











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
PermalinkINTRODUCCIÓN
Las oposiciones fonológicas entre diversas lenguas pueden variar en función de diferentes pistas acústicas tomadas como prioritarias en cada idioma. Si bien estas pistas pueden ejercer un estatus fundamental en una determinada lengua, en otras pueden desempeñar un papel menos importante. Las diferencias fonológicas se establecen en función de los pesos asignados a las pistas acústicas -cue weighting (Holt & Lotto, 2006)- en cada sistema. Por este motivo, en la adquisición de los contrastes fonológicos de una lengua extranjera, es posible que los estudiantes sientan la necesidad de notar algunas pistas acústicas que no desempeñan un papel relevante en las distinciones funcionales en su LI (Sundara, 2005; Kong, Beckman, & Edwards, 2012). Como ejemplo, podemos citar el voice onset time (VOT), que corresponde a una pista fundamental de las consonantes oclusivas1. Mientras que en inglés la distinción entre /p/ /t/ /k/ y /b/ /d/ /g/, en posición inicial de palabra, se da en función de la presencia o ausencia de aspiración (Lisker & Abramson, 1964; Schwartzhaupt, Alves, & Fontes, 2015), en lenguas como el español y el portugués otros patrones y pistas acústicas, tales como la presencia/ausencia de prevoceo, la frecuencia fundamental de la vocal siguiente a la oclusiva y la propia intensidad de la explosión de aire (en inglés, burst) pueden desempeñar un rol prioritario para las distinciones de sonoridad de los segmentos oclusivos (Alves & Motta, 2014; Alves & Zimmer, 2015; Alves & Luchini, 2016).
Los datos de Alves y Zimmer (2015) confirman la importancia de prestar atención a nuevas pistas. En el citado estudio, investigamos la percepción de tres diferentes patrones naturales de VOT por parte de estudiantes brasileños de niveles básico y avanzado de inglés: VOT negativo, encontrado variablemente en /b/, /d/, /g/ iniciales en inglés, y categóricamente en las oclusivas sonoras iniciales del portugués y del español (Lisker & Abramson, 1964); VOT positivo, encontrado en los segmentos /p/, /t/, /k/ iniciales del inglés (Lisker & Abramson, 1964; Cho & Ladefoged, 1999); y VOT cero, que puede ser encontrado variablemente en los segmentos /b/, /d/, /g/ (Lisker & Abramson, 1964) en posición inicial de palabra del inglés y categóricamente en los segmentos /p/, /t/, /k/ del español y del portugués (Lisker & Abramson, 1964; Abramson & Lisker, 1973).
Además de estos tres patrones, en el experimento del estudio en cuestión también se incluyó un patrón manipulado (denominado de VOT cero artificial). Se trata de la remoción de la aspiración de los segmentos sordos iniciales /p/, /t/, /k/ de la lengua-meta, con el fin de que, en términos de VOT, tales segmentos remitieran a un segmento sonoro del inglés, a pesar de presentar todas las otras características acústicas (intensidad de la explosión y frecuencia de F0, entre otros) de un segmento sordo.
Como resultados, Alves y Zimmer (2015) demostraron que los estudiantes brasileños presentaban valores altos de identificación de los patrones VOT negativo y positivo como instancias de segmentos sonoros y sordos, respectivamente. Además, aunque el patrón de VOT cero natural tendiese a ser identificado como sonoro, las consonantes con el patrón híbrido de VOT cero artificial fueron identificadas como sordas. Tales resultados sugieren que, en la identificación de los patrones de sonoridad de la L2, los estudiantes brasileños tienden a prestar atención a otras pistas más allá de la presencia/ ausencia de aspiración.
El mismo experimento ya había sido realizado con hablantes monolingües de inglés (Schwartzhaupt et al., 2015) y con estudiantes argentinos de inglés (Alves & Luchini, 2016). Los estudiantes argentinos demostraron los mismos patrones encontrados entre los participantes brasileños. En otras palabras, el VOT no se muestra como la pista acústica fundamental para la distinción de oclusivas sordas y sonoras iniciales en portugués ni en español. Sin embargo, en el mismo experimento realizado con hablantes nativos de inglés (Schwartzhaupt et al., 2015), comprobamos un patrón de respuestas contrario al verificado en el estudio con los argentinos, debido a que los participantes norteamericanos presentaron altos índices de identificación de ambos patrones de VOT cero (natural y manipulado) como sordos.
Asimismo, comprobamos el estatus fundamental de la presencia o ausencia de aspiración para distinguir entre segmentos sordos y sonoros iniciales del inglés. A partir de estos datos, verificamos que los estudiantes brasileños y argentinos deben ser instruidos, implícita o explícitamente, a prestar atención a la pista referente al VOT positivo, porque solamente después de reconocer el rol fundamental de tal pista en la lengua-meta podrán producir la aspiración característica de los segmentos oclusivos iniciales en la L2.
Por lo tanto, para lograr que el estudiante de L2 preste atención a pistas acústicas, destacamos el rol y la importancia que adquieren las tareas de enseñanza y de laboratorio, tales como el entrenamiento perceptivo (Reis & Nobre-Oliveira, 2008; Aliaga-García, 2011; Wong, 2012; Rato, 2013; Carlet, 2017; Carlet & Cebrian, 2015, 2019; Cebrian et al., 2019) y la práctica de instrucción explícita2 (Alves & Magro, 2011; Echelberger, 2013; Kissling, 2013; Sicola & Darcy, 2015; Gordon & Darcy, 2016; Sangüesa, 2016; Saito & Hanzawa, 2016; Saito & Saito, 2017) de los sonidos meta.
A partir de varios de los estudios mencionados anteriormente, Alves y Luchini (2017) llevaron a cabo un estudio orientado a verificar la eficiencia del entrenamiento perceptivo frente al desafío de llevar estudiantes argentinos de inglés a prestar atención al VOT como pista acústica prioritaria para diferenciar oclusivas sordas y sonoras iniciales, lo que podría resultar en un aumento tanto en los índices de percepción como de producción de los segmentos oclusivos iniciales de la L2. Este estudio, que contó con la participación de alumnos de nivel C1 y C2 de acuerdo con el Marco Común Europeo de Referencia (MCER)3, tuvo como objetivo investigar la efectividad de la implementación de tareas de entrenamiento perceptivo (agregadas o no a la instrucción explícita) con los estudiantes argentinos.
