











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
PermalinkLos tomadores de decisiones requieren de información actualizada y veraz para poder diseñar y ejecutar políticas de salud pública efectivas. Dado que este tipo de informaciones no siempre están disponible, se hace necesario modelar los datos existentes a fin de explotar las relaciones entre ellos para generalizar las observaciones obtenidas y producir indicadores con niveles de confianza suficientes como para formular alguna política pública. Este tipo de modelos predictivos se han consolidado en una importante línea de investigación en el diseño de políticas en salud pública dado su potencial para desarrollar herramientas de análisis y seguimiento de las tendencias de mortalidad en diversas poblaciones.
Aunque es difícil establecer cuál es el nivel de confianza y precisión de las predicciones hechas por estos modelos, su utilidad deriva de su capacidad para simular diferentes situaciones y tendencias de la realidad, apoyándose en la coherencia de los datos y respetando las relaciones intrínsecas entre ellos.
Entre los indicadores que pueden ser modelados, la tasa de mortalidad en una sociedad es uno de los más utilizados y valiosos. Este indicador ha sido analizado mediante diversas aproximaciones que se pueden dividir en modelos explícitos e implícitos. Los modelos explícitos o estructurales predicen la mortalidad como función de un conjunto de variables observables y medibles. Por su parte, los modelos temporales requieren de variables que registren las tendencias globales y locales en el tiempo. Mientras los modelos estructurales permiten desagregar la información más fácilmente y establecer causalidad en la carga de la enfermedad, las predicciones con series temporales pueden ser más adaptables a los patrones globales.
Entre los modelos temporales, uno de los más conocidos fue el propuesto en 1992 por Lee y Carter 1. Este método se basaba en hacer predicciones a largo término del tipo y patrón de edades de las enfermedades. Los autores se basaron en una combinación de métodos estadísticos para el análisis de series temporales y una simplificación de la distribución por edades de la mortalidad. El modelo de Lee-Carter ha ganado popularidad en las últimas décadas, usándose como punto de partida en modelos posteriores tales como el propuesto por Renshaw y Haberman en 2006 2. Este último es una extensión del modelo Lee-Carter que logra mayor generalidad mediante la introducción de una familia más amplia de funciones paramétricas no lineales. Así mismo, el modelo de Booth-Maindonald-Smith 3 es una modificación del modelo de Lee-Carter que se ajusta selectivamente usando únicamente los años en los que el supuesto de una mejora lineal en la mortalidad es válida.
Otros modelos posteriores incluyen el de Hyndman y Ullah 4, que predice mortalidad y fertilidad ajustadas por grupos de edades, o el de Cairns-Blake-Dowd 5, un trabajo que tiene en cuenta las curvas relativamente sencillas de mortalidad a mayor edad. Cabe mencionar que en algunos casos las simples regresiones lineales pueden ser usadas para modelar los datos con resultados relativamente satisfactorios.
Entre los modelos estructurales, el "Global Burden of Disease Study" 6,7 es uno de los más conocidos y estudiados. Este trabajo formula la estimación de muertes anuales a nivel mundial entre 1980 y 2010 para 235 causas. Los datos provienen de registros vitales, autopsias verbales, censos, entrevistas, registros en hospitales, registros policiales y morgues. La calidad de los datos se evalúa por completitud, precisión del diagnóstico, datos faltantes, variaciones estocásticas y causas de muerte probables. Se aplican 6 estrategias de modelamiento diferente, siendo la estrategia dominante la cause of death ensemble modelling (CODEM), para causas con suficiente información. Para muertes por violencia o desastres naturales, se usa un proceso simple de regresión mortality shock regressions. Cada causa fue estimada con un intervalo de confianza del 95 %. En este trabajo aparece además la formulación del modelo de Murray 7, un modelo estructural que ha sido usado para un subconjunto de causas, convergiendo de esta forma hacia un marco de trabajo unificado para todas las causas, bajo la restricción de que la suma de las causas específicas sea igual al número de muertes de todas las causas en cada país o región, periodo, edad, grupo o sexo. Las series de tiempo entre 1980 a 2010 se utilizaron para el análisis, pero los reportes se hicieron con los datos entre 1990 y 2010.
