











 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
Introduction
Nowadays, educational tools based on artificial intelligence (AI) can collect a great number of data points without the need for human intervention. These data points include a compilation of test results, performance indicators, teachers' opinions, comments, and even students' behaviors and learning. The identification of patterns in data can be a complicated task, as behavior is frequently associated to performance and is estimated by how capable the student is or will be to achieve a specific task, reach a specific learning goal, or respond adequately to a particular learning situation (Pena-Ayala, 2014). In this article, a student's ability (described as p-know) is defined as the number of correct actions that are carried out within the educational tool. Correct actions are associated with the probability that a student knows the involved ability in a determined action, which is obtained using the Bayesian knowledge tracing algorithm (Corbett, 1997).
The variety of technological tools applied to learning is wide, and they comprise the understanding of the content they convey and the objectives students achieve. There are research studies that analyze student behavior in different types of activities in educational environments, with the purpose of detecting specific interaction patterns (Juhahak et al., 2019). The diversity of uses for technological tools in learning suggests that there is value in analyzing registers of user interactions (Apaolaza and Vigo, 2019). The ASSISTment on-line intelligent tutor provides a tool that facilitates the development of tutors based on rules called CTAT (Cognitive Tutor Authoring Tools). CTAT initially asks authors for behavior examples to solve problems, which are used by the tutor to help students learn a determined domain. Taking ASSISTment (Pardos and Heffernan, 2001) as a basis, our study aims to develop a model that could predict if a student's achievement is associated to help-seeking behavior.
In the field, there is evidence that students who request help from the system are not always the ones that have correct actions associated to their learning (Tabandeh and Sami, 2010). However, it has been observed that the use of help can be harmful for learning. Help-seeking in tutoring systems has been associated with students whose main objective is to finish the activity at hand and not to acquire knowledge. This phenomenon has been called 'gaming the system' (Baker et al., 2004). This behavior leads to looking for correct answers and to continue making progress in the system rather than learning from the experience. One of the most important findings in this research is that students who frequently game the system have significantly lower scores than the students who never do.
Most educational tools generate interaction files (log files) which store data points that could lead to the analysis of behaviors when solving specific activities. Analyzing this information is important since data mining could lead to new findings in educational research. The aim of educational data mining is to identify patterns in the data, including frequent elements, frequent subsequences, and frequent substructures (Baker and Inventado, 2014). There are several data mining techniques for the identification of patterns in data that come from educational settings, which generate associative, predictive, and even behavioral models (Falakmasir and Habibi, 2010; Jovanovic et al., 2012). These models have allowed education institutions to make decisions towards improving the student's educational experiences and their learning. The objectives of this research are: 1) to typify student behaviors when interacting with intelligent tutors for mathematics and 2) to associate the identified typologies with help-seeking and achievement. The overall aim is to present an outlook of user behaviors, so that further personalization through scaffolding can be defined in newer versions of the system. The hypotheses that guide this research are:
H1: There are typologies for help-seeking students with the intelligent tutor.
H2: Students with different typologies have significant differences regarding the actions they perform with help, success, failure, and by gaming the system.
Related works
The literature review is dedicated to the processing of data generated by the interaction between students and an Intelligent Tutor System (ITS), which reflects the decisions made by the students when solving the problems presented in the system. In this context, the research presented by D'Aniello et al. (2016) focuses on awareness learning, allowing students to understand the concepts they acquire during their daily activities. The authors propose an approach to situational awareness based on Endsley's model, which employs conceptualization of the learning environment through concept maps.
Afterwards, Lara-Muñoz et al. (2019) found that students who work collaboratively when using an ITS can gain learning from their social environment. This means that students learn from the interaction with fellow learners when performing a collaborative activity. Additionally, the results show that students with the same learning style have significant learning gains once they have found the most suitable groups in a collaborative activity, in contrast to those who worked with partners with different learning styles.