Los participantes fueron separados en tres grupos: (1) Grupo Experimental 1 (que contó con tres sesiones de entrenamiento, pero no se les informó sobre el aspecto al que deberían prestar atención); (2) Grupo Experimental 2, con entrenamiento similar al del Grupo 1, que además recibió información específica sobre el foco de este (se les solicitó que se concentraran en la aspiración de las consonantes en cuestión); y (3) Grupo Control. Los estímulos auditivos de las sesiones de entrenamiento consistían en datos producidos por seis hablantes nativos de inglés norteamericano, e incluían dos de los cuatro patrones de VOT investigados en estudios previos sobre los patrones de percepción de VOT (Alves & Motta, 2014; Alves & Zimmer, 2015; Alves & Luchini, 2016): VOT positivo y VOT cero manipulado (caracterizado por consonantes oclusivas aspiradas cuyo VOT había sido suprimido). Dado que este último constituía un patrón híbrido, se hizo posible entrenar a los estudiantes para identificar tales consonantes como sonoras, al concentrarse en el VOT como la pista acústica fundamental para las distinciones entre segmentos sordos y sonoros.
Los resultados de Alves y Luchini (2017) demostraron una diferencia significativa entre el pretest y los dos postests (inmediato y tardío) en los índices de aciertos en el test de percepción de los participantes de los dos grupos experimentales, sugiriendo que, con o sin la inclusión de la instrucción explícita, el entrenamiento parecía haber contribuido a la obtención de mejores índices de percepción. En lo que se refiere a la producción de las oclusivas iniciales, se encontraron diferencias significativas entre el pretest y los dos postests (aplicados tres días y un mes después de la intervención) entre los participantes del Grupo Experimental 2, que recibieron instrucción explícita sumada a la tarea de entrenamiento perceptivo.
Aunque los resultados de Alves y Luchini (2017) han demostrado que la tarea de entrenamiento perceptivo genera resultados positivos para la prueba de percepción (independientemente de haber sido incorporada a la instrucción o no), consideramos necesario plantear una serie de cuestiones relacionadas con los datos de producción. En primer lugar, dado que se verificaron resultados significativos en los índices de producción solamente en el grupo expuesto al tratamiento que combinó entrenamiento con instrucción, sería interesante explorar si la aplicación de la técnica de instrucción explícita, desvinculada de la exposición masiva y mecanicista al insumo auditivo, y seguida de oportunidades de práctica auditiva y de producción, ocasionaría los mismos resultados que se observan a partir de la combinación de las dos técnicas empleadas (entrenamiento conjugado a informaciones explícitas con respecto al fenómeno).
Además, nos cuestionamos con respecto a si la práctica de instrucción con oportunidades de práctica de audición y producción (pero sin una exposición mecanicista exhaustiva a los patrones auditivos) sería capaz de contribuir a mayores índices en los resultados de los tests de identificación de oclusivas iniciales sordas y sonoras. En otras palabras, es necesario verificar el rol de la aplicación de cada técnica en la percepción y en la producción de las oclusivas iniciales del inglés.
El presente trabajo, realizado con estudiantes brasileños, tiene como propósito dar respuesta a estos cuestionamientos. Como ya se ha señalado en estudios anteriores (Alves & Motta, 2014; Alves & Zimmer, 2015; Alves & Luchini, 2016), los alumnos hablantes de español y portugués como LI presentan el mismo tipo de dificultades en la adquisición de las oclusivas iniciales de la lengua-meta, dado que la presencia/ausencia de aspiración no corresponde a la pista principal tomada por los aprendices de ambos sistemas de LI. En este contexto, esta investigación tiene por objetivo verificar el papel de las prácticas del entrenamiento perceptivo y de la instrucción explícita, suministrada a dos grupos de aprendices brasileños, tanto en la percepción como en la producción de las consonantes-meta.
METODOLOGÍA
Participantes
Participaron en este estudio 30 estudiantes que fueron divididos al azar en tres grupos de diez estudiantes cada uno. El Grupo i participó en las sesiones de entrenamiento, pero no se le informó el aspecto fonético al cual debería prestar atención, dado que, conforme lo demuestran Alves y Luchini (2017), se observan distintos resultados con respecto a la producción en los participantes a quienes, durante el periodo de entrenamiento, se les indica qué aspectos fonético-fonológicos deben tener en cuenta y focalizar. Diferentemente de Alves y Luchini (2017), los participantes del Grupo 2 recibieron instrucción (integrada a actividades de práctica de audición y producción de carácter controlado). A su vez, el Grupo 3 tuvo el rol de grupo-control.
Los participantes estaban cursando el primer año del curso de Letras-Inglés en la Universidade Federal do Rio Grande do Sul, Brasil, y tenían cinco horas semanales de clases de inglés. Antes de participar en el experimento, todos los estudiantes completaron el Oxford Online Placement Test4. Los resultados de este examen indicaron que los alumnos contaban con un nivel de competencia lingüística en inglés equivalente al C1 o C2, de acuerdo con los estándares del MCER. Todos los participantes firmaron un término de consentimiento informado.
Sesiones de entrenamiento perceptivo
Las sesiones de entrenamiento consistieron en la aplicación de una tarea de identificación con retroalimentación inmediata, previamente aplicada en Alves y Luchini (2017). Dicha tarea fue construida y administrada en el software TP (Rauber et al., 2013), y repetida en cada sesión de entrenamiento. Los estímulos fueron producidos por seis hablantes nativos de inglés norteamericano (tres hombres y tres mujeres).
La tarea contenía 18 archivos de audio. Los ítems léxicos utilizados en las sesiones de entrenamiento fueron pee, tip y kit5. Teniendo en cuenta los estudios de Yavas y Wildermuth (2006) y Schwartzhaupt (2012), utilizamos estímulos seguidos por una vocal alta, ya que este contexto fonético posibilita mayores niveles de aspiración, así como un mayor grado de percepción.
