










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkRevista Ingenierías Universidad de Medellín
Print version ISSN 1692-3324On-line version ISSN 2248-4094
Rev. ing. univ. Medellín vol.8 no.15 suppl.1 Medellín July 2009
La teoría de valor extremo y el riesgo operacional: una aplicación en una entidad financiera
Extreme value theory and operational risk: an application to a financial institution
Juan Guillermo Murillo Gómez*
* MSc. En Ingeniería Administrativa, Universidad Nacional de Colombia. jgmurillo@udem.edu.co
Resumen
Este artículo presenta la aplicación de la teoría de valor extremo (EVT) para cuantificar la distribución de pérdidas en riesgo operacional, a partir de datos internos y externos; se analizaron por separado las distribuciones de frecuencia y severidad, para luego combinarlas y hallar la distribución de pérdidas, la cual se dividió en dos áreas: el cuerpo hasta un umbral, y la cola.
Palabras clave: LDA, EVT, severidad, frecuencia, cuerpo de la distribución, cola de la distribución.Abstract
This paper presents the application of Extreme Value Theory (EVT) in order to quantify the loss distribution in operational risk, from internal and external data; frequency and severity distributions were analyzed separately, then they were combined to find the loss distribution, which was divided into two areas: the body —until a threshold— and the tail.
Key words: LDA, EVT, severity, frequency, distribution body, distribution tail.
INTRODUCCIÓN
Debido a la diversidad, las perturbaciones internas o externas, las actividades comerciales y la imprevisibilidad de su incidencia financiera, la medición del riesgo operativo es muy distinta de los otros tipos de riesgos financieros. Si bien algunos tipos de riesgos operativos parecen medibles con cierta facilidad como la falla en los sistemas, otros son más complejos de medir por sus características intrínsecas, y por la ausencia de datos históricos.
El riesgo es la probabilidad de ocurrencia de un evento negativo debido a la vulnerabilidad del sistema y a la complejidad de las operaciones financieras; estas últimas son el origen de una gama de sucesos. Algunas se caracterizan por su baja frecuencia y alta severidad, y sus efectos suelen ser devastadores económicamente, como plantea González [1]. En estos casos, la metodología empleada es la de Teoría de Eventos Extremos.
En un modelo planteado por Fontnouvelle et al. [2] para determinar si las regularidades en los datos de pérdida son viables para modelar las pérdidas operacionales, llevado a cabo con datos aportados por seis bancos internacionalmente activos, se encontró que hay semejanza en los resultados de los modelos de pérdida operacional a través de las instituciones, y que dichos resultados son consistentes con las estimaciones del riesgo operacional y el capital de los bancos. Dicho modelo comenzó considerando la cola de la distribución de pérdida arrojada por cada banco, la línea de negocio y el tipo de acontecimiento. Tres resultados emergieron claramente de este análisis descriptivo. Primero, los datos de la pérdida para la mayoría de las líneas de negocio y los tipos de acontecimiento se pueden modelar por una distribución tipo Pareto, pues la mayor parte de los diagramas de la cola son lineales cuando están expresados a una escala de registro–registro. En segundo lugar, la medida de la severidad de los tipos del acontecimiento es constante a través de las instituciones, y en tercer lugar, los diagramas de la cola sugieren que las pérdidas para ciertas líneas de negocio y tipos de acontecimiento son muy pesadas.
En la medición cuantitativa, el análisis de datos del riesgo operacional ha llegado a ser extenso, las distribuciones de frecuencia y la severidad se están analizando por separado; la severidad la dividen en dos áreas: el cuerpo hasta un umbral, y la cola. En el cuerpo es de uso frecuente construir una función de distribución empírica, o dados los parámetros a veces se ajusta una distribución Lognormal; mientras, la cola se está modelando con teoría del valor extremo (EVT). Sin embargo, es bien sabido que las estimaciones en muestras pequeñas no son muy buenas. [2–4], han propuesto una técnica de regresión basada en EVT que corrige la estimación para muestras pequeñas del parámetro de la cola; estos autores aplicaron esta técnica a seis bancos y obtuvieron estimaciones razonables y consistentes con resultados anteriores usando datos externos.
Este artículo presenta la aplicación de una metodología para cuantificar la distribución de pérdidas en riesgo operacional a partir de datos internos y externos; se analizaron por separado las distribuciones de frecuencia y severidad, para luego combinarlas y hallar la distribución de pérdidas, la cual se dividió en dos áreas: el cuerpo hasta un umbral, y la cola. Esta última, se modeló usando teoría extrema del valor extremo (EVT) y el cuerpo, usando LDA (Loss Distribution Approach).
1. ENFOQUE DE DISTRIBUCIÓN DE PÉRDIDAS (LDA)
El enfoque LDA proporciona estimaciones para la pérdida, tanto por línea de negocio como por evento. Dicha distribución de pérdida es producto de la combinación entre un proceso estocástico discreto asociado a la frecuencia, y un proceso continuo asociado a la severidad de los eventos de riesgo. Este enfoque ha sido utilizado en los trabajos de [4–13] con gran éxito en la modelación de la distribución de pérdidas, la cual es fundamental para el cálculo de la matriz de capital propuesta por Basilea.