En el presente trabajo entonces se introduce el diseño de un modelo dinámico de la mortalidad en Colombia. Dada la enorme variabilidad y dependencia estadística entre las diferentes poblaciones locales a analizar, se hace necesario realizar particiones de los datos que incrementen la independencia y disminuyan los factores que introducen sesgo entre las diferentes medidas. El análisis requiere entonces de una organización de la información por categorías, empezando por regiones, luego departamentos y finalmente municipios. Igualmente, la diferenciación entre géneros y edades facilita la desagregación de la información en variables con mínima dependencia. Es posible que en esta secuencia de particiones no se logre obtener el grado de independencia necesario, cuando la lista de factores que inciden en la mortalidad es también parcial, una situación con la cual todos los modelos deben mostrar algún grado de robustez.
El modelo permite un análisis particular por causa de muerte en términos de las tendencias temporales y predice los casos esperados para un periodo pre-definido por el grupo de tomadores de decisiones. Se estimó además el logaritmo de la razón mortalidad-incidencia como una función del ingreso nacional per cápita, con efectos aleatorios para el país, año y edad, redistribuyendo las muertes de acuerdo a los "códigos basura" (códigos de enfermedad mal asignados). Adicionalmente, se suaviza la fluctuación estocástica de los datos usando el log del death rate. Para las causas específicas se usó CODEM, un ensamble de cuatro familias de modelos estadísticos usando covariables y modelos lineales con efectos mezclados. Este trabajo se complementa con la publicación en 2013 de las estimaciones de muertes anuales para 188 países entre 1990 y 2013.
METODOLOGÍA
Plataforma de análisis de modelos de mortalidad
Se desarrolló una plataforma web que facilita la interacción con cualquier tipo de modelo y por tanto promueve el trabajo colaborativo y el ajuste de los modelos de mortalidad. Esta herramienta le permite al usuario obtener rápidamente las tasas de mortalidad partiendo de un conjunto de datos. Gracias al diseño amigable de la interfaz de usuario, los datos son fácilmente pre-procesables. En este tipo de aplicaciones es común el desarrollo de algún tipo de vocabulario controlado que codifique los diferentes procedimientos médicos asociados a las causas de mortalidad. En estos escenarios es frecuente que la información se vea contaminada, e.g. mediante del registro de causas de muerte imposibles, que deben entonces ser corregidas. Este procesamiento es dispendioso en bases de datos que contienen millones de registros. La re-asignación de dichos códigos también es engorrosa y está, además, sujeta a diversos ajustes, algunos dependientes por la misma información disponible para realizarlo. Este conjunto de factores requiere un proceso fácilmente automatizable que se integre de manera eficiente en la plataforma desarrollada.
Los múltiples problemas presentados se solucionaron además con la inclusión del paquete estadístico R, un entorno y lenguaje de programación implementado como software libre y con un enfoque al análisis estadístico, en el flujo de trabajo 8. El alto grado de especialización y el gran número de librerías disponibles hace que la inclusión de esta herramienta facilita considerablemente el ajuste de modelos de diferente naturaleza. Un punto importante en el desarrollo de este proyecto consistía en facilitar el acceso y la ubicuidad de la plataforma. El principio del modelo de desarrollo fue entonces el de una plataforma con un alto nivel de desacoplamiento entre las diferentes capas, con una arquitectura orientada por servicios 9 y de fácil acceso desde dispositivos de baja capacidad de cómputo.
Procesamiento de los datos
La principal fuente de información para este análisis fueron los Registros de Defunciones No Fetales provenientes del Departamento Administrativo Nacional de Estadística (DANE). Para calcular las tasas de mortalidad se tomaron las estimaciones y proyecciones de población por municipio, grupo de edad y sexo. Finalmente, para el ajuste del modelo propuesto se tomaron los datos del Producto Interno Bruto (PIB) departamental entre los años 2000 y 2013. La información de población y PIB fue tomada de la página web del DANE.
Registros de defunciones no fetales 1998 - 2012
Recodificación de variables
Algunas variables en los registros se encuentran codificadas según ciertas reglas que varían dependiendo del año, para unificar la información se crearon nuevas variables que recodifican estos valores.
Asignación de grupo de edad: Para efectos del análisis, se tendrán en cuenta los siguientes grupos de edad: Menores de 1 año, 1 - 4, 5 - 9, 10 - 14, 15 - 19, 20 -24, 25 - 29, 30 - 34, 35 - 39, 40 - 44, 45 - 49, 50 - 54, 55 - 59, 60 - 64, 65 - 69, 70 - 74, 75 - 79 y 80 o más. Para esto se creó una nueva variable que corresponde al grupo de edad de acuerdo al valor de edad simple previamente asignado.