Se contó con seis archivos de audio diferentes para cada uno de estos elementos léxicos, cada uno de ellos producido por un locutor diferente. De estos seis estímulos, tres contaban con la aspiración truncada intencionalmente, de modo que pudiéramos construir el patrón VOT cero artificial (una consonante híbrida, como ya se ha descrito). Cada uno de estos 18 estímulos (nueve con VOT cero artificial y nueve con VOT positivo) se repitió 20 veces en un orden aleatorio, lo que llevó a presentar 360 tokens en cada sesión. Se hicieron pausas después de cada 90 tokens.
En las sesiones de entrenamiento, que consistían en una tarea de identificación6, los alumnos tenían que elegir la consonante inicial de la palabra que acababan de escuchar (/p/, /b/, /t/, /d/, /k/, /g/). También se proporcionó una retroalimentación inmediata después de cada una de las respuestas de los alumnos. Se consideró que los estímulos con VOT cero artificial serían correctos siempre que los alumnos identificaran como sonora la consonante escuchada (y si el punto de articulación era correcto).
Al determinar tal respuesta como correcta, esperábamos entrenar a los estudiantes para no prestar atención a pistas acústicas adicionales, ya que la presencia/ ausencia de aspiración sería decisiva para sus respuestas. Cuando las respuestas no eran correctas, los estudiantes eran informados de la respuesta correcta inmediatamente, viéndose obligados a escuchar los estímulos nuevamente, antes de presionar el botón correcto.
Cada sesión de entrenamiento duró alrededor de 30 minutos. Las tareas de entrenamiento fueron administradas en el laboratorio de la Universidad, y los estudiantes escucharon los estímulos con auriculares.
Sesiones de instrucción explícita
Las sesiones de instrucción explícita de las cuales participaron los alumnos del Grupo 2 formaban parte de un taller titulado «Fonética del Inglés», ofrecido a todos los participantes de este grupo. El taller consistió en tres encuentros de 100 minutos cada uno, en los cuales se explicitaron y practicaron aspectos referentes a los sistemas consonántico y vocálico del inglés, y fueron ejemplificadas las principales dificultades de los aprendices brasileños en el proceso de adquisición de las vocales y consonantes de la lengua-meta. La enseñanza del fenómeno de aspiración, cuya presencia/ausencia diferencia los segmentos sordos y sonoros iniciales del inglés, tuvo lugar durante 30 minutos de cada uno de los tres encuentros. De esta forma, fue garantizado que el periodo de explicitación del fenómeno investigado en este trabajo fuera equivalente al intervalo de tiempo de entrenamiento al que fue expuesto el Grupo 1 (tres sesiones de 30 minutos cada una).
Las actividades de pronunciación del taller seguían los tres primeros pasos previstos en el modelo propuesto por Celce-Murcia, Briton, Goodwin y Griner (2010) para una enseñanza comunicativa de la pronunciación del inglés como lengua segunda o extranjera: (1) descripción y análisis (en el que se explican los patrones de la L2); (2) discriminación auditiva (ejercicios a través de los cuales los aprendices pueden discriminar de modo no exhaustivo, a partir del estímulo auditivo proporcionado, la sonoridad de las consonantes) y (3) práctica controlada y retroalimentación (etapa caracterizada por la repetición de carácter más mecánico de las formas a través de ejercicios del tipo drills)7. Todos los diez alumnos del Grupo 2 estuvieron presentes en todos los encuentros8.
Instrumentos de recolección de datos utilizados en el pretest y postests
Siguiéndose la misma metodología de recolección y los mismos instrumentos empleados en Alves y Luchini (2017), los participantes de los tres grupos realizaron un pretest (que ocurrió dos días antes del inicio de las sesiones de entrenamiento/instrucción explícita), un postest inmediato (que ocurrió dos días después de la última sesión de entrenamiento) y un postest tardío (que ocurrió exactamente un mes después del último postest). En cada una de estas sesiones, los participantes realizaron una tarea de percepción y una tarea de producción, independientemente del grupo en el que participaron.
La tarea de percepción
La tarea de identificación fue elaborada con el software rp (Rauber et al., 2013). En esta tarea, administrada tanto en el pretest como en los postests, los participantes oyeron palabras monosilábicas en inglés, iniciadas por un segmento oclusivo, y se les pidió que hicieran clic en un botón para indicar el segmento inicial de la palabra (/p/, /b/, /t/, /d/, /k/, /g/). Ninguna especie de retroalimentación se proporcionó a los alumnos después de hacer clic en una de las opciones. Al principio de la prueba, los aprendices fueron expuestos a tres cuestiones de familiarización, para asegurarnos de que los estudiantes entendieran la tarea. En el momento de la etapa de familiarización, los estímulos iniciados por los cuatro patrones de VOT ya mencionados -VOT negativo, VOT positivo, VOT cero natural y VOT cero artificial (Alves & Luchini, 2016, 2017)- fueron presentados a los estudiantes en un ordenamiento aleatorio.
La inclusión de los cuatro patrones de VOT responde a la importancia de establecer un paralelismo con el estudio anterior de Alves y Luchini (2017), así como la necesidad, expresada en estudios previos llevados a cabo por nuestro grupo de investigación (Alves & Motta, 2014; Alves & Zimmer, 2015; Schwartzhaupt, Alves & Fontes, 2015; Alves & Luchini, 2016), de demostrar que el VOT resulta no ser la pista acústica fundamental entre los aprendices brasileños y argentinos. La tarea consistió en 48 estímulos, siendo 12 estímulos de cada uno de los patrones (cuatro estímulos para cada punto de articulación, producidos por diferentes locutores9), como en las palabras [b]it, [d]it y [g]it, para el patrón VOT negativo10, por ejemplo. Las pruebas tuvieron lugar en el laboratorio de informática de la institución en la que fue realizado el experimento.