1.1 Principales supuestos del LDA
En el LDA la pérdida total se define como una suma aleatoria de las distintas pérdidas:
 (1)
(1) Donde sij es la pérdida total en la celda i, j de la matriz de pérdidas. Las sij se calculan como:
 (2)
(2) Con N variable aleatoria que representa el número de eventos de riesgo en la celda i, j (frecuencia de los eventos) y XN es el monto de la pérdida en la celda i, j (severidad del evento). En consecuencia, las pérdidas son resultado de dos diferentes fuentes de aleatoriedad: la frecuencia y la severidad.
En esencia, el modelo LDA tal como se utiliza en el riesgo operativo o en ciencias actuariales asume los siguientes supuestos dentro de cada clase de riesgo:
a) N y XN la variable frecuencia es una variable aleatoria independiente de la variable aleatoria severidad.
b) XN las observaciones de tamaño de pérdidas (severidad) dentro de una misma clase se distribuyen idénticamente.
c) XN las observaciones de tamaño de pérdidas (severidad) dentro de una misma clase son independientes.
El primer supuesto admite que la frecuencia y la severidad son dos fuentes independientes de aleatoriedad. Los supuestos dos y tres significan que dos diferentes pérdidas dentro de la misma clase son homogéneas, independientes e idénticamente distribuidas [10].
2. TEORÍA DE VALOR EXTREMO PARA EL RIESGO
Existe, bajo Basilea II, un conjunto de métodos cuantitativos para el cálculo de la carga de capital por riesgo operativo, pero no hay consenso sobre los mejores métodos a emplear. Una técnica que se ha vuelto potencialmente atractiva es la Teoría de Valor Extremo (EVT), la cual no parece ser directamente aplicable a satisfacer las estrictas normas establecidas por Basilea; esto se debe a que simplemente no hay suficientes datos.
Los métodos estándar de modelización matemática del riesgo utilizan el lenguaje de teoría de la probabilidad. Dichos riesgos son variables aleatorias que pueden ser consideradas individualmente o vistas como parte de un proceso estocástico. Los potenciales valores de una situación de riesgo tienen una distribución de probabilidad para las pérdidas derivadas de los riesgos, pero hay un tipo de información que está en la distribución, llamada eventos extremos, los cuales se producen cuando un riesgo toma valores en la cola derecha de la distribución de pérdidas.
En EVT hay dos tipos de enfoques que generalmente se aplican, los cuales se enuncian a continuación, [14].
a. El más tradicional es el modelo de bloques máximos (block–máxima); estos son modelos para grandes observaciones recolectadas a partir de grandes muestras de observaciones idénticamente distribuidas. Consiste fundamentalmente en partir las observaciones por bloques y en estos encontrar el máximo. Este método lleva a producir un error por la mala escogencia del tamaño de los bloques.
b. Un más moderno y poderoso grupo de modelos es aquel de exceso de umbral (thershold exceedances); estos son modelos para todo tamaño de observaciones que exceden algún nivel superior (high level), y son en general los más utilizados en aplicaciones prácticas debido a su uso–eficaz en el manejo de los valores extremos. Al igual que el método block–máxima, esté lleva a un error en la mala escogencia del umbral. Los métodos de umbrales son más flexibles que los métodos basados en el máximo anual porque toman primero todos los excedentes por arriba de un umbral, adecuadamente alto, y de esta manera se usan mucho más datos.
Como se expresa arriba, las grandes pérdidas por encima de un umbral establecido son difíciles de clasificar en el Acuerdo de Basilea II, no obstante, es posible identificar las características de la distribución de pérdidas y desarrollar un modelo de riesgo mediante la selección de una determinada distribución de probabilidad, la cual se puede estimar a través de análisis estadístico de datos empíricos. En este caso la EVT es una herramienta que trata de dar la mejor estimación posible de la zona de la cola de la distribución de pérdidas. Incluso en ausencia de datos históricos es útil, ya que puede corregir algunas deficiencias mediante la definición del comportamiento empírico de las pérdidas, basadas en el conocimiento preciso de la distribución asintótica de su comportamiento.
2.1 Teoría clásica de valores extremos
Las distribuciones de valores extremos surgen formalmente como distribuciones límite para el máximo o el mínimo de una secuencia de variables aleatorias.
Supongamos que X1, X2..., son variables aleatorias independientes e idénticamente distribuidas con función de distribución F, así:
 (3)
(3) Luego, para el máximo
La función de distribución, en teoría, viene dada por
Sin embargo, esto no es útil en la práctica porque la función de distribución F, por lo general, es desconocida. Una posibilidad es usar técnicas estadísticas estándar para estimar F del grupo de datos observados y luego sustituir este estimador en la ecuación (5); pero desafortunadamente un pequeño error en la estimación de F puede acarrear una discrepancia muy grande en Fn(z), sobre todo si n es grande.
Otro método alternativo es aceptar que F es desconocido y tratar de mirar la distribución aproximada que pueda tener Fn(z) que solo se puede estimar usando los datos extremos con una teoría análoga al teorema central del límite.
Sin embargo, para cualquier z < z+, donde z+ es el punto final superior de F, es decir, z+ es el valor más pequeño de z tal que F(z) = 1, se cumple que

