











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
1, INTRODUCCIÓN
La reducción en los combustibles fósiles, así como las emisiones contaminantes relacionadas con su uso, han generado una aceleración en la implementación de combustibles alternativos que permitan contribuir a la disminución de estas problemáticas. En ese sentido, el análisis y adecuadas predicciones de parámetros fundamentales como el tiempo de retraso a la ignición (τ) son esenciales para promover la aplicación de los combustibles renovables, en particular aquellos con alto contenido de hidrogeno (H2). Debido a esto, las herramientas computacionales que permiten calcular dicha propiedad han tomado un papel esencial en las investigaciones asociadas, tanto a nivel fenomenológico como en aquellas enfocadas en el desarrollo de tecnologías que permitan obtener de forma simultánea una alta eficiencia y bajas emisiones.
De forma general, la predicción de τ para una mezcla combustible se lleva a cabo mediante la modelación de un reactor perfectamente mezclado, adiabático y de volumen constante, omitiendo así los efectos de transporte y considerando únicamente el tiempo como variable independiente (reactor cero dimensional) [1]. Diferentes códigos han sido desarrollados para el cálculo de este parámetro y han sido implementados en diversos programas tanto de uso comercial como libre (Cantera, CHEMKIN, FlameMaster, OpenSMOKE++, entre otros [2]). En particular en cada una de estas categorías CHEMKIN y Cantera respectivamente, pueden considerarse como los programas más representativos y de mayor aplicación por los investigadores en el área de combustión, dado el alto número de trabajos publicados donde son utilizadas estas aplicaciones [3]-[7]. Para el caso particular de τ, CHEMKIN utiliza una subrutina escrita en Fortran denominada Aurora, mientras que Cantera utiliza un código elaborado en C++ acoplado con funciones de Python o Matlab para completar los cálculos, así como establecer una interfaz.
Si bien ambos códigos han sido ampliamente validados de forma independiente mediante comparaciones con datos experimentales, el interés por establecer cuál de estos dos puede ser el más adecuado para implementar en un determinado estudio y si existen diferencias entre sus resultados continúa siendo un campo de interés para la ingeniería de combustión. Diversos estudios se han llevado a cabo en este sentido, comprando tanto la predicción de un parámetro específico, como los perfiles de temperatura y especies, hasta los tiempos de cálculo. Perini [8] y colaboradores llevaron a cabo una comparación entre Cantera, CHEMKIN II, CHEMKIN -Pro y un código desarrollado por ellos mismos, en términos del tiempo computacional requerido para obtener la solución usando mecanismo de reacción con diferentes números de especies (desde 29 hasta 2878). Los resultados exponen un tiempo de cálculo menor por parte de Cantera cuando el número de especies es de 29, pero es ampliamente superado por CHEMKIN - Pro cuando la cantidad de especies es más alta (160 y 2878). La diferencia es atribuida al método numérico utilizado para solucionar las ecuaciones diferenciales del modelo. Sin embargo, no presentan comparaciones específicas referente a los valores obtenidos para las variables de estudio. [9] llevó a cabo una comparación cualitativa y cuantitativa entre CHEMKIN y Cantera cuando se incluyen reacciones de superficie. En el primer caso, usó la comparación de perfiles de diferentes especies químicas como CH4, CO, CO2, H2 y H2O a lo largo de una coordenada unidimensional, evidenciando como estos se superponen y por tanto entregan resultados iguales de acuerdo con la autora. En una comparación más directa, se calculó la diferencia absoluta en las fracciones de las mencionadas especies a la salida del reactor. Los valores obtenidos fueron desde uno hasta tres órdenes de magnitud menores en comparación a los resultados de las fracciones. [10] llevo a cabo una comparación en cuanto a características de uso entre ambos programas resaltando sus ventajas y desventajas. Expuso como la interfaz amigable de CHEMKIN y la capacidad para escribir nuevos modelos de Cantera son las características de mayor diferencia entre ambos programas. No obstante, ninguna comparación entre resultados es llevada a cabo y, por el contrario, toma como referencia lo expuesto por [9]. Con el objetivo de validar la idoneidad del uso de Cantera para en la estimación de la velocidad de deflagración turbulenta, [11] realizaron la comparación entre ambos programas usando resultados de la velocidad de deflagración laminar (SL) para una mezcla de H2 y aire en condiciones pobres y ricas (relación de equivalencia (φ) desde 0.5 a 2.5), bajo condiciones atmosféricas. Los resultados obtenidos, muestran una similitud bastante alta desde un punto de vista cualitativo, aunque en las mezclas más ricas (φ>2.0) se evidencia que las discrepancias se incrementan. Sin embargo, no reportan una comparación cuantitativa de los resultados. El mismo autor en un trabajo posterior, llevó a cabo la comparación de SL obtenida por ambos programas, en este caso para una mezcla de CH4 y aire. De manera adicional estos autores evaluaron 2 mecanismos de reacción diferentes. En forma análoga en el primer trabajo encontró una similitud muy alta al momento de realizar la comparación visual de los resultados con ambos mecanismos, lo que sugiere que la cercanía en los resultados es indiferente de cinética química utilizada [12]. [2] llevaron a cabo la comparación entre Cantera, CHEMKIN-II, CHEMKIN -PRO, FlameMaster, and OpenSMOKE++, todos programas enfocados en cinética química. La comparación se hizo modelando un reactor típico para el cálculo de τ junto con la estimación de SL, para una mezcla de CH4 y aire. En el caso del reactor de volumen constante la evaluación se hizo a 30 bar, 3 condiciones de mezcla (φ = 0.7, 1.0 y 1.3) y en un rango de 660 a 1430 K. Aunque no se reporta de forma explícita, los autores afirman que, al comparar los perfiles de temperatura y algunas especies químicas, no existe diferencia apreciable por lo cual se puede garantizar que no hay desviaciones entre los resultados. En el caso de SL, los cálculos se desarrollaron a una presión de 1 bar, temperatura de 300 K y un rango desde 0.6 hasta 1.7 para φ. En general todos los resultados reportados son muy similares con una desviación menor a 0.2 cm/s. Para algunas condiciones de mezcla rica, Cantera predice valores inferiores en 0.45 cm/s respecto a los obtenidos con los demás programas, aunque esto es atribuido en que la difusión térmica no fue tenida en cuenta dado que se aplicó un enfoque de mezcla promedio para el cálculo de las propiedades de transporte, en el cual el programa no admite su determinación. No obstante, la mayor desviación se obtiene por parte de CHEMKIN-II en condiciones estequiométricas llegando a 1.6 cm/s. Adicional a estas comparaciones, los autores realizaron una evaluación del rendimiento en términos computacionales, donde concluyen que no existen diferencias considerables entre estos programas. Comparaciones de los perfiles de temperatura y presión obtenidos durante los cálculos para las predicciones de τ usando n-dodecano en condiciones relevantes de motores de encendido por compresión, no evidenciaron diferencias al utilizar Cantera o CHEMKIN [13]. Sin embargo, aunque el estudio aborda diferentes valores de presión, temperatura y relación de equivalencia, el contraste entre los resultados obtenidos con ambos códigos se muestra solo para una condición puntual y no se aborda el efecto de las variaciones de las condiciones termodinámicas y el mecanismo de reacción. [14] llevaron a cabo cálculos de SL usando ambos códigos y validaron los resultados con valores experimentales. Aunque en dicho estudio se seleccionó CHEMKIN a partir de la comparación realizada como el código para llevar a cabo los cálculos adicionales de la investigación, la comparación con Cantera fue hecha usando mecanismos de reacción diferentes, lo cual claramente puede afectar los resultados finales y ser el factor de generación para las desviaciones obtenidas con el código abierto. Nuevamente en la estimación de SL se compararon los resultados obtenidos usando Cantera con los generados a partir de CHEMKIN, reportando diferencias máximas de 2 %, en este caso, aunque se usó Cantera debido a que reporta un comportamiento más robusto en valores muy bajos de SL, el análisis de sensibilidad desarrollado por los autores se hizo utilizando [15].