La tarea de producción
La tarea de producción fue similar a la empleada en Alves y Zimmer (2015) (con estudiantes brasileños de inglés). Este test consistió en leer palabras aisladas presentadas en diapositivas individuales de un archivo .ppt. Las palabras utilizadas fueron peer, pit, pee, team, tick, tip, kit, keel y kill11, es decir, tres diferentes ítems lexicales para cada punto de articulación12. Cada palabra debería ser pronunciada dos veces, lo que sumaría hasta seis tokens por consonante para cada participante. Se solicitó que cada palabra fuese pronunciada dos veces (en orden aleatorio) para garantizar que cualquier problema con el material de audio no resultara en la pérdida de la producción de uno de los elementos léxicos, así también como para permitir que el promedio de producción de VOT de cada participante representara una mayor cantidad de tokens.
Los participantes realizaron el test individualmente, en una sala silenciosa. La producción de los participantes se grabó con un auricular Philips SHM 3550, en una computadora portátil Dell Inspiron. Las producciones fueron grabadas en Audacity 2.0. Los datos fueron analizados acústicamente en el software Praat, versión 5.4.21 (Boersma & Weenink, 2017). Para determinar el intervalo de tiempo referente al VOT, se midió la porción desde el inicio de la explosión hasta el inicio de sonoridad correspondiente a la vocal siguiente (el primer pulso de voz en la forma de onda de la vocal). Los tests estadísticos se llevaron a cabo en SPSS-18.
RESULTADOS Y DISCUSIÓN
Tarea de identificación
Los resultados de la tarea de identificación se presentan en la Tabla 1. En esta tabla, presentamos el porcentaje de respuestas correctas para cada uno de los patrones investigados13, así como los resultados del análisis intragrupo realizado.
Tabla 1 Índices de aciertos (porcentaje de agudeza en la primera línea, media y desviación estándar en la segunda línea) en las tareas de identificación (pretest, postest inmediato y postest tardío) y resultados de los tests de Friedman para los tres grupos14

Nota: *? p < 0.i0 (marginalmente significativo), *p < 0.05, ** p < 0.0i, ***p < 0.001.
Como ya se ha evidenciado en estudios anteriores (Alves & Motta, 2014; Alves & Zimmer, 2015), los datos referentes a los patrones VOT cero natural y VOT cero artificial presentados en la Tabla 1 también corroboran la premisa de que pistas adicionales, además del VOT, ejercen efecto en la identificación de la sonoridad de las oclusivas iniciales. Eso se verifica justamente en el comportamiento distinto presentado para estos dos patrones, dado que el patrón cero natural, desde el pretest, ya tiende a ser identificado como sonoro por los tres grupos, mientras que el patrón artificial tiende a ser identificado como sordo. Es justamente esta discrepancia entre los dos patrones la que sugiere que otras pistas acústicas pueden estar ejerciendo efecto en la identificación de los estudiantes.
Además, a partir de la observación de los datos descritos en la Tabla 1, observamos, desde el pretest, índices de acierto muy altos para los patrones VOT negativo y VOT positivo, independientemente del grupo de los participantes. Estos resultados son también compatibles con el hecho de que en las lenguas en cuestión las oclusivas iniciales /b/, /d/ y /g/ se producen con prevoceo, de modo que no resulte difícil identificar los segmentos con tal patrón de VOT como sonoros. Por su parte, conforme a lo presentado en dichos trabajos, el patrón VOT positivo tiende a ser identificado, casi categóricamente, como sordo por aprendices argentinos y brasileños.
Para la verificación de los efectos del entrenamiento y de la instrucción, se realizaron tests de Friedman15 (análisis intragrupo), con el ánimo de determinar diferencias significativas entre los índices de respuestas correctas referentes al pretest, al postest y al postest tardío, considerando cada uno de los grupos de participantes individualmente16. Como se esperaba, los resultados del test de Friedman no señalaron ninguna diferencia significativa para ninguno de los cuatro patrones verificados, en lo que se refiere a los índices de aciertos presentados por el Grupo 3. Con respecto al Grupo 2, que recibió instrucción explícita, tampoco se encontraron diferencias significativas en los cuatro patrones verificados.
Tales resultados nos llevan a sugerir que, al menos un mes después del periodo de instrucción, tal práctica pedagógica no parece haber tenido efectos en la identificación de los patrones de VOT. Estos resultados son diferentes a los verificados en el Grupo 2 de Alves y Luchini (2017), para el cual se agregaron ambas prácticas de entrenamiento perceptivo e instrucción explícita. En el grupo en cuestión, se observaron diferencias significativas en el patrón VOT cero, y diferencias marginalmente significativas para los patrones de VOT cero artificial y VOT positivo.
Los resultados del estudio nos llevan a sugerir que tales mejoras verificadas anteriormente podrían deberse más al entrenamiento perceptivo que a la toma de conciencia per se, ya que, cuando se aplica la instrucción explícita aisladamente, no parece generar efectos significativos. También queda claro que las aplicaciones individuales de entrenamiento perceptivo o de instrucción explícita ejercen efectos diferentes de la práctica integrada de estas dos técnicas, aplicada en Alves y Luchini (2017).
En lo que se refiere al Grupo 1 (que recibieron entrenamiento perceptivo), verificamos resultados significativos en los patrones VOT negativo, VOT cero y VOT cero artificial. Los resultados referentes al patrón VOT negativo señalados en la Tabla 1 pueden ser considerados inesperados, ya que diferencias significativas en este patrón no habían sido encontradas en Alves y Luchini (2017), dado el alto índice de aciertos verificado ya en el pretest. Sin embargo, dado que después del entrenamiento realizado los participantes alcanzaron 100 % de aciertos en ambos postests, pudimos verificar una diferencia significativa.
Por su parte, de forma similar a lo verificado en el Grupo 1 (solo entrenamiento) de Alves y Luchini (2017), notamos diferencias significativas tanto en el patrón VOT cero como en el patrón VOT cero artificial. Estos resultados corroboran los efectos positivos de la tarea de entrenamiento perceptivo aplicada (sin instrucción): los aprendices pasan a prestar atención a la pista de VOT como aspecto acústico mayoritario en las distinciones de sonoridad de las oclusivas iniciales, lo que resulta en mayores grados de identificación de los patrones VOT cero natural y artificial como sonoros.