Por lo que la función de distribución de Mn degenera en un punto de masa en z+. Para evitar esta dificultad, se renormaliza la variable Mn:

Usando secuencias de constantes {an > 0} y {bn} tales que:
 (6)
(6) La escogencia apropiada de {an > 0} y {bn} estabiliza la localización y escala de M*n cuando n incrementa, y así se evita la degeneración de M*n, como sucedía con Mn.
El rango completo de posibles distribuciones límites para M*n está dado por el teorema de los Tipos de Extremos [15]
2.1.1 Teorema [15]: Si existen secuencias {an > 0} y {bn}, tales que
 (7)
(7) para alguna distribución no degenerada G, entonces G pertenece solo a una de estas tres distribuciones:
 (8)
(8) (9)
(9) (10)
(10)Por el contrario, cada una de estas distribuciones pueden aparecer como límite de la distribución de

y en particular, esto sucede cuando G es la función de distribución de X.
Como se mencionó anteriormente, en EVT hay dos enfoques que se pueden aplicar a los datos de pérdida de una distribución de probabilidad. El primer enfoque se refiere a los máximos (o mínimos) valores que toma una variable en períodos sucesivos, por ejemplo, meses o años. Estas observaciones constituyen los fenómenos extremos, también llamado bloques (o por periodo) máximos. En el centro de este enfoque hay "tres tipos de teorema" [16], que afirman que sólo hay tres tipos de distribuciones que pueden plantearse como distribuciones límite (limiting distributions) de valores extremos en muestras aleatorias; dichas distribuciones son del tipo Weibull, Gumbel o Frechet. Este resultado es muy importante, ya que la distribución asintótica de los máximos siempre pertenece a una de estas tres distribuciones, independientemente de la distribución original. Por lo tanto, la mayoría de las distribuciones utilizadas en finanzas y en las ciencias actuariales puede dividirse en tres clases, en función de sus colas pesadas:
a) Distribuciones de colas delgadas (light–tail distributions). Con momentos finitos y colas que convergen a la curva de Weibull o Beta.
b) Distribuciones de colas medias (medium–tail distributions). Para todos los momentos finitos y cuya función de distribución acumulada disminuye exponencial en las colas, al igual que la curva de Gumbel, Normal, Gamma o LogNormal.
c) Distribuciones de colas gruesas (heavy–tail distributions). Cuyas funciones de distribución acumulada disminuyen con fuerza en las colas, al igual que la curva de Frechet , T de Student, Pareto, LogGamma o Cauchy.
Las distribuciones Weibull, Gumbel y Frechet pueden ser representadas en un modelo con tres parámetros, conocido como Generalized Extreme Value distribution (GEV):
 (11)
(11)Con 
En donde los parámetros corresponden a:
µ parámetro de posición
σ parámetro de escala
ξ: parámetro de forma ζ
El parámetro de forma indica el espesor de la cola de la distribución. Si el parámetro es grande, la cola de la distribución es más gruesa.
El segundo enfoque en EVT es el método llamado "Peaks Over Threshold (POT)", adaptado para el análisis de datos más grande que presentan umbrales altos.
El componente de severidad en el método POT se basa en una distribución (Generalised Pareto Distribution – GPD), cuya función de distribución acumulada es expresada por dos parámetros:
 (12)
(12)
Donde:
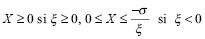
y ξ, σ son parámetros de forma y escala, respectivamente.
3. ANÁLISIS DE DATOS
Para la aplicación de las dos metodologías, los datos se obtuvieron de dos fuentes: la primera, la página de la Superfinanciera de Colombia en la cual aparecen registradas las quejas de los consumidores del sector financiero. Se procesaron las quejas mensuales de los últimos cinco años, para luego clasificarlas en los riesgos operativos que establece la circular externa 041 de 2007 de la Superfinanciera. La segunda fuente, una entidad financiera del sector cooperativo1, la cual aportó los datos de pérdidas económicas en los últimos cinco años para cada uno de los riesgos operativos en la línea de Banca minorista.
Se realizó un análisis exploratorio de los datos, con el fin de obtener información subyacente en los siete eventos de riesgo en la línea de negocio definida. En particular, debido a la conocida naturaleza del riesgo operativo, el análisis se centró en la evaluación de las medidas de asimetría, curtosis e índice de cola, medidas de posición y escala de la distribución de pérdidas.
Además, de explorar el conjunto datos de los siete eventos de riesgo en la línea de negocio, se aplicó el procedimiento del LDA para generar la distribución de pérdidas. Para cada casilla de la matriz se realizó una simulación con un millón de iteraciones en el programa @risk. El objetivo de este procedimiento es fortalecer el poder informativo de los datos sobre los momentos desconocidos de la población y, por otro lado, proporcionar una mayor protección de la confidencialidad de las pérdidas aportadas por la entidad financiera. Por último, se separaron el cuerpo de la distribución y la cola a partir del percentil 99.9% de la distribución de pérdidas.