In the same way, but with a focus on individual student performance, Rebolledo-Méndez et al. (2021) analyzed students' meta-affective capacity in learning and how it influences the knowledge acquisition process. This research presents typologies that study the relationship between meta-affect, students' knowledge, and their affective transitions during the use of an intelligent tutor system for mathematics. The results demonstrate that having a meta-affective ability is positively associated with students' learning during ITS use.
Moreover, Padayachee (2002) identified that ITSs have several generic characteristics and behaviors related to specific architectural components that can affect the learning process: 1) domain model, 2) tutor model, 3) learner model, and 4) user interface. In this sense, Chang et al. (2020) presented a semantic web-based approach for obtaining pedagogical rules for the tutor module component, which can be integrated with other models in an ITS. The authors build ontology-based tutor models that will allow future ITSs to implement strategies for generating and managing predetermined rules and actions.
Additionally, help-seeking is studied, which is an important process in an ITS, as it is a recurring activity of students when they use technological tools, and it has been proven that appropriate help-seeking behavior can positively influence student learning gain (Tai et al., 2016).
Help-seeking influences students' learning when interacting with ITS because intelligent tutor systems often provide answers to students' requests. The interaction between metacognitive skills and cognitive factors is important for help-seeking, according to the work by Aleven et al. (2003). The authors conclude that help-seeking skills are fundamental for learners, enabling them to face new learning objectives. In addition, some researchers have suggested that meta-cognitive feedback on help-seeking behavior is related to acquiring better learning skills (Roll et al., 2011).
In another line of research, Vaessen et al. (2013) presented a list of help-seeking strategies that students used in an ITS, as well as the relationship between the use of these strategies and performance goals. Based on his results, Aleven (2013) argued that feedback on help-seeking helped students to use help more deliberately, even after feedback was no longer provided, considering that the goal of helping students is one of the big challenges in ITS research. Besides, it is important to address social motivational and meta-cognitive aspects, as they may influence help-seeking (Aleven et al., 2016).
It is important to note that help-seeking in ITS is not a new issue, but, so far, these approaches have not presented evidence of data processing from the log files (student performance) resulting from the interaction between students and the ITS. In this research, the log files were used to typify students' help-seeking behavior.
Method
Participants
The participants in this study were secondary school students from Escuela Federal No. 2 Julio Zárate, in the city of Xalapa, Veracruz, México. The evaluation was carried out during the 2016-2017 school year with selected students from the morning shift population (N = 132). The selection of students followed a random sampling that considered a 95% trust level and an acceptable maximum error of 6,5%, providing a final sample size (n=50). The school administration office gave its approval to carry out this study, and neither personal nor sensitive data were collected from the students.
Materials
The materials used in the experimental design included ITSs as a technological tool and the TraMineR package (Gabadinho et al., 2011) in the R programming language. The Scooter intelligent tutoring system is an interactive software developed by Baker et al. (2004), which combines teaching given by a teacher with problems that each student has to solve. These problems are presented as different practice exercises in the learning of types of variables (categorical and numerical) and their graphic representation. Scooter has two working modalities: 1) reactive, in which the tutor reacts to gaming the system instances; and 2) non-reactive, where the tutor is not shown to the student, so that it does not interfere in the learning process. Scooter clearly specifies the objectives that each student must reach, knows the students' needs, and can correct the student immediately when they make a mistake. The TraMineR R packages are used to extract, describe, and visualize states or event sequences. This package allows managing longitudinal data, tracing sequences, removing subsequences of frequent events, and associating found subsequences by means of rules (Gabadinho et al., 2011)
Phases
The experimental design phases included activities such as collecting the information based on the students' interaction logs with Scooter when doing an exercise. This included dispersion, selection, cleaning, information transformation, and, finally, data mining algorithms for the typification of students:
1. Phase 1- Interaction: During this stage, the students interacted with Scooter in a research scenario, where the participants worked with the tutor for 20 minutes. Each student was assigned a computer so that they could work at their own pace. This took place in the school's media room, and the exercises were of the following type:
"Samanta is trying to find out what brand of dog food her pet likes best. Each day, she feeds it a different brand and checks how many bowls it eats, but then her mother says that maybe her dog only eats more on the days it does more exercise. Please, draw a dispersion diagram to show how many bowls the dog eats depending on the level of exercise it does that day".