En la Tabla 2, presentamos los resultados del test post-hoc de Wilcoxon (con corrección de Bonferroni), que compara el pretest y el postest inmediato, el postest inmediato y el postest tardío, así como el pretest y el postest tardío.
Tabla 2 Resultados de los tests post-hoc de Wilcoxon (con corrección de Bonferroni): tarea de identificación

Nota: --- no se aplica (resultados no-significativos para el test de Friedman), n.s.: no significativo, *p < 0.017, **p < 0.001.
Dado que no encontramos diferencias significativas en los grupos 2 y 3 en los tests de Friedman, nos centramos en el test post-hoc referente al Grupo 1. En lo que se refiere al patrón VOT negativo, a pesar de haber encontrado diferencias significativas en la prueba de Friedman, verificamos que los resultados de los tests post-hoc no señalaron ninguna diferencia entre dos etapas distintas. Tal resultado ya era esperado, dado que los índices de acierto en el pretest para este patrón ya eran muy altos, de forma similar a lo verificado en Alves y Luchini (2017).
En lo que se refiere al patrón VOT cero, encontramos diferencias significativas entre el pretest y el postest 1 y entre el pretest y el postest 2. Este resultado fue el mismo encontrado en los datos de Alves y Luchini (2017) para las respuestas al patrón VOT cero, e indican que el entrenamiento proporcionado contribuyó a diferencias antes y después de tal intervención. El hecho de no haber encontrado diferencias significativas entre los dos postests nos lleva a sugerir que las modificaciones después del entrenamiento presentaron carácter duradero, de modo que tales resultados se hicieron sentir no solo después del entrenamiento, sino un mes después de este periodo.
Finalmente, en lo que se refiere al patrón VOT cero artificial, se verificó una diferencia marginalmente significativa entre el pretest y el postest inmediato, y una diferencia significativa entre el pretest y el postest tardío. Una vez más, esos resultados son similares a los encontrados en el Grupo 1 (solo instrucción) de los aprendices argentinos de Alves y Luchini (2017), en el que se encontró una diferencia significativa solo entre el pretest y el postest tardío. En el estudio anterior y en el presente estudio con aprendices brasileños, verificamos que, en términos descriptivos, los índices de aciertos son aún mayores entre el pretest y el postest tardío, aunque la diferencia entre los dos postests no sea significativa.
Estos resultados referentes a comparaciones intragrupos nos llevan a sugerir que el entrenamiento perceptivo (y no la instrucción explícita) contribuye a mayores índices de aciertos en la identificación de los patrones VOT cero natural o artificial. En otras palabras, el entrenamiento perceptivo contribuyó para que los participantes pasaran a tomar el VOT como pista acústica prioritaria en las distinciones de sonoridad.
A continuación, presentamos los resultados de los tests intergrupo17, para verificar diferencias significativas entre los tres grupos de participantes en cada uno de los tests. En la Tabla 3, presentamos los resultados del test de Kruskal-Wallis.
Tabla 3 Resultados de los tests de Kruskal-Wallis: tarea de identificación
| Pretest x2(gl) | Postest 1 x2(gl) | Postest 2 x2(gl) | |
|---|---|---|---|
| VOT negativo | 0.97(2)?(0.084) | 2.00(2) | 2.00(2) |
| VOT positivo | 0.457(2) | 6.26(2)* | 4.57(2) |
| VOT cero | 3.95(2) | 10.95(2)** | 10.35(2)** |
| Cero artificial | 1.20(2) | 13.04(2)** | 16.69(2)*** |
Nota: ? < 0.10, *< 0.05, **p < 0.01, ***p < 0.001.
Los datos de la Tabla 3 señalan que no hubo diferencia significativa entre los tres grupos en el pretest, lo que indica que los índices de respuestas correctas tendían a ser estadísticamente equivalentes antes de las sesiones de entrenamiento e instrucción18. Como se esperaba, en los postests, encontramos diferencias significativas entre los tres grupos. En el primer postest, verificamos diferencias entre los tres grupos en los patrones VOT positivo, VOT cero natural y VOT cero artificial. En el postest tardío, observamos diferencias significativas entre los grupos tanto en el patrón VOT cero natural como en el VOT cero artificial. Los resultados de los tests post-hoc de Mann-Whitney (con corrección de Bonferroni) se presentan en la Tabla 4 19.
Tabla 4 Resultados de los tests post-hoc de Mann-Whitney (con corrección de Bonferroni): tarea de identificación

Nota. --- no se aplica (los resultados del test de Kruskal-Wallis no fueron significativos), n.s. no significativo, ?p < 0.05, *p < 0.017, **p < 0.0in, ***p <0.001.
De modo similar a lo verificado en Alves y Luchini (2017), no encontramos diferencias significativas entre los dos grupos en los patrones VOT negativo y VOT positivo, en ninguna de las etapas de recolección de datos. Conforme se ha aclarado, ambos patrones ya presentan índices de aciertos bastante altos desde la etapa preinstruccional. Por su parte, en lo que se refiere al patrón VOT VOT cero natural, encontramos, tanto en el postest inmediato como en el tardío, diferencias estadísticamente significativas entre los Grupos 1 y 2 y entre los Grupos 1 y 3.
Estos resultados, asociados a los porcentajes descriptivos presentados en la Tabla 1, reiteran el aumento en los índices de acierto en la identificación de los participantes que recibieron entrenamiento, a diferencia de los participantes que recibieron instrucción y de los participantes del Grupo 3. Tenemos, una vez más, evidencias de la contribución de la aplicación de entrenamiento perceptivo al Grupo 1. Estos datos se muestran diferentes de los verificados en Alves y Luchini (2017), estudio en el que no se encontraron diferencias significativas entre el Grupo 1 (entrenamiento únicamente) y el Grupo 3 (entrenamiento e instrucción), pero se registraron diferencias entre los Grupos 1 y 2 y el Grupo 3. En otras palabras, mientras que la aplicación de entrenamiento e instrucción (Alves & Luchini, 2017) promueve un aumento en los índices de aciertos en la identificación, el suministro de instrucción sin entrenamiento, como muestran los datos del presente estudio, no parece contribuir al logro de mayores índices.