Como se observa en la figura 1, la mayor concentración de eventos de riesgo se presentó en ejecución y administración de procesos: 15.587 eventos que representan el 40.67%, los clientes. Las fallas tecnológicas también presentaron frecuencias altas, aunque necesariamente esto no se traduce en montos económicos similares o proporcionales a la cantidad de eventos.

La figura 2 muestra que las mayores pérdidas económicas se presentaron por fraude externo, el 51.02%, y aunque esto representaba el 2.88% de los eventos en la tabla anterior, resultó más costoso para la entidad. Fallas tecnológicas y daños a activos físicos también presentaron pérdidas elevadas.
3.1 Pruebas de bondad de ajuste para datos
Para la frecuencia de los eventos de riesgo (tabla 1), se realizó un ajuste con dos de las distribuciones de probabilidad recomendadas por Shevchenko y Donnelly [13]: la distribución de Poisson y la Binomial Negativa; la prueba utilizada para el ajuste es la K–S con un alpha de 0.05.
Los resultados mostraron que en cuanto a los datos de frecuencias, no se puede aceptar como representativo el comportamiento propuesto, la distribución de Poisson, dado que su p–value bilateral fue muy inferior a 0.05 (se rechaza H0). En cambio, en cuanto al ajuste a la distribución binomial negativa, no se encuentra evidencia estadística para afirmar que los datos siguen otro comportamiento que el propuesto, dado el nivel de significancia (no se rechaza H0), excepto los activos fijos cuyo valor de p es inferior a 0.05.

Para la severidad se postularon tres distribuciones de probabilidad: la normal, Lognormal y Weibull; el estadístico de prueba fue el K–S con un alpha de 0.05.
Los resultados del ajuste (tabla 2) muestran que no se encontró evidencia estadística para afirmar que los datos siguen otro comportamiento que el propuesto. Dado el nivel de significancia, los datos de la severidad se ajustaron a las distribuciones de probabilidad propuestas. Cabe observar que los mejores ajustes están en la distribución normal a excepción de las variables fraude interno y activos fijos las cuales se ajustaron mejor a la distribución Weibull.

3.2 Elección de las mejores combinaciones para distribución de pérdida
La tabla 3 muestra las combinaciones que se utilizaron en el cálculo de la distribución de pérdidas, excepto en la variable activos fijos, en la cual se utilizó una distribución general para los eventos. Estas combinaciones se tomaron con base en los mejores estadísticos de prueba (K–S) en cada uno de los ajustes.
Para hacer la elección de la distribución de severidad que debe acompañar la distribución de frecuencia, se utilizó el mayor p–value de las distribuciones de severidad, como se muestra en la tabla 3.

