ 138 million parameters to be learned. EspiNet V2 uses a more concise CNN network with only six layers (4 convolutional) reducing the number of parameters to learn (~2 million), still outperforming Faster R-CNN in the chosen task (see section V).
Table 1 shows in detail the configuration and parameters of the EspiNet V2 model.

The input size for classification is the size of the training images. Meanwhile, for detection task, the input layer is a tensor of 32x32x3 (32x32 pixels, 3 channels), considering that in UMD-10K and SMMD datasets the smallest annotated object has a size of 25 pixels. This input layer is zero-center normalised, and its size is determined according to the processing time and the spatial detail the CNN model has to resolve. The first convolutional layer has 64 filters of size 3x3. The same filter size is used for all the convolutional layers to produce a small receptive field, to capture smaller and complex features in the image and optimise the weight sharing process. Each convolutional layer is followed by a ReLU (rectified linear unit) layer, making the learning process computationally efficient, speeding up convergence and reducing the vanishing gradient effect.
The last two convolutional layers duplicate the number of filters, capturing more complex features, later used for motorcycle recognition due to its enriched image representation [50]. As in Faster R-CNN Faster R-CNN [7] architecture, a max RoI pooling layer is used after the four convolutional filters for detection purposes, it removes redundant spatial information, reduces and fixes the feature map spatial size.
This layer is set to a 15x15 pixels grid covering the smallest detected object. It is the only max-pooling layer in the model since prematurely down-sampling data can lead to loss of important information necessary for learning [51]. After the first fully connected (FC) layer (64 neurons) combines all features extracted in the previous layers, which is corrected next by a ReLU layer, finally combined in the second fully connected layer. The last layer of the model is a softmax layer, which normalises the output of the previous FC layer, providing a confidence measure and computing the loss of the model. Fig. 2 shows the schematic model of EspiNet V2 network.
The multi-task loss function defined for one image is:
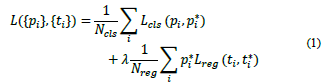
In eq. (1)i is the anchor index in a mini-batch (with positives and negatives examples anchors), p i is the predicted probability that the anchor i is an object. The ground truth (gt) p i * has label 1 if the anchor is positive, 0 is the anchor is negative. t i represents the predicted bounding box using a vector of 4 parametrised coordinates, where t i * is the gt box coordinates vector related to a positive anchor.
The classification loss L cls part uses a logistic regression cost function. Meanwhile for the bounding box regression loss part L reg (t i ,t i *) the robust loss function (smooth L 1 ) is used.