2. Phase 2 - Cleaning and integration: In this stage, the interaction logs are analyzed, the data is cleaned, and it is integrated in a csv file. The interaction logs show the actions students do with Scooter, for example, if they answer a question correctly (or not), if they ask for help, the time they take to do a scenario, among others. The number of requests per student varies depending on the number of times he or she interacts with the tutor when solving an exercise. These data are stored based on a time sequence. The interaction logs contain too much information related to student performance in the ITS.
3. Phase 3 - Selection and transformation: The objective of this research is to use the students' interaction logs in a non-reactive way, specifically when they solve graphic representation exercises (SPLOT). In this type of exercises, Scooter asks the students to identify the dependent and independent variables in a Cartesian plane, as well as the relations between them. It is important to mention that the main variable of the research is the learning probability (p-know). Additionally, in this stage, the data has to be transformed into categorical variables in order to typify the students based on the cases.
4. Phase 4 - Data mining: Once the data are collected, cleaned, transformed, and integrated in a csv file, the patterns of interest to the research are extracted by means of the implementation of data mining algorithms. This stage consists of two activities: 1) grouping each of the instances by assigning them a label (category), and 2) identifying the typologies associated with each type of student.
Results
Based on the interactions between the students and Scooter, 50 interaction logs were obtained. In each file, approximately 31 characteristics were identified per interaction with the intelligent tutor. The main characteristic identified was the p-know value, which expresses a student's probability to learn when doing an activity. p-know is assigned within an interval of [-1, 1] where the value of -1 means that a student performed an incorrect action (WRONG), 0 means that the student did not learn from his/her last interaction, and, finally, 1 means that the student performed a correct action (RIGHT). This research uses the p-know value, the main input variable, as a means to apply the data mining technique. The interaction sequences were defined as follows:
Each register in the knowledge base consists of 20 attributes that correspond to one minute of interaction, thus resulting in 20 minutes for each sequence.
The defined group of labels in each sequence is: positive, negative, and neutral.
The p-know value was registered in one-minute periods, defining the state as positive (if the majority of p-know is positive), negative (if the majority of p-know is negative), or neutral (in case they have the same number of frequencies per tendency).
To typify the interaction behavior sequences, a clustering exercise using the Ward method was followed. As a result of the grouping implementation, four typologies were identified. These typologies are related to the p-know value of the actions the students made when interacting with Scooter. Once the most representative groups were identified, the sequence analysis technique provided by TraMineR was used to typify the students' interaction behaviors. Figure 1 shows the sequences associated to the student behavior clusters (typologies) according to p-know when interacting with the intelligent tutor.
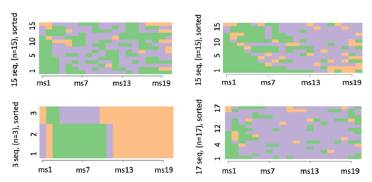
Table 1 shows the breakdown of the proportions of associated actions per typology. Each one receives a name according to the students' predominant actions. To define the identified clusters or typologies, the following variables related to interaction were used: help-seeking, success, failure, and the system abuse shown during the interaction. Figure 2 shows the most representative sequences per each one of the typologies, which are categorized as good performance, average performance, hardworking, and poor performance.
Table 1 Action proportions per typology

Note: The highest values are marked in bold and the lowest are marked in italics
Source: Authors

Source: Authors
Figure 2 All behavior sequences typologies: a) good, b) average, c) hardworking and d) poor
1. Type 1 (Good performance): students in this typology have a good performance regarding correct and incorrect actions, as well as help-seeking (30% Cluster size; n1=15).