Recodificación de causa básica de la defunción: La causa básica de la defunción se encuentra codificada según la ciE-10. Para simplificar el análisis, se creó una variable que contiene el evento del GBD (Global Burden Disease) correspondiente al código ciE-10 asociado a cada registro.
Revisión de Completitud
Se revisó la completitud de los registros para las variables: sexo, edad y departamento de residencia. Así como la recodificación de la causa básica de defunción en las categorías GBD. La revisión de los registros entre 1998 y 2012 dio como resultado 27 775 registros con edad desconocida, 526 registros con sexo indeterminado, 44 491 registros sin información de departamento de residencia.
Detección de Causas Imposibles
Debido a que no se dispone de la historia clínica para determinar la exactitud diagnóstica en la causa básica de defunción, se determinaron las siguientes causas imposibles a detectar: causas maternas en hombres, causas maternas en menores de 5 años, cánceres de órganos genitales masculinos en mujeres y cánceres de órganos genitales femeninos en hombres. Después de hacer la detección de estas causas en los registros, se encontró un único caso de un hombre con enfermedades ginecológicas en el 2006.
Estimaciones y proyecciones de población 1985-2020
Se tomaron las estimaciones de población para el período 1985-2005 y las proyecciones de población para el período 2005-2020 que hace el DANE a nivel nacional, departamental y municipal por sexo, edades simples de 0 a 26 años, y grupos quinquenales de edad.
Para usar estos datos se construyeron las tablas de población con los grupos de edad de interés.
Número de defunciones y tasas de mortalidad 1998-2012
Para facilitar la lectura de los datos en el sistema se pre calcularon los números de defunciones por causa, municipio, sexo, grupo de edad, seguridad social y área. Para cada departamento se generó un grupo tablas de frecuencias que resumen esta información por año. Para calcular la tasa de mortalidad asociada a un conjunto de causas en una población de interés, se toma el número de defunciones correspondiente, se divide por la población de interés (tomada de las tablas construidas) y se multiplica por 100 000, en este caso la tasa de mortalidad se da en número de muertes por cada 100 000 habitantes en el grupo poblacional dado. Una vez calculados estos indicadores se detectaron los llamados "códigos basura" y se hizo la redistribución en otras causas:
Detección de "códigos basura"
Esta son causas mal definidas o que están asociadas a complicaciones intermedias que no corresponden a la causa básica de defunción. Después de asignar el evento o categoría GBD los registros de defunciones, se encontraron 477 264 muertes entre 1998 y 2012 asociadas a estos códigos.
Redistribución
Los registros asociados a códigos basura deben ser distribuidos en otras causas o eventos del GBD con el fin de mejorar la validez de los análisis, para esto se usaron los factores de redistribución que usa el Institute for Health Metrics and Evaluation (IHME) 10 con el fin de asignar una porción de cada registro correspondiente a un código basura a registros correspondientes a otras causas pero con las mismas características (ubicación, sexo y edad).
Producto interno bruto 2000-2013
Para la implementación del modelo propuesto es necesario incorporar la información del Producto Interno Bruto (PIB) per cápita. Con el fin de aislar los efectos de la inflación en el modelo se tomó el PIB departamental a precios constantes de 2005, para calcular el PIB per cápita en cada Departamento se usó la información de la población departamental entre 2000 y 2013.
Modelo Propuesto
El modelo propuesto para el análisis es similar al modelo de Murray tomando en cuenta las variables correspondientes al PIB per cápita y año. La variable de capital humano no fue incluida debido a la falta de información a nivel departamental que permitiera capturar ese aspecto.
Dada una región (Departamento, o grupo de municipios de un departamento) R, un grupo de edad e, un género s y una causa (o grupo de causas) i, la tasa de mortalidad (número de muertes por cada 100 000 habitantes) m R,e,s,i se modela como:

Donde:
C R,e,s,i : es un término constante o intercepto.
P R : es el PIB per cápita en el departamento al que pertenece R.
T: representa el año.
Los coeficientes del modelo: C R , e , s , i , β 1 β 2 y β 3 se estiman usando una regresión lineal con los datos disponibles usando el método de mínimos cuadrados. Con este modelo se pueden predecir futuras tasas de mortalidad, así como los límites del intervalo de predicción del 95 %, para estos cálculos es necesario contar con las proyecciones del PIB per cápita departamental, que en este caso se tienen únicamente hasta el 2013.