in which

In this bounding box regression, each coordinate is parameterized as follows:
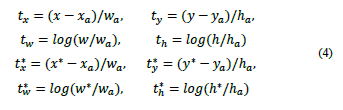
where x, y, corresponds to the boxs center coordinates, w, and h its width and height. Variables x corresponds to predicted box, x a anchor box and x * ground-truth box, (similarly for y, w and h variables). This can be assumed as a bounding-box regression from an anchor box to the closest ground truth box. The coordinates of the bounding box are values [0,1] which are relative to a specific anchor. For example, t y denotes the coefficient for y (box center x,y). If t y is multiplied by h a and then add y a we get the predicted y. The rest of parameters can be calculated in the same way.
Training comprises four steps using an alternating optimisation. The first two steps train the RPN and the detector network separately. For these first two steps, EspiNet V2 uses a learning rate of 1e-5 trying to obtain a fast convergence, as it is trained from scratch, and no pre-trained models are used for the shared convolutional layers [7]. Once the shared convolutional layers are trained and fixed, the last two steps fine-tuning the unique layers of the RPN and Fast R-CNN detector, using a learning rate of 1e-6 for a smoother process.
The optimisation training algorithm used in all the described steps is Stochastic Gradient Descent with Momentum (SGDM) (eq. (5)).
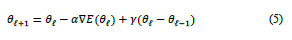
where
 is the iteration number, the learning rate is defined as α > 0, weights and biases define the parameter vector θ and E(θ) is the loss function. The algorithm is stochastic since it uses a subset of the training set (minibatch) to evaluate and update the parameter vector. One iteration corresponds to each evaluation of the gradient using the mini-batch. At each iteration, the algorithm takes one step towards minimising the loss function. One epoch encompasses the full pass of the training algorithm over the entire training set using mini-batches. For EspiNet v2, the number of epochs is defined after training analysis [48]. The momentum term γ regulates the contribution of the previous gradient step to the current iteration and is used to avoid oscillation along steepest descent to the optimum.
is the iteration number, the learning rate is defined as α > 0, weights and biases define the parameter vector θ and E(θ) is the loss function. The algorithm is stochastic since it uses a subset of the training set (minibatch) to evaluate and update the parameter vector. One iteration corresponds to each evaluation of the gradient using the mini-batch. At each iteration, the algorithm takes one step towards minimising the loss function. One epoch encompasses the full pass of the training algorithm over the entire training set using mini-batches. For EspiNet v2, the number of epochs is defined after training analysis [48]. The momentum term γ regulates the contribution of the previous gradient step to the current iteration and is used to avoid oscillation along steepest descent to the optimum.
5. Experiments and results
5.1. Motorbikes datasets
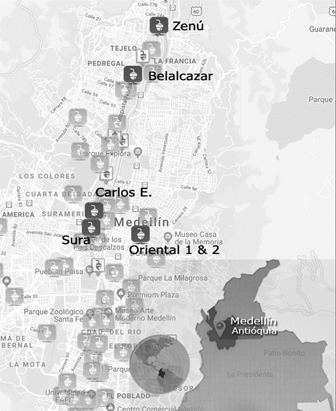
To train and evaluate the proposed model, two datasets are used: The UMD-10K dataset, which is an extension of [48], with 10,000 annotated images including 317 motorcycles with 56,975 individual annotations (bounding boxes). 60% of the annotated data corresponds to occluded motorcycles (See Fig. 3). Moreover, the Secretaría de Movilidad de Medellín created the Sistema Inteligente de Movilidad de Medellín (Intelligent Mobility System of Medellín) [52], which includes a CCTV with 80 cameras to monitoring urban traffic conditions in this Colombian city. From this network of cameras, we selected six strategic surveillance located cameras (Fig. 4) to create the SSMD dataset with 5,000 images, containing 21,625 annotated motorcycles (817 different motorcycles). (Fig. 5). These dataset are available from http://videodatasets.org/UrbanMotorbike.
Source: The Authors.
Figure 4 Localisation map of the 80 cameras of the CCTV Secretaría de Movilidad de Medellín [52]. Six cameras are selected for this research.

5.2. Results on the UMD-10K dataset
The performance of previous experiments in [48] achieved a 75.23% of Average Precision (AP) [53], training and evaluated on the UMD-7.5k, with 7,500 examples.
EspiNet is now compared with two models: YOLO V.3 [54] as a single-stage detector and for a two-stage detectors, the original Faster R-CNN [49] (VGG16 based). We selected these models since they have been extensively used to compare new proposals, and because of their good performance and their availability in the public domain. All these models were trained end to end from scratch, using the challenging UMD-10k dataset.
As is recommended by [55] an due to the large number of examples needed to train, the three models use 90% (9,000 images) of the UMD-10k dataset for training data, while the remaining 10% (1,000 images) are used for validation. The selection of training and test set is done randomly to avoid any bias in the distribution.
The proposed EspiNet V2 model obtain of 88.8% of AP and 91.8% of F1-score [56], which outperforms results for YOLO and Faster R-CNN (VGG16 based). Table 2 shows the comparative results. Fig. 6 presents a graphic comparison of the three models Average Precision (AP).
Table 2 EspiNet model against Faster-RCNN (VGG16 based) [49] and YOLO V3 [54], comparative results - Results on UMD dataset.

Source: The Authors.