Si bien es evidente que se han realizado comparaciones de diferentes tipos entre CHEMKIN y Cantera, tal como se expuso en los párrafos previos, en muchos casos estas no van más allá de una inspección visual o cálculos donde el bajo orden de magnitud de la variable analizada puede generar una percepción equivocada del resultado, como ocurre cuando se comparan fracciones de especies químicas, las cuales en general son muy pequeñas. Lo anterior en particular puede incidir aún más para especies intermedias como algunos radicales que son de interés en el campo de la combustión (OH, H2O2, HO2, CH entre otros), cuyas concentraciones son muy bajas. Por otra parte, la mayoría de las comparaciones se realizan utilizando SL como variable de análisis, si bien este es uno de los parámetros fundamentales más importantes en el área de combustión, deja de lado procesos cinéticos que en su naturaleza son muy diferentes como es el caso de la autoignición.
De esta forma, el objetivo del presente trabajo fue establecer la existencia o no de diferencias entre los resultados obtenidos por los programas CHEMKIN 19.0 y Cantera sobre τ, tomando el primero como referencia. Esto debido a que su código original fue desarrollado primero que el de Cantera, además de su condición comercial donde se espera una mayor cantidad de pruebas de validación previas a su comercialización. La investigación desarrollada pretendió contribuir en la validación y extensión de los códigos abiertos para los procesos cinético químicos asociados con el fenómeno de autoignición. Para esto, se estableció la comparación bajo un criterio estadístico, el cual permite superar las limitaciones de los enfoques hasta ahora utilizados. Se plantea utilizar un análisis de varianza (ANOVA) aplicado a un diseño de experimentos computacionales, donde se llevó a cabo la simulación de un reactor perfectamente mezclado, adiabático y cerrado para el cálculo de τ, evaluando como factores de variación la temperatura, el mecanismo de reacción, la composición del combustible, la relación de equivalencia, la presión y las condiciones de operación del reactor. Finalmente se llevó a cabo una comparación cualitativa del comportamiento de ambos códigos en diversos aspectos de relevancia durante la realización de simulaciones para la estimación de τ. En todos los cálculos se consideró una mezcla de CH4 y H2 como componentes del combustible, mientras para el oxidante se utilizó aire seco.
2. METODOLOGÍA
Teniendo en cuenta que el objetivo del presente estudio fue evaluar la existencia de posibles diferencias entre los resultados obtenidos en Cantera respecto a los entregados por CHEMKIN 19.0 (referentes a la predicción de τ), es necesario establecer la forma de cálculo en ambos códigos. Por otra parte, dado que el alcance del presente estudio estuvo enfocado en establecer las desviaciones de los resultados, teniendo como premisa la capacidad de reproducción y no con el rendimiento del código, en cada uno de los programas se aplicaron las recomendaciones establecidas para un cálculo adecuado de τ, aún cuando estas por la misma estructura de los programas no pueda ser aplicada de forma idéntica en ambos, como es el caso de la subrutina para la solución de las ecuaciones diferenciales asociadas al problema.
Las condiciones iniciales y el tipo reactor (adiabático, cerrado y cero dimensional) a modelar son las mismas en ambos casos. Se despreció además cualquier tipo de reacción de superficie. Estas aproximaciones son acordes con el funcionamiento de los diferentes dispositivos experimentales donde se mide τ [16]-[19]. El tiempo máximo de simulación (tmax), el cual se estableció en 15 segundos, fue igualmente fijado en ambos códigos. Este valor se utilizó únicamente como un umbral general, es decir, si una determinada mezcla pasado este tiempo no presenta condición de ignición, es descartada.
Sin embargo, en el caso de CHEMKIN 19.0, no todas las corridas fueron realizadas de manera simultánea con este valor de tiempo final debido al cálculo excesivo generado; en la siguiente subsección se detalla de una mejor manera este comportamiento. Los valores particulares de presión, temperatura y composición se describen de forma expresa en la sección 3.1 donde se listan los factores de estudio.
Otra de las variables en común y también un factor de estudio es el mecanismo de reacción para modelación de la cinética química del problema. Tomando en cuenta que el combustible base para este estudio es CH4, se seleccionaron dos mecanismos de reacción detallados. El mecanismo 56.54 desarrollado por [20], compuesto por 112 especies y 710 reacciones, el cual fue utilizado por [21] para el cálculo de τ en condiciones de temperaturas medias y bajas usando CH4 como combustible, presentando un buen comportamiento en dicha región, por lo cual fue seleccionado. Por otra parte, se usó el mecanismo GRI-Mech 3.0 [22], compuesto de 325 reacciones considerando 53 especies. Este también ha sido usado en estudios cinéticos como es el caso del llevado a cabo por [23], done usaron este mecanismo en el análisis de los modos de ignición considerando una mezcla homogénea de CH4/aire.
2.1 CHEMKIN 19.0
En el caso de CHEMKIN 19.0, las predicciones de τ se llevaron a cabo usando la subrutina AURORA, para la modelación de un reactor. El programa utilizado el solucionador denominado DASPK para las ecuaciones diferenciales asociadas al reactor (energía y especies químicas) [24].
Debido a que en CHEMKIN 19.0 al fijar el tiempo final (tf) de cálculo, el programa aplica el mismo paso de tiempo (Δt) para todas las corridas programadas, se genera una cantidad innecesaria de información (debido a la forma como almacena los datos) cuando este valor es mayor a τ en varios ordenes de magnitud. Por lo tanto, no se hace adecuado llevar a cabo todas las simulaciones usando el valor de tmax para tf, puesto que genera archivos de salida con gran tamaño que complican el procesamiento de los resultados y puede incluso generar que colapse el programa durante el proceso si se usa un ordenador convencional.
Si bien el programa permite realizar el estudio de forma paramétrica asignando valores diferentes de tf para cada condición simulada, su escogencia supone un conocimiento previo del valor de τ. Para evitar estas problemáticas en el presente estudio, se hizo la subdivisión en 3 grupos fijando como valores de tf, 0.01, 3 y 15 segundos. En cada caso se utilizó un paso de tiempo (Δt) correspondiente a Δt=tf/400. Las tolerancias absoluta y relativa asociadas con el método numérico de solución fueron dejadas por defecto en 1.0 x 10-20 y 1.0 x 10-8 respectivamente.
2.2 Cantera
El uso de Cantera en el presente estudio se llevó a cabo usando la interfaz de MATLAB, mediante el desarrollo de códigos y funciones propias junto con las ya predefinidas por este último. La solución de las ecuaciones diferenciales fue llevada a cabo mediante la función de MATLAB ODE15s, la cual está enfocada en problemas rígidos (tipo stiff), lo que la hace apropiada para el presente cálculo dado los valores cercanos a cero por parte de las fracciones de las diferentes especies químicas. En este caso Δt es determinado por la función de forma que no se hace necesario fijar dicho parámetro. De esta manera, Cantera fue usado como interprete cinético y no para la solución de las ecuaciones de conservación.
Todos los cálculos fueron desarrollados con tf = tmax, puesto que por la forma de calcular asociada a Cantera y la flexibilidad en almacenar únicamente los datos deseados mediante la escritura de funciones, se evita el problema que presente su contraparte comercial. De esta forma en el caso de Cantera, todos los cálculos para un mismo mecanismo de reacción fueron llevados a cabo de forma simultánea. Las tolerancias absoluta y relativa asociadas con el método numérico de solución fueron en 1.0 x 10-12 y 1.0 x 10-5 respectivamente.
3. ANÁLISIS ESTADÍSTICO
Para establecer estadísticamente si existen o no diferencias entre los resultados obtenidos de τ usando Cantera respecto a los entregados por CHEMKIN 19.0, se plantearon dos fases globales de análisis basadas en un diseño de experimentos del tipo 2k. Para realizar la comparación se estableció la diferencia relativa (RD) definida por (1):