Validación
Para validar la estrategia y modelo propuesto tomamos los datos de mortalidad en primera infancia (menores de 5 años) a nivel departamental para ambos sexos asociados principalmente a las siguiente causas: complicaciones por parto pre término, otras infecciones de las vías respiratorias inferiores , sepsis y otras enfermedades infecciosas del recién nacido, otras anomalías congénitas, anomalías cardíacas congénitas, encefalopatía neonatal (asfixia y trauma al nacer), otros trastornos neonatales, desnutrición proteico-calórica, lesiones no intencionales no clasificadas en otra parte, otras enfermedades diarreicas. Se seleccionaron estas 10 causas por ser las de mayor tasa de mortalidad en este grupo poblacional a nivel nacional.
Para evaluar el poder predictivo del modelo propuesto se hizo el ajuste por departamento y causa usando los datos de 2000 a 2011 (por la disponibilidad de información para calcular el PIB per cápita), con los modelos ajustados predijimos las tasas de mortalidad para 2012, luego, con los datos reales provenientes de los registros, se calculó el error de predicción y se revisó si la tasa real estaba dentro del intervalo de predicción calculado.
RESULTADOS
Para este análisis se tomaron en cuenta los registros de defunciones de hombres y mujeres menores de un año y entre uno y cuatro años en los 33 departamentos, incluidos el distrito capital. La tasa de mortalidad se calculó como el número de muertes por 100 000 habitantes (de la misma edad en cada departamento).
La metodología y herramienta presentada en este trabajo tiene el objetivo de ser lo suficientemente generalizable para ser aplicada a cualquier grupo de edad, sexo, departamentos, municipios o causas de muerte, es por eso que la tasa usada difiere de la tasa que se calcula en muchos estudios y mediciones de mortalidad en primera infancia 3 (número de muertes por cada 1 000 nacidos vivos), aunque esto no debería ser una limitación pues es posible que el usuario haga la conversión pues el sistema pone a su disposición las estimaciones de población necesarias.
Exploración de Datos 1998-2012
Al calcular la tasa de mortalidad en menores de 5 años para todo el país entre 1998 y 2012, se observa una tendencia general a la baja pero tal como se muestra en la Figura 1 esta tendencia no ha sido del todo uniforme, hubo un ligero aumento entre 1998 y 2000, un período de disminución constante entre 2002 y 2008, algunos períodos de disminución acelerada (2000-2002 y 2008-2010) y para los últimos dos años en los que se dispone de información se observa un estancamiento en la tendencia.

Causas de muerte en primera infancia
Las dos causas con mayores tasas de mortalidad, tanto en 1998 como en 2012, en menores de cinco años son las complicaciones por parto pretérmino y otras infecciones de las vías respiratorias inferiores. La sepsis y otras enfermedades infecciosas propias de recién nacido pasó de ser la octava a la tercera causa de muerte y las anomalías congénitas también aumentaron en su importancia ocupando el cuarto y quinto lugar en el 2012. Las causas que en 1998 ocupaban el cuarto y quinto lugar, encefalopatía neonatal y otras enfermedades diarreicas, descendieron en importancia al sexto y décimo lugar respectivamente.
Algunas tendencias observadas en el comportamiento de las causas durante el período analizado pueden estar fuertemente influenciadas por el proceso de registro, codificación y posible redistribución de la causa asociada a cada defunción, es decir, el aumento en la importancia de alguna causa puede deberse a que anteriormente las defunciones se asociaban a algún "código basura".
En la Figura 2 se muestra la participación en la tasa de mortalidad de las 10 causas más importantes para 2012 desde 1998, cerca de la mitad de las defunciones durante este período se debieron a tres causas: complicaciones por parto pretérmino, otras infecciones de las vías respiratorias inferiores y la encefalopatía neonatal.

Cabe resaltar que una gran proporción de las muertes de menores de cinco años están asociadas a complicaciones o enfermedades propias del nacimiento, por lo que se presume que una gran cantidad de estas muertes se dan antes del año de vida.
Mortalidad en primera infancia por región
En la Tabla 1 se muestra la variación de la tasa de mortalidad en el periodo analizado por departamento, este indicador disminuyó en casi todos los departamentos, siendo notables los casos de Vichada, Quindío y Caquetá donde la tasa de mortalidad infantil disminuyó en más del 60 %. Los únicos departamentos en los que se observa un aumento en la tasa son Cesar, San Andrés y Providencia, y Vaupés, aun así estos se mantuvieron por debajo de Amazonas cuya tasa, a pesar de haber disminuido, fue la más alta del país para el 2012.