En lo que se refiere al patrón cero artificial, verificamos, en el primer postest, únicamente una diferencia estadísticamente significativa entre el Grupo 1 y el Grupo 3. No verificamos una diferencia entre cada uno de los grupos experimentales, aunque los datos en la Tabla 1 reflejan un aumento de prácticamente el 20 % en los índices de aciertos del Grupo 1. Por su parte, en el postest tardío, verificamos diferencias significativas tanto entre el Grupo 1 y el Grupo 2 como entre el Grupo 1 y el Grupo 3, confirmando de esa forma la importancia de la tarea de entrenamiento perceptivo para la identificación de la sonoridad de las oclusivas iniciales.
En el estudio de Alves y Luchini (2017), los participantes del Grupo 1, que recibieron entrenamiento, también presentaron diferencias significativas únicamente con relación al Grupo 3 (Control) en el postest tardío, al contrario de lo que había sido verificado con el Grupo 2 (entrenamiento + instrucción), que se mostró significativamente diferente del Grupo 3 desde el primer postest. Tales resultados habían llevado a los autores a sugerir que, sin instrucción explícita asociada al entrenamiento perceptivo, los aprendices «pueden llevar más tiempo para descubrir las pistas acústicas en las que deben enfocarse» (Alves & Luchini, 2017, p. 24). En el presente trabajo, reforzamos nuevamente la idea de que los aprendices que reciben solo entrenamiento necesitan un cierto tiempo, incluso después del entrenamiento, para mostrar resultados significativos entre grupos; sin embargo, evidenciamos que no se observan resultados significativos solamente con la aplicación de instrucción explícita, sin entrenamiento.
En resumen, los resultados presentados en las tablas anteriores nos muestran que, a diferencia de la instrucción explícita sin entrenamiento, para fines de mejora en los índices de identificación, el entrenamiento perceptivo sin instrucción parece ejercer efectos significativos. A continuación, presentamos los datos de producción.
Tarea de producción
En la Tabla 5, presentamos los valores medios de VOT de cada uno de los tres grupos, así como los valores de desviación estándar y de mediana. Además, presentamos los resultados de los tests estadísticos intragrupo de Friedman.
Tabla 5 Resultados de los tests de producción (valores promedios en la primera línea, desviación estándar en la segunda y mediana en la tercera línea de cada columna) y resultados de los tests de Friedman
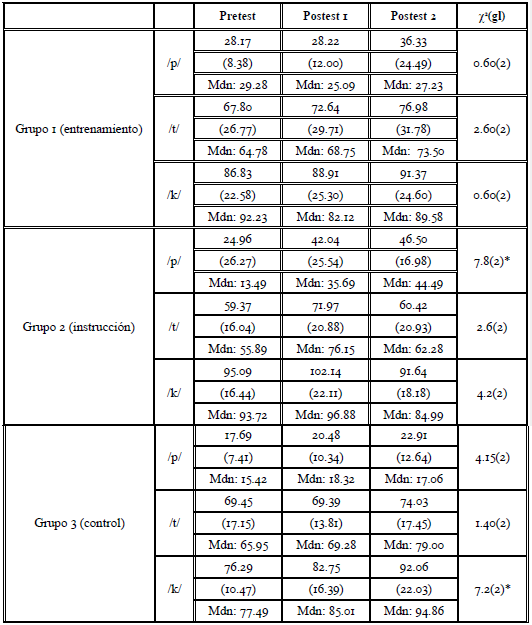
Nota: Mdn: mediana; DPs: presentados entre paréntesis; *?p < 0.10 (marginalmente significativo), *p < 0.05.
Realizamos un análisis intragrupo para verificar si hubo diferencias significativas entre las tres etapas del proyecto, considerando cada grupo por separado. Aunque los datos descriptivos revelan una cierta mejora antes y después de la instrucción en los valores de producción presentados por el Grupo 1, no encontramos diferencias significativas en las producciones de las tres consonantes de este grupo. A su vez, encontramos diferencias significativas (p < 0.001) para /p/ en el Grupo 2. Diferentemente de lo que esperábamos, el Grupo 3 también mostró una diferencia marginalmente significativa para /k/. Como una posible explicación, podemos considerar que, en el pretest, los índices de producción de VOT de /k/ del Grupo Control fueron los más bajos entre los tres grupos20. Los valores de VOT encontrados en los dos postests en el Grupo 3 son similares a los de los demás grupos, como si este estuviera «compensando» un supuesto desarrollo atrasado en la L2.
En suma, los resultados de los tests de Friedman, aunque no del todo conclusivos, parecen sugerir una cierta ventaja para el Grupo 2, aunque diferencias significativas solo se han encontrado para /p/. De hecho, dado que ya en el pretest los estudiantes del Grupo 2 presentaban valores de VOT similares al nativo para /k/, no habría margen para diferencias estadísticamente significativas entre el pretest y los postests. Por su parte, aunque observamos una diferencia grande en los promedios de VOT de /t/ entre el pretest y el postest inmediato, la disminución del promedio en el postest tardío parece no haber permitido la verificación de diferencias significativas. En la Tabla 6, presentamos los resultados del test post-hoc de Wilcoxon (con corrección de Bonferroni).
Tabla 6 Resultados de los Tests Post-hoc de Wilcoxon (con corrección de Bonferroni): test de producción

Nota: - no se aplica (los resultados del test de Friedman no fueron significativos), n.s. no significativo, *p < 0.017, **p < 0.05
Los resultados del test post-hoc de Wilcoxon evidenciaron una diferencia significativa para /k/ entre el pretest y el postest tardío en el Grupo 3. Como señalamos anteriormente, podemos buscar una posible explicación en el hecho de que, en el pretest, en términos descriptivos, la media de VOT de /k/ para el Grupo 3 tendía a ser menor que la de los otros grupos. Por su parte, en lo que se refiere al Grupo 2, también encontramos una diferencia significativa en la producción de /p/ entre el pretest y el postest tardío, lo que parece ser una contribución de la instrucción explícita.