Donde  y
y  corresponden a los valores del tiempo de retraso a la ignición para en la simulación i, obtenidos con CHEMKIN 19.0 y Cantera respectivamente. La fase I consiste en la comparación de le media muestral de RD respecto a valor fijo mientras que la fase II se centra en el análisis de varianza (ANOVA). La primera fase permite establecer si existe o no diferencia entre los resultados obtenidos, mientras que la segunda se centra en analizar el efecto de diversos factores sobre la conclusión obtenida en la fase I.
corresponden a los valores del tiempo de retraso a la ignición para en la simulación i, obtenidos con CHEMKIN 19.0 y Cantera respectivamente. La fase I consiste en la comparación de le media muestral de RD respecto a valor fijo mientras que la fase II se centra en el análisis de varianza (ANOVA). La primera fase permite establecer si existe o no diferencia entre los resultados obtenidos, mientras que la segunda se centra en analizar el efecto de diversos factores sobre la conclusión obtenida en la fase I.
3.1 Factores de estudio
Para la realización de las simulaciones en ambos programas, se consideraron 6 factores diferentes: temperatura, mecanismo de reacción, fracción molar de H2 en el combustible (X H2 ), φ, presión y tipo de reactor (ver material suplementario). Para los últimos cinco factores se establecieron 2 niveles tal como se muestra en la Tabla 1. En el caso de la temperatura se fijó un rango desde 800 hasta 1250 K con un paso de 50 K, generando un total de 10 valores diferentes.