La variación de estos indicadores puede estar fuertemente influenciada por el subregistro de defunciones en zonas y departamentos en áreas apartadas del país, asumiendo que este fenómeno es cada vez menor y que cada año se tiene mejor información sobre las muertes en estas áreas, es notable la disminución de la mortalidad infantil en el departamento del Vichada que pasó de tener una tasa de 883,0 en 1998, siendo la más alta del país en ese año, a 198,1 en 2012.
En los 5 departamentos más poblados del país: Bogotá D. C., Antioquia, Valle del Cauca, Cundinamarca y Atlántico, la tasa de mortalidad presentó una disminución cercana al 40 % entre 1998 y 2012, representando una importante disminución en el número de casos y marcando la tendencia a la baja del indicador nacional.
La evaluación de estos indicadores a nivel departamental y municipal permite localizar esfuerzos y priorizar regiones para la implementación de políticas para el mejoramiento de la salud y condiciones de vida de la población. En este sentido, la herramienta diseñada permite visualizar el número de defunciones y calcular las tasas de mortalidad a nivel municipal, e incluso discriminar estas cifras de acuerdo al área de residencia u ocurrencia. Cabe resaltar que la validez de esta información depende directamente de la calidad de los datos suministrados en los registros de defunciones y las estimaciones de población a nivel municipal.
Ajuste y predicción del modelo propuesto
Error de predicción para 2012
Con el fin de evaluar la metodología propuesta, se tomaron las tasas de mortalidad en la población de interés (hombres y mujeres menores de 5 años) para el período comprendido entre 2000 y 2011 en los 33 departamentos. Para poder hacer el análisis por causa de defunción, se tomaron las tasas asociadas a las diez primeras causas de muerte de menores de 5 años para 2012 y se ajustó un modelo para cada causa y departamento.
Con el modelo ajustado con los datos de 2000 a 2011 y el valor del PIB per cápita por departamento en el 2012, se calculó la tasa y el intervalo de predicción para ese año y se comparó con la tasa de mortalidad observada, esto nos permitió obtener un error de predicción de la tasa por departamento y causa.
La Tabla 2 muestra en el error medio de la predicción por causa, a lo largo de los 33 departamentos, y el número de departamentos para los cuales la tasa real está dentro del intervalo de predicción calculado. El error medio de predicción está por debajo de 11 muertes por cada 100000 habitantes para las 10 causas y el intervalo de predicción contiene la tasa observada para 30 o más departamentos en 7 de las causas examinadas. Algunas causas presentan errores más dispersos debido a que su comportamiento no es el mismo en todos los departamentos e incluso en algunos este no está correlacionado con las variables involucradas en el modelo propuesto.
Tabla 2 Error de predicción medio para cada causa y número de departamentos para los cuales la tasa de mortalidad real está dentro del intervalo de predicción

En la Tabla 3 se presenta el error de predicción promedio para cada departamento, por las diez causas modeladas, como también el número de causas para las cuáles la tasa observada está dentro del intervalo de predicción calculado. El modelo propuesto se ajusta y predice relativamente bien las tasa de mortalidad por causa para la mayoría de departamentos, los errores de predicción más bajos se dan en Antioquia, Valle del Cauca, Cundinamarca y Bogotá D.C., los cuatro departamentos más poblados del país, lo cual implica una mejor capacidad de predicción en los departamentos donde se pueden registrar la mayor cantidad de defunciones.
Tabla 3 Error de predicción medio para cada Departamento y número de causas para las que la tasa de mortalidad real está dentro del intervalo de predicción
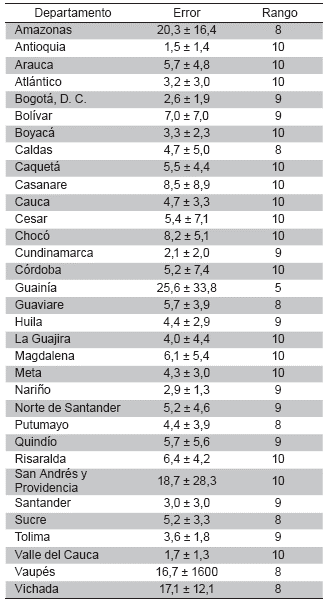
Los errores de predicción más altos en la Tabla 3 se dan en departamentos de la región amazónica y San Andrés y Providencia, así como también con los departamentos con menor número de tasas reales dentro del intervalo de predicción. Esto puede deberse a dos hechos no necesariamente excluyentes: son regiones apartadas donde no se cuenta con un registro completo y adecuado de las defunciones, y también se trata de Departamentos con poca población donde el número de defunciones es bajo y no se puede observar una tendencia general, o esta no puede ser explicada por los mismos factores que en el resto del país.