Los resultados referentes a los dos grupos experimentales investigados en este estudio son similares a los previamente encontrados en Alves y Luchini (2017). En el estudio anterior, de modo semejante a lo aquí verificado, los resultados del Grupo 1 tampoco presentaron diferencias significativas entre las etapas del experimento; tal hecho llevó a los autores a sugerir que la tarea de entrenamiento perceptivo sin instrucción explícita no contribuía a generar diferencias significativas en términos de percepción. Por su parte, en lo que se refiere al Grupo 2 de Alves y Luchini (2017), que había recibido entrenamiento asociado a la instrucción explícita, verificamos diferencias significativas no solo para /p/, sino también para /t/, entre el pretest y cada uno de los dos postests. En el presente estudio, en el que solo se aplicó la instrucción explícita, verificamos una diferencia entre el pretest y el postest tardío para la oclusiva bilabial. El hecho de que solo una de las tres consonantes presente diferencias significativas puede ser justificado por los valores de VOT de las oclusivas alveolar y velar, ya que tienen valores cercanos a los de los hablantes nativos.
A continuación, presentamos el análisis intergrupo. La Tabla 7 muestra los resultados de los tests de Kruskal-Wallis, que corresponden a cada una de las tres fases de recolección de datos21. En la Tabla 8, se presentan los resultados del test post-hoc de Mann-Whitney22.
Tabla 7 Resultados de los tests de Kruskal-Wallis: producción
| Pretest x2(gl) | Postest 1 x2(gl) | Postest 2 x2(gl) | |
| /p/ | 6.98(2)* | 6.32(2) * | 8.54(2)* |
| /t/ | 1.52(2) | 0.01(2) | 2.00(2) |
| /k/ | 5.39(2)?(p=0.068) | 0.14(2) | 0.00(2) |
Nota: ?p < 0.10, *p < 0.05.
Tabla 8 Resultados de los tests post-hoc de Mann-Whitney (con corrección de Bonferroni)
| Grupo 1 vs. grupo 2 | Grupo 2 vs. grupo 3 | Grupo 1 vs. grupo 3 | ||
| Pretest | n.s. | n.s. | ** | |
| /p/ | Postest 1 | n.s. | n.s. | n.s. |
| Postest 2 | n.s. | ** | n.s. | |
| Pretest | ||||
| /t/ | Postest 1 | |||
| Postest 2 | ||||
| Pretest | n.s. | ** | n.s. | |
| /k/ | Postest 1 | |||
| Postest 2 |
Nota: - no se aplica (los resultados del test de Friedman no fueron significativos), n.s. no significativos, *p < 0.017, **p < 0.01
En la comparación intergrupos, verificamos, ya en el pretest, una diferencia estadísticamente significativa para /p/ y una diferencia marginalmente significativa para /k/. En lo que se refiere a la oclusiva velar, ya habíamos mencionado la desventaja, en términos descriptivos, de los promedios de VOT de /k/ en el pretest. Esto se muestra claramente en los resultados del test post-hoc de Mann-Whitney, que demuestran una diferencia significativa entre los grupos 2 y 3, antes, incluso, del entrenamiento perceptivo. Los datos de la Tabla 8 también muestran que las diferencias entre los dos grupos no fueron encontradas en las etapas de postest, y esto se debe a que los participantes del Grupo 3 presentaron un aumento en la media de VOT en las últimas dos fases de recolección de datos, de modo que se igualan a las medias de los otros dos grupos. Tampoco esperábamos encontrar una diferencia significativa para /p/ en el pretest, que ocurre por una diferencia entre los Grupos 1 y 3, conforme pudimos ver en la Tabla 8. Cabe mencionar, también, que no encontramos diferencias entre estos dos grupos en los dos postests, una vez que el Grupo 3, que también presentaba la menor media de VOT de /p/ en el pretest, compensó tales valores en las demás etapas de recolección de datos.
Los datos de la Tabla 7 también evidencian diferencias entre los promedios de /p/ en los tres grupos en cada uno de los postests. En la Tabla 8, los resultados del post-hoc de Wilcoxon no muestran diferencias significativas en el primer postest, pero señalan una diferencia entre los grupos 2 y 3 en el postest tardío. También habíamos encontrado diferencias referentes a la producción de /p/ en Alves y Luchini (2017), pero en el Grupo 2 (entrenamiento con instrucción) sobre el Grupo 1 (entrenamiento únicamente). En ambos estudios, verificamos una cierta ventaja de los grupos que recibieron instrucción, que se refleja en la producción de /p/, la consonante cuyos valores de VOT tienden a ser los más bajos antes de cualquier forma de intervención pedagógica.
En resumen, aunque los datos de la tarea de producción no parecen evidenciar efectos fácilmente concluyentes, la observación de los datos señala una ventaja del grupo que recibió solamente instrucción en la producción de los valores de VOT, sobre todo de la oclusiva /p/. Resultados similares ya habían sido sugeridos en Alves y Luchini (2017), que marcaban una ventaja por parte del grupo que recibía instrucción con entrenamiento. En la siguiente sección, discutimos los distintos efectos de las dos técnicas.
CONSIDERACIONES FINALES
Los resultados del presente estudio parecen sugerir efectos diferenciados para cada una de las técnicas de entrenamiento perceptivo e instrucción explícita investigadas. En lo que se refiere a la percepción de los patrones de VOT, solo el Grupo 1, que recibió entrenamiento, presentó diferencias significativas entre el pretest y los postests. En cuanto a la producción, aunque los patrones encontrados no fueron tan claros como aquellos verificados en la percepción, observamos una ventaja del Grupo 2 (que recibió instrucción).
En lo que se refiere al Grupo 1, esperábamos encontrar ventajas en la prueba de identificación, como lo habíamos observado en Alves y Luchini (2017). Asimismo, el efecto insignificante del entrenamiento sin instrucción sobre la producción también había sido verificado en el estudio anterior. Ante estos datos, cabe indagarnos por qué este grupo no presentó valores altos también en la producción, siempre teniendo en cuenta la hipótesis de que índices mejores de percepción conllevan una mejora en el desarrollo de la producción. Debemos tener en cuenta el pequeño intervalo de tiempo, de apenas un mes, entre el final del entrenamiento perceptivo y el segundo postest. Este pequeño intervalo, replicado en cuanto a su duración con respecto al realizado en el estudio anterior de Alves y Luchini (2017), se debió a las limitaciones encontradas en los contextos de enseñanza y de aprendizaje en los que se llevó a cabo la investigación. Por tanto, debemos considerar que el entrenamiento también pueda contribuir a una mejora en la producción en un plazo aún mayor. Para ello, es necesario realizar futuros estudios en los que el último postest sea aún más tardío.