Ahora bien, debido a que el objetivo al considerar la variación en los factores se centra en identificar la incidencia sobre la variable de respuesta y no en una comparación puntual, las temperaturas se agruparon de forma equitativa en dos categorías detonadas TB y TM, asociadas a temperaturas bajas (800-1000 K) y medias (1050-1250 K) respectivamente.
En el caso de los mecanismos de reacción la nomenclatura M1 corresponde al GRI-Mech 3.0 [22] y M2 al mecanismo 56.54 desarrollado por [20]. De esta forma, fue posible generar como resultado un diseño factorial completo de tipo 26, estableciendo así un total de 64 muestras para el análisis de varianza.
Las categorías asociadas con el tipo de reactor hacen referencia a las consideraciones adicionales a las ya expuestas en cuanto a las aproximaciones asumidas. La sigla uv se usa para considerar el volumen del reactor como constante, mientras que hp denota una presión constante al interior de este.
3.2 Fase I: comparación de medias
En esta fase se realiza la comparación de la media de RD 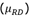 con un valor específico
con un valor específico  , buscando comprobar si efectivamente la diferencia relativa puede considerarse como cero. El valor de
, buscando comprobar si efectivamente la diferencia relativa puede considerarse como cero. El valor de 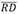 como estimación de se calcula mediante el promedio aritmético de RD, usando la totalidad de las simulaciones realizadas. Para la comparación se plantean las hipótesis nula y alternativa de acuerdo con (2):
como estimación de se calcula mediante el promedio aritmético de RD, usando la totalidad de las simulaciones realizadas. Para la comparación se plantean las hipótesis nula y alternativa de acuerdo con (2):