Predicciones para 2013
Para predecir la tasa de mortalidad en 2013 por departamento y causa se utilizaron los datos de 2000 a 2012 para ajustar el modelo y las proyecciones para el 2013 del PIB per cápita y la población. Como resultado se obtuvo un valor para la tasa y un intervalo de predicción del 95 %. Como se vio en la prueba con datos de 2012, en los Departamentos de la región amazónica y en San Andrés y Providencia se tienen intervalos de predicción muy amplios que indican una mayor incertidumbre sobre la tasa que calcula el modelo, contrario a lo que sucede en Antioquia, Bogotá, Cundinamarca y Valle del Cauca, donde la amplitud de estos intervalos, o el nivel de incertidumbre de la predicción, es menor.
La Tabla 4 muestra la causa de muerte en menores de cinco años más importante por departamento de acuerdo a las predicciones calculadas a partir del modelo para 2013 y su tasa respectiva. En la mayoría de departamentos la causa más importante de defunción seguirá siendo las complicaciones por parto pretérmino, el hecho de que esta no sea la causa más importante en aquellos departamento donde el modelo no es tan confiable es una razón más para proponer una revisión a futuro sobre la calidad de la información y los factores que podrían explicar la mortalidad en dichos departamentos.

DISCUSIÓN
El seguimiento y predicción de la mortalidad son indicadores ampliamente utilizados por los sistemas de salud para la toma de decisiones informadas, la formulación de políticas y lineamientos en el sector salud, la priorización del gasto y la determinación de la carga de la enfermedad. En razón de la complejidad asociada con las relaciones entre las diferentes variables que determinan la mortalidad en una población, gran parte de los análisis se realizan por medio de algún modelo que establece alguna relación entre los datos. Los modelos propuestos en la literatura para analizar y predecir la mortalidad se pueden dividir en dos grandes grupos según el tipo de aproximación: modelos de primer orden y modelos temporales.
Los modelos de primer orden, como el aquí propuesto, describen la tasa de mortalidad como una variable que depende, de manera polinomial, de otras variables que pueden ser de tipo demográfico o socio-económico. Por supuesto estas relaciones simplemente expresan la no linealidad y son altamente dependientes de la partición de los datos. Los modelos de series de tiempo 6,7, describen la mortalidad como un conjunto de tendencias y respuestas a estas tendencias según ciertas variables de interés como la edad.
Mientras la mayoría de estudios encontrados en la literatura restringen el uso de modelos matemáticos para analizar las tendencias en mortalidad para una o varias causas a nivel país, el modelo e implementación presentada en este trabajo permiten desagregar la información hasta el nivel municipal para diferentes causas, grupos de edad y sexos. Otra ventaja de la metodología propuesta es que permite introducir información adicional como nuevas variables que pueden explicar con mayor precisión diferentes tendencias en casos específicos de estudio.
El nivel de desagregación posible con este tipo de modelos depende directamente de la información disponible para cada nivel, siendo esta una de las principales barreras encontradas en el desarrollo de este trabajo. En efecto, solo se incluyeron las variables población y PIB per cápita departamental, pues al momento de implementar la metodología fue imposible encontrar información confiable que permitiera usar otras variables tales como la escolaridad o el índice de tabaquismo. Por lo tanto, el modelo presentado se adapta además al tipo de información que tradicionalmente se ha recogido en el país por parte de las diferentes entidades encargadas de construir los indicadores responsables de la política pública.
Así mismo, es importante resaltar que en algunos casos la aplicación de un modelo con un alto nivel de desagregación puede conllevar a resultados poco confiables. Particularmente, en el caso de la mortalidad infantil en departamentos con poblaciones reducidas o con un alto nivel de subregistro, pequeñas variaciones en el número de defunciones pueden generar grandes variaciones en la tasa de mortalidad, esto se puede observar en algunos departamentos de la región amazónica y San Andrés y Providencia(Tabla 3).
Los modelos de mortalidad se han constituido en una herramienta para los tomadores de decisiones al facilitar el análisis conceptual de las tendencias pasadas y determinar el comportamiento futuro de la mortalidad. La metodología y modelo propuesto tienen el potencial de convertirse en un instrumento que permita priorizar esfuerzos, elaborar una política pública eficaz y orientar las prioridades del gasto en salud utilizando algún tipo de evidencia