Respecto al Grupo 2, los datos del presente estudio corroboran que, a diferencia del entrenamiento perceptivo, efectos más inmediatos en la producción pueden ser verificados a través de la instrucción explícita23. De hecho, tanto en el presente estudio como en el trabajo anterior, los participantes del Grupo 1 no presentaron ventajas en la producción, y los participantes del Grupo 2 -con instrucción y entrenamiento, en Alves y Luchini (2017), y solo con instrucción, en el presente trabajo- demostraron alguna ventaja sobre todo en los índices de producción de /p/24. Los hallazgos de la presente investigación, al evidenciar ventajas del Grupo 2 solo en la producción, desafían el orden del desarrollo canónico percepción-producción. Tales resultados pueden llevarnos a sugerir que tal aumento en los índices de producción pueden ser el resultado de un monitoreo consciente por parte de los estudiantes, lo que no sería verificado en ambientes menos monitoreados de uso lingüístico.
A raíz de esto, sugerimos la realización de nuevas investigaciones en el área que verifiquen los efectos de la instrucción también en producciones de habla espontánea. Además, otra cuestión que también merece consideración se refiere a la posibilidad de que la práctica frecuente de las formas-meta, aunque en un contexto monitoreado, lleve a los alumnos a automatizar tales formas (DeKeyser, 2015). Tal posibilidad solo podrá ser vista, nuevamente, con estudios cuyos postests sean más tardíos, y que verifiquen tanto la producción de habla monitoreada como espontánea.
Un aspecto que aún debe considerarse tiene que ver con la posibilidad de que el Grupo 2 haya presentado tasas de producción ligeramente mejores, no en función del conocimiento metalingüístico que recibió a través de la instrucción, sino por la práctica de producción controlada (drills) proporcionada juntamente con la instrucción. En una situación hipotética, es decir, en caso de que esta posibilidad hubiera sido cierta, y en función de estas actividades de producción, independientemente de haber recibido instrucción explícita sobre el fenómeno de aspiración, estos estudiantes habrían presentado mejoras en su performance oral.
Aunque la metodología utilizada en este estudio25 no nos permite descartar tal posibilidad por completo, evidencias presentadas en estudios anteriores (Alves & Luchini, 2017; Gordon & Darcy, 2016) nos permiten disminuir el grado de probabilidad de tal posibilidad. Primero, en Alves y Luchini (2017), se verificó que el Grupo 2, que recibió instrucción (combinada con entrenamiento perceptivo) sin la oportunidad de realizar actividades de práctica de producción, presentó resultados similares a los obtenidos en este estudio, donde también se demostró que hubo una mejora en la producción de /p/. Sin embargo, en este estudio se notó una diferencia con los participantes del estudio anterior, en el que habían hecho parte de sesiones de entrenamiento perceptivo, y también mostraron mejoras en su percepción.
En segundo lugar, los resultados del estudio de Gordon y Darcy (2016) conducen a la sugerencia de que es la combinación de instrucción explícita con práctica de producción de las estructuras-meta, en vez de la práctica de producción sin instrucción, lo que promueve mejoras en las tasas de comprensibilidad del habla. Los autores investigaron dos grupos experimentales (un grupo que recibió instrucción y práctica fonética con respecto a los aspectos segmentales, y otro que recibió instrucción y practicó oralmente aspectos suprasegmentales) y un grupo control. Aunque hayan tenido oportunidades de producción oral de las formas-meta, los participantes del grupo control no recibieron instrucción explícita sobre los aspectos fonético-fonológicos. Los resultados mostraron que hubo una superioridad en la comprensibilidad del habla de los dos grupos experimentales en comparación con el grupo control. Estos datos sugieren, una vez más, que es la instrucción asociada con la práctica de la pronunciación, en lugar de la práctica de la pronunciación sin instrucción, lo que es capaz de permitir mejoras en los postests.
A pesar de que estos estudios, con metodologías y objetivos diferentes a los nuestros, pueden sugerir que las mejoras en nuestros resultados no se deben solo a la oportunidad de práctica oral, sino a la combinación de dicha práctica con la instrucción explícita brindada, reconocemos que son necesarias nuevas investigaciones similares a la de Gordon y Darcy (2016), que contrasten un grupo con actividades de práctica oral en oposición a otro expuesto a una combinación de práctica oral e instrucción. Esta comparación nos permitirá profundizar las discusiones sobre el desarrollo del vot y las posibilidades planteadas al comienzo de esta sección.
Finalmente, a pesar de haber tenido en cuenta los procesos metodológicos adoptados en Alves y Luchini (2017), en este estudio experimentamos algunas de las mismas limitaciones que tuvimos en el trabajo anterior: bajo número de participantes, corto periodo destinado entre los dos postests y escasa cantidad de horas dedicadas al entrenamiento e instrucción.
No obstante, creemos que los resultados aquí señalados, al presentar distintos efectos para las prácticas de entrenamiento perceptivo e instrucción explícita, sugieren un abordaje integrado de las dos técnicas (como en Alves & Luchini, 2017) para efectos inmediatos en ambas esferas de percepción y producción. En este sentido, estos resultados estarían abriendo las discusiones para una serie de nuevos trabajos experimentales. Nuevas investigaciones, con distintas metodologías de recolección de datos (controlada o espontánea) y de instrucción implícita o explícita (más o menos mecánica o contextualizada), pueden revelar efectos adicionales de tales intervenciones pedagógicas. De esta forma, el presente trabajo representa una invitación para que nuevos estudios verifiquen los efectos de diferentes metodologías para la enseñanza de la pronunciación en L2.