Este conjunto de hipótesis se denomina con la letra a en lo que sigue del texto. Tal como se expone postreramente en la sección de resultados, se hace necesario rechazar la hipótesis nula planteada en (2) y dado que la hipótesis alternativa únicamente confirma que es diferente al valor  se hace necesario replantear las hipótesis de la siguiente manera a través de (3):
se hace necesario replantear las hipótesis de la siguiente manera a través de (3):

Donde  se establece de acuerdo con los valores encontrados para. La condición planteada en la hipótesis alternativa se establece debido a que una vez comprobado que estadísticamente existe una diferencia, se desea acotar mediante un límite superior la mencionada variación. Estas hipótesis de denotan como b para las secciones posteriores.
se establece de acuerdo con los valores encontrados para. La condición planteada en la hipótesis alternativa se establece debido a que una vez comprobado que estadísticamente existe una diferencia, se desea acotar mediante un límite superior la mencionada variación. Estas hipótesis de denotan como b para las secciones posteriores.
Para llevar a cabo la evaluación de las hipótesis, se usó la prueba de distribución t, debido a que no se conoce la varianza del problema. Para evaluar la idoneidad de la aplicación de la prueba se construyó la gráfica de probabilidad acumulada para los datos y de esta manera verificar si estos muestran una distribución normal (ver Figura 1).
Claramente existe una desviación considerable respecto a la normalidad de los datos, lo que hace que la aplicación directa de la prueba no sea apropiada. Si bien algunos autores confirman que puede aplicarse la evaluación cuando los datos presentan una distribución alejada de la normal [25] de forma moderada, no es aplicable al presente caso puesto que, al calcular el sesgo y la curtosis estandarizados, se encuentran valores de 14.26 y 16.24 los cuales son muy lejanos de los límites de ±2 considerados para una distribución normal. Debido a esto se utiliza una diferencia relativa transformada (RDT) relacionada con RD de acuerdo con (4):

La nueva variable RDT presenta una distribución acorde a la normal que permite aplicar la prueba t, tal como se puede apreciar en la Figura 2. En este caso el sesgo y la curtosis estandarizados tienen valores de -1.0 y -1.94, confirmando lo expuesto de manera gráfica.
La naturaleza de la transformación establecida permite que no exista una alteración en el análisis planteado mediante la comparación para el objetivo deseado, puesto que si RD es igual a 0 también lo será RDT, además de ser una variable conservadora puesto que siempre será mayor a RD, tiendo en cuenta todos los valores de esta última son inferiores a la unidad. Ahora bien, se hace necesario reconsiderar el cambio de por  en las hipótesis definidas en (2) y (3), además de tener en cuenta que el valor
en las hipótesis definidas en (2) y (3), además de tener en cuenta que el valor  debe estar aplicado a RDT y no a RD. De esta forma entonces el estadístico de evaluación usado en la prueba está dado por (5).
debe estar aplicado a RDT y no a RD. De esta forma entonces el estadístico de evaluación usado en la prueba está dado por (5).

Donde  es la estimación de , S es la estimación de la desviación estándar,
es la estimación de , S es la estimación de la desviación estándar,  es el valor específico de comparación según la hipótesis planteada y n es el número de datos, el cual para este caso es de 320 puesto que se usaron todas las simulaciones realizadas.
es el valor específico de comparación según la hipótesis planteada y n es el número de datos, el cual para este caso es de 320 puesto que se usaron todas las simulaciones realizadas.
3.3 Fase II: análisis de varianza (ANOVA)
La realización de un análisis de varianza dentro del estudio se enmarca en corroborar que las conclusiones de la fase I sean extensibles y no se vean alteradas ante la variación de un determinado factor, es decir, se busca establecer si el resultado se mantiene o puede alterarse ante un cambio en los factores considerados y por tanto las desviaciones entre Cantera y CHEMKIN 19.0 dependen de las condiciones de operación abordadas.
El análisis de ANOVA se desarrolló de acuerdo con los factores y niveles considerados en la Tabla 1 Para esto, se definió la diferencia relativa promedio (RDA), la cual fue calculada como el promedio aritmético de los RDT obtenidos con los 5 valores correspondientes a cada categoría de temperatura TB y TM. De esta forma entonces, se tienen 64 muestras en total de RDA sobre las cuales se aplica el análisis.
En el enfoque de ANOVA aplicado sobre esta variable, se consideró inicialmente interacciones de hasta sexto orden. La nomenclatura usada por STATGRAPICHS para los factores corresponde a la tercera columna de la Tabla 1y será usada en el resto del documento para referirse a cualquiera de estos. Posteriormente de acuerdo con los resultados, diversos efectos fueron descartados. En la Figura 3 se muestra la gráfica de probabilidad acumulada para RDA, evidenciando una clara tendencia a una línea recta y por tanto a una distribución normal. Los valores de sesgo y curtosis estandarizados son en este caso de -1.46 y -0.99, confirmando así el comportamiento de los datos. Lo anterior confirma la viabilidad de aplicar el análisis de ANOVA, posteriores confirmaciones se exponen en la sección de resultados al descartar diversos efectos.