Source: The Authors
Figure 6 Average Precision (AP) of the model compared with YOLO V3 and Faster R-CNN (VGG16 based). Results on UMD-10K dataset.
In all metrics, EspiNet obtains better results than the other two detectors, being YOLO V3 the closest performance. YOLO achieved almost equal precision but a reduced recall since the single stage detector architecture has not Region Proposal Network (RPN), failing to detect too small objects or that appear too close each other.
The results of the detectors applied to the UMD-10K dataset can be seen on https://goo.gl/bJM3HF
5.3. Results on SMMD dataset
On the Secretaría de Movilidad de Medellín dataset (SMMD), we train EspiNet, Faster R-CNN (VGG based) and YOLO V3 end to end using the same proportion of training and evaluating sets of UMD-10k.
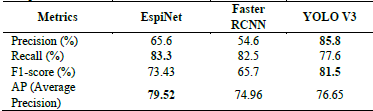
Table 3 shows that EspiNet V2 over-perform YOLO V3 and Faster R-CNN in the terms of AP, reaching 79.52 and with a Recall of 83.39. This can be explained again by the absence of RPN in YOLO V3, which fails to detect objects that appear too close or too small. Nevertheless, YOLO V3 can deal better with false detections, outperforming the region based detectors (EspiNet V2 and Faster R-CNN) in terms of Precision, consequently improving the final F1 score. Fig. 7 shows the comparative performance of the three detector in terms of Average Precision (AP).

Source: The Authors.
Figure 7 Average Precision (AP) of the model compared with YOLO V3 and Faster R-CNN (VGG16 based). Results on Secretaría de Movilidad de Medellín Dataset (SMMD).
EspiNet V2 and the Faster R-CNN (VGG 16 based) models were trained on a Windows 10 Machine with a CPU core i7 7th generation 4.7 GHz, with 32 GB of RAM using a NVIDIA Titan X (Pascal) 1531Mhz GPU.
On UMD-10k dataset, the training process of EspiNet V2 model took 32 hours and 47 hours for training Faster R-CNN (VGG 16) model. A Linux machine running Ubuntu 16.04.3, with a Xeon E5-2683 v4 2.10GHz CPU, 64 GB of RAM and a NVIDIA Titan Xp 1582 Mhz GPU was used for training YOLO V3. This model took 18 hours for training on UMD-10k dataset. All models were trained end to end from scratch.
The time employed for training the model for the SMMD dataset were 24 hours for EspiNet V2, 35 hours for Faster R-CNN (VGG 16) and 14 hours for YOLO, using the same environments described previously.
6. Conclusions and future work
This paper has introduced EspiNet V2, a model derived from Faster R-CNN, for motorcycle detection in urban scenarios. The model can deal with occluded objects achieving an Average Precision of nearly 90% for UMD-10K, as far as we know the most challenging urban motorbike detection dataset at present. It achieves almost 80% AP in the new SMMD, also a challenging dataset made public for other researchers to improve on these baseline results.
EspiNet V2 and the deep learning detectors models as YOLO V3 and Faster R-CNN (VGG16 based) are compared in this study. The models were trained in the UMD-10k and SMMD datasets, and EspiNet V2 was found to outperform the others in terms of Average Precision (AP).
As per most deep learning architectures, and is also evaluated in [57], the model obtains better results as the number of training examples increases. It is important to have enough representative data for each distribution of examples used for train a deep learning model. The amount and distribution of examples used in these two datasets explain the quality of the classification obtained.
The use of spatio-temporal information could be integrated to the model to improve detection capabilities. EspiNet V2 could be used as a neural network layer that incorporates not only the current time step input information (frame) but also the activation values of previous time steps (previous frames). This architecture corresponds to Recurrent Neural Networks (RNNs) such as Gated Recurrent Units (GRUs) or Long short-term memory (LSTM) which apply sequence modelling for predicting next stages after initial detection according to historical information. This improvement could lead to detection by tracking, where the models can spread their detection class scope to include other urban road users like pedestrians, cyclists, trucks, buses, etc.