2. Type 2 (Average performance): in this group, students can be labeled as regular, since they represent a total of correct actions (20,6) that is below the total mean (23,89) (30% Cluster size; n2 = 15).
3. Type 3 (Hardworking): students who have an excellent performance during their interaction with the tutor and thus make the least number of mistakes. They also report the maximum amount of correct actions without system abuse (6% Cluster size; n3=3).
4. Type 4 (Poor performance): students who abuse the system during most of their interaction time. In addition, they are the group of students who make more mistakes in the average number of correct actions (34% Cluster size; n4=17).
Once the typologies were identified, independent sample comparisons were made to study H2. In Table 2, descriptive statistics of each of the typologies regarding the actions: RIGT, HELP, GAMING, and WRONG can be observed.

Kruskal-Wallis tests were conducted to check the differences in the variables of interest. The results show significant differences for the four typologies in help-seeking, gaming, and wrong answers (p<0,05). A new Kruskal-Wallis test was carried out excluding type 3 students, and the results showed a significant difference only in help-seeking (p<0,05).
Conclusions
The results suggest that student behaviors can be typified according to p-know value. Four groups were identified and labeled as good, average, hardworking, and poor. According to the proportions shown in Table 2, we accept H1, as it can be inferred that, according to the students' help-seeking typologies, they request less help from the tutor, and, as a consequence, they tend to have better performance. In Table 1, it can be observed that there is no significant difference in the comparison of typologies regarding the errors (p=0,1564), correct actions (p=0,3264), and system abuse (p=0,2407). On the other hand, a significant difference was identified in the help-seeking typologies (p=0,0175). Moreover, our results suggest that there are behaviors such as those described in the literature (Hershkovitz and Nachmias 2010). For example, Jovanovic et al. (2012) specify that student behaviors allow teachers to identify hardworking students based on their performance regarding a specific subject. Additionally, Taub et al. (2019) present the impact of performing activities in e-learning environments on the students' learning development. In this sense Romero et al. (2013) discuss how web mining can be applied in learning environments to predict the grades that students will obtain in a final exam.
Our results relate to the work by Romero et al. (2013) because they focus on analyzing the behavior of students in an educational environment with the objective of associating it with their learning within the classroom. During our research, association tests were carried out. We observed that there was a significant association between typologies related to help-seeking (p=0,03277), which confirms that help-seeking typologies with ITS not only exist but explain part of the learning accrued with this type of systems. Additionally, it was observed that "Wrong" has a high association with system abuse (p<0,01), which is why it is important that these values are associated with type 4 students, who show more system abuse, thus leading them to seek more help and thus make more mistakes than the rest.
Additionally, students with poor performance tend to behave in a particularly unproductive manner: they start by doing positive and neutral actions, but, after a short time, they revert to only having negative learning probabilities (p-know) even if they perform correct actions. The findings in the literature (Duffy and Azevedo, 2015; Radford et al., 2015; Angeli and Valanides, 2019) suggest that students benefit from scaffolding techniques; a positive effect has been detected in the interaction of students in learning environments in this regard. These results are important because they show the strategies students use to deal with the complexity of a specific task. In this context, in our research, the typologies associated to the students' behaviors during their interaction with the tutor can be observed (Figure 2). These typologies define our contribution to literature since:
They represent a case study in which behavior typologies based on students' actions and the learning probability (p-know) are identified.
These typologies help define personalized help-seeking strategies. In other words, system abuse is not necessarily negative for learning, since there is a group of students that benefit from it (type 4). This new educational scaffolding will allow acknowledging the probability that a new student belongs to any of the typologies, and so, in this way, the interaction with intelligent tutors will be even more personalized.
Future research should involve analyzing these typologies in an experimental situation, aiming to identify students' learning and verify the hypothesis that there is a direct relation between these typologies and student performance with an intelligent tutor.