4. RESULTADOS Y DISCUSIÓN
4.1 Comparación de la media
La comparación de  se hizo primero con las hipótesis descritas a, donde el valor de comparación 𝜇 0,𝑎 es igual a cero. Es decir, se quiere establecer si efectivamente no existen desviaciones en los resultados obtenidos de Cantera respecto a los entregados por CHEMKIN 19.0. En la Tabla 2 se listan los parámetros estadísticos y los valores calculados a partir de los resultados de las simulaciones.
se hizo primero con las hipótesis descritas a, donde el valor de comparación 𝜇 0,𝑎 es igual a cero. Es decir, se quiere establecer si efectivamente no existen desviaciones en los resultados obtenidos de Cantera respecto a los entregados por CHEMKIN 19.0. En la Tabla 2 se listan los parámetros estadísticos y los valores calculados a partir de los resultados de las simulaciones.
En la Tabla 3, se muestran los resultados del valor de prueba 𝑡 0 junto con los criterios de rechazo de la hipótesis nula en cada caso. Para las hipótesis a se cumple el criterio, por tanto, se rechaza H
0
y se concluye con un nivel de significancia del 5 % que  es diferente de cero. Esto permite establecer que efectivamente existen desviaciones en los resultados obtenidos con Cantera en comparación a los entregados por CHEMKIN 19.0, aunque esta prueba no garantiza que las diferencias sean significativas. Es por esta razón, que se plantea la condición de hipótesis b donde de acuerdo con el valor obtenido de se selecciona como 0.8. De esta manera, la segunda prueba permite establecer si la media de la variable establecida es igual a 0.8 o menor a este valor. Los resultados muestran que se cumple el criterio de rechazo para la hipótesis nula, con lo que se puede establecer con el mismo nivel de significancia que
es diferente de cero. Esto permite establecer que efectivamente existen desviaciones en los resultados obtenidos con Cantera en comparación a los entregados por CHEMKIN 19.0, aunque esta prueba no garantiza que las diferencias sean significativas. Es por esta razón, que se plantea la condición de hipótesis b donde de acuerdo con el valor obtenido de se selecciona como 0.8. De esta manera, la segunda prueba permite establecer si la media de la variable establecida es igual a 0.8 o menor a este valor. Los resultados muestran que se cumple el criterio de rechazo para la hipótesis nula, con lo que se puede establecer con el mismo nivel de significancia que  es menor a 0.8.
es menor a 0.8.
Este resultado es importante, ya que, si bien estadísticamente se puede establecer que existen diferencias entre los resultados de los dos programas, se puede estimar un límite superior para estas discrepancias. Además, el mencionado valor es bajo desde un punto de vista práctico y de ingeniería, si se tiene en cuenta que RDT es la raíz sexta de RD (diferencia relativa), indicando que esta última será incluso menor. Para completar el análisis se calculó el intervalo de confianza al 95 % para el valor de usando (6):

De esta manera, se establece que estará contenida en el intervalo [0.67 0.71]. Bajo esta consideración es posible estimar desde un enfoque de ingeniería, que las desviaciones que se pueden encontrar al usar Cantera para la predicción de τ respecto a CHEMKIN 19.0 son despreciables, aunque existen estadísticamente. En la siguiente sección se analiza cuales factores pueden ser los generadores de que aparezcan estas diferencias.
4.2 ANOVA
A partir del análisis de ANOVA se establecen cuáles de los factores o sus interacciones tienen un efecto importante sobre la variable de respuesta RDA. En la Figura 4 se muestra la gráfica de probabilidad normal acumulada de los efectos, las etiquetas de estos y sus interacciones fueron omitidas para facilitar la visualización, únicamente se señalan los factores A y B.

De la Figura 4 se hace evidente de forma cualitativa que la gran mayoría de efectos y sus interacciones no tienen incidencia desde un punto de vista estadístico sobre RDA. Para confirmar esta apreciación de forma cuantitativa en la Tabla 4, se muestra el resumen de la ANOVA, donde se resaltan el factor A, B y la interacción AB como los de mayor incidencia de acuerdo con la suma de cuadrados. Sin embargo, tanto B como la interacción AB están por debajo en hasta un orden de magnitud en comparación con el efecto del factor A. Descartando todos los demás efectos y conservando únicamente los mencionados, se obtiene una segunda tabla ANOVA (ver Tabla 5). De acuerdo con esto solo los factores A y B son estadísticamente significativos, si bien AB parece serlo también, está por debajo un orden de magnitud de ambos factores principales y por tanto puede descartarse, generando así la Tabla 6 con el análisis de ANOVA definitivo.
Tabla 4 Análisis de ANOVA considerando todos los factores e interacciones

Fuente: Elaboración propia.
Tabla 5 Análisis de ANOVA considerando los factores e interacciones estadísticamente significativos

Fuente: Elaboración propia.
De esta manera se evidencia que 4 de los 6 efectos considerados y todas las interacciones no tienen un efecto significativo sobre la RDA, lo que se traduce en que ninguno de estos genera variaciones importantes sobre las diferencias encontradas entre los resultados de Cantera y CHEMKIN 19.0. Dicho de otra manera, cualquier cambio en la presión, X H2 , φ o el tipo de reactor considerado no aumenta ni disminuye la variación de los resultados obtenidos con Cantera respecto a CHEMKIN 19.0 enmarcados en la RDA, más allá de lo establecido por el límite superior encontrado en la comparación de medias.
De la Tabla 6 se puede apreciar como el factor A continúa siendo mucho más incidente que el B, puesto que la suma de cuadrados del primero es más de 5 veces la del segundo. También es necesario considerar que los mecanismos de reacción se trataron como variables independientes de entrada para el proceso, bajo la premisa que sus variaciones se centran en las reacciones y especies químicas que los componen. No obstante, de forma inherente estos pueden ser dependientes de la temperatura, en el sentido que los parámetros para calcular las tasas de reacción son función de esta variable y si bien un cambio en esta puede pensarse que afecta a los dos por igual, esto solo sería válido si para una misma reacción tuviesen los mismos parámetros cinéticos, pero esto no siempre ocurre. Un ejemplo claro de esto puede verse con la reacción  , la cual de acuerdo con un reciente estudio es relevante en el proceso de autoignición [26], cuyos parámetros cinéticos son muy diferentes entre mecanismos. En M1 esta reacción tiene energía de activación nula en M2 es -687.5 cal/mol, el exponente de la temperatura en M1 es cero y en M2 es 0.269, mientras que los factores pre - exponenciales son 3.78 x 1013 y 1 x 1012 para M1 y M2 respectivamente, lo cual claramente ante cambios de temperatura puede generar variaciones en los resultados. Bajo esta consideración, se puede establecer que, de darse algún cambio en los resultados, el efecto que lo genera es la temperatura ya sea de forma expresa o implícita. Lo anterior debe analizarse de forma detallada y va más allá del alcance del presente estudio y se deja como trabajo futuro. Sin embargo, como una primera aproximación puede establecerse que es la temperatura el único factor que puede generar cambios en las diferencias relativas entre los resultados de ambos programas.
, la cual de acuerdo con un reciente estudio es relevante en el proceso de autoignición [26], cuyos parámetros cinéticos son muy diferentes entre mecanismos. En M1 esta reacción tiene energía de activación nula en M2 es -687.5 cal/mol, el exponente de la temperatura en M1 es cero y en M2 es 0.269, mientras que los factores pre - exponenciales son 3.78 x 1013 y 1 x 1012 para M1 y M2 respectivamente, lo cual claramente ante cambios de temperatura puede generar variaciones en los resultados. Bajo esta consideración, se puede establecer que, de darse algún cambio en los resultados, el efecto que lo genera es la temperatura ya sea de forma expresa o implícita. Lo anterior debe analizarse de forma detallada y va más allá del alcance del presente estudio y se deja como trabajo futuro. Sin embargo, como una primera aproximación puede establecerse que es la temperatura el único factor que puede generar cambios en las diferencias relativas entre los resultados de ambos programas.

Bajo este escenario es posible estimar la causa de las diferencias entre las predicciones. Para esto es importante tener en cuenta que τ tiene una dependencia altamente no lineal con la temperatura, por lo cual cambios entre los conjuntos TB y TM pueden ocasionar diferencias de varios ordenes de magnitud. Esto genera que los pasos de tiempo usados durante la solución puedan ser viables para ciertos valores de temperatura, pero al aumentarse el tf considerado, pueden ser demasiado grandes y omitir variaciones de las especies y por tanto generar desfases en el valor de τ. La ocurrencia de este proceso es precisamente posible en CHEMKIN 19.0 donde el paso es fijado por el usuario o tomado por defecto como tf/100 por el programa. De esta forma la aparente incidencia de la temperatura respecto a las desviaciones de los resultados con Cantera puede no ser un efecto directo sino una consecuencia ocasionada por el Δt establecido que no permite captar determinados comportamientos. De una manera análoga a lo descrito anteriormente relación con la dependencia de la temperatura por parte de los mecanismos, se hace necesario un estudio enfocado en estos aspectos, lo cual está por fuera del alcance del presente trabajo. Es importante recordar además que el límite encontrado en la fase I del estudio es muy bajo y en las variaciones puede estar inmerso el error de redondeo asociado a todo cálculo por computador.
Finalmente, para confirmar que los resultados obtenidos en la tabla de ANOVA son adecuados y las aproximaciones del modelo estadístico se cumplen, es necesario evaluar la normalidad y la independencia de los datos En el primer caso se construye una gráfica de probabilidad acumulada usando los residuales, la cual se muestra en la Figura 5.

Es evidente que los datos tienen una clara tendencia lineal, el sesgo y la curtosis estandarizados tienen en este caso valores de -0.38 y -1.32 confirmando la normalidad de los datos. Para corroborar la independencia de estos, en la Figura 6 se muestran los residuales en función de los valores predichos por el modelo estadístico.

En general, se aprecia que no hay un patrón claramente definido por parte de los residuales, lo cual es de esperarse al ser datos obtenidos mediante simulación donde no existe influencia entre las pruebas realizadas, lo que permite establecer que existe una varianza constante. De esta forma se confirma que el modelo aplicado es adecuado y se cumplen las aproximaciones establecidas para la variable de respuesta transformada, lo que valida los resultados y análisis obtenidos a partir del análisis de ANOVA.
4.3 Comparación cualitativa
De acuerdo con los resultados expuestos en las secciones previas, para los resultados de τ obtenidos con ambos códigos, puede considerarse que no existe una diferencia relevante bajo un enfoque de ingeniería. Sin embargo, durante el proceso de cálculo se evidenciaron distintos aspectos en los que difieren Cantera y CHEMKIN 19.0 que pueden resultar relevantes al momento de seleccionar alguno de estos programas para llevar a cabo estudios cinético - químicos relacionados con el fenómeno de autoignición. En la Tabla 7 se muestra una comparación descriptiva tomando en cuenta algunos de los tópicos de mayor relevancia donde se encontraron diferencias. Es importante resaltar que en esta comparación se abordó únicamente la versión con interfaz de usuario para CHEMKIN 19.0, el cual también posee una versión de programación que no fue utilizada durante el presente estudio.
Tabla 7 Análisis de ANOVA considerando los factores e interacciones estadísticamente significativos.

Fuente: elaboración propia.
Las diferentes características expuestas en la comparación sugieren que la elección de uno u otro código está asociada a diferentes aspectos como la experticia en programación del investigador o el tipo de estudio que desea abordar, aunque de acuerdo con el análisis estadístico desarrollado previamente, no se obtendrá discrepancias incidentes sobre los resultados finales y por tanto las ventajas de uno u otro radican en factores particulares de cada estudio.
5. CONCLUSIONES
En el presente trabajo se llevó a cabo el estudio sobre las posibles diferencias obtenidas en las predicciones del tiempo de retraso a la ignición cuando se usa el código libre de Cantera en comparación al programa comercial CHEMKIN 19.0. Para ello se llevaron a cabo una serie de simulaciones en ambas aplicaciones considerando un reactor cero dimensional, adiabático y perfectamente mezclado. Se tomaron 6 factores diferentes para obtener los resultados: temperatura, mecanismo de reacción cantidad de H2 en el combustible, relación de equivalencia, presión y tipo de reactor (volumen o presión constantes). El análisis se llevó a cabo en dos fases, durante la primera se aplicó un enfoque de comparación de medias para establecer si existe o no diferencia entre los resultados, mientras en la fase II se llevó a cabo un análisis de ANOVA para estimar si los resultados obtenidos de la fase I son dependientes de los factores estudiados. En ambos casos se aplicó una transformación a la variable de respuesta originalmente planteada para cumplir la condición de normalidad en los datos.
A partir de los resultados obtenidos y del análisis de estos es posible establecer las siguientes conclusiones. Existe desde un punto de vista estadístico diferencia entre los resultados obtenidos para τ por parte de Cantera en comparación a los entregados por CHEMKIN 19.0, aunque esta variación es mínima y desde un punto de vista práctico y de ingeniería no constituye una desviación relevante. La raíz sexta de la posible desviación que se obtiene al usar Cantera para estimar τ en comparación a CHEMKIN 19.0 estará entre 0.67 % y 0.71 % con un nivel de confianza del 95 %, teniendo en cuenta que la raíz sexta es mucho mayor al valor de la desviación relativa, puesto que esta es menor a uno, se garantiza que los resultados son acordes cuando se usa el programa de código libre.
El principal factor que afecta el grado de desviación en los resultados de Cantera en comparación CHEMKIN 19.0 es la temperatura. Aunque este comportamiento puede estar asociado con la limitación del paso de tiempo fijo que utiliza el programa comercial, donde se pueden omitir efectos cuando el paso es muy grande en comparación al orden de magnitud de τ generados por la evaluación de una temperatura mayor. El desarrollo de simulaciones de forma simultánea en Cantera es mucho más eficiente debido el usuario puede programar la cantidad de datos que desea guardar, en comparación al modo empelado por CHEMKIN 19.0 donde se hace de forma automática (desde la interfaz de usuario, en el estudio no se evaluó eso de versión de programación) y se generan archivos muy pesados que pueden generar problemas en el procesamiento.