3.3 Estimación de la distribución de pérdidas
La variable que se pretende modelar es la pérdida económica S; dicha variable se deriva de la combinación de la frecuencia de los eventos y la severidad en riesgo operacional. Para este propósito, dado que el modelo de ETV estudia el comportamiento de los extremos o eventos raros, es necesario aplicar a la variable aleatoria de estudio S, una metodología de manera que se obtengan resultados congruentes teóricamente.
Para el cálculo de S, se siguió el algoritmo propuesto por [6] realizando simulaciones de 1'000.000 de datos (figura 3).

Y se obtuvo el siguiente resultado para fraude interno:

Las estimaciones de los momentos empíricos indican que las distribuciones de pérdida de los siete eventos en la línea de negocio son muy sesgadas a la derecha y, sobre todo, presentan colas muy gruesas con respecto a una distribución normal. Con el fin de apreciar mejor las peculiaridades de estos datos, se pueden observar en la figura 4 los valores de la asimetría y la curtosis, las cuales son, respectivamente, 2.94 y 18.05. Lo anterior indica la presencia de pérdidas de baja frecuencia y alta severidad; este tipo curvas manifiestan la posibilidad de pérdidas catastróficas.

En la figura 5 se puede confirmar la presencia de colas gruesas.
3.4 Cálculo del estimador de Hill [17] ξ.
Este método [4],se emplea para estimar el parámetro característico (tabla 4) de la Distribución Generalizada de Pareto, teniendo en cuenta aquellos valores que exceden un determinado umbral. Para ello, se ha tomado como umbral el percentil 99.9% calculado en la distribución de pérdidas y definido por Basilea, para contar con una muestra de 1.000 observaciones en cada uno de los siete eventos de riesgo.
Como se observa en la tabla 4, el parámetro característico indica la presencia de colas gruesas; cabe anotar que las distribuciones de probabilidad que se encontraron en los datos de las colas son la Exponencial y la Beta General. La curtosis de los datos nos muestra de que las distribuciones de las colas son lectocúrticas y simétricas positivas. En riesgo operacional, la lectocurtosis implica una alta probabilidad de ocurrencia de una pérdida económica; lo interesante para este caso, por encontrase que las pérdidas están por encima del percentil 99.9%, esto las ubicaría en las pérdidas de baja frecuencia pero de alto impacto económico.

4. CONCLUSIONES
En la modelización de las pérdidas en la cola, hay que explorar algunos métodos para determinar cuál presenta un mejor comportamiento para la entidad en cuanto a la estimación de las pérdidas por encima de un umbral.
La modelización de las pérdidas que superan un umbral genera problemas de elección entre varianza y sesgo. Umbrales bajos suponen modelizaciones con mayor número de observaciones y, por tanto, minimizan la varianza aunque pueden incrementar el sesgo por tomar como muestra valores no extremos. Umbrales elevados reducen el sesgo pero generan modelizaciones con mayor varianza.
La elección del umbral puede ser una de las prioridades a la hora de aplicar el modelo de valor extremo; determinar el valor del umbral permite una modelización óptima, dado el efecto económico que produce en la entidad el tipo de cola que presente la distribución de pérdidas.
En la gestión del riesgo operacional, es importante un control efectivo sobre los eventos y las severidades, dado que el parámetro característico puede ser la manifestación de ausencia efectiva en el control de algunos riesgos. Esto se puede observar en el tipo de cola que presenta la distribución de pérdidas.
REFERENCIAS
1. M. González, "Análisis del nuevo acuerdo de capitales de basilea, pyme–risk, country–risk y operational–risk," 2004. [ Links ]
2. P. Fontnouvelle, J. Jordan, and E. Rosengren, "Implication of alternative operational risk modeling techniques," Federal Reserve Bank of Boston; FitchRisk, 2004, p. 45. [ Links ]
3. P. Fontnouvelle, V. DeJesus–Rueff, J. Jordan et al., "Using loss data to quantify operational risk," Federal Reserve Bank of Boston, 2003, p. 32. [ Links ]
4. R. Huisman, K. Koedijk, C. Kool et al., "Tail–index estimates in small samples," Journal of Business & Economic Statistics, vol. 19, no. 2, pp. 208–216, 2001. [ Links ]
5. I. Akkizidis, and V. Bouchereau, Guide to optimal operational risk & Basel II, Boca Ratón: Auerbach Publications, 2006. [ Links ]
6. M. Cruz, Modeling, measuring and hedging operational risk, New York: John Wiley & Sons, 2002. [ Links ]
7. M. Degen, P. Embrechts, and D. Lambrigger, "The quantitative modeling of operational risk: between g–and–h and EVT," http://www.actuaires.org/ASTIN/Colloquia/Orlando/Papers/Degen.pdf, 2006]. [ Links ]
8. K. Dutta, and J. Perry, "A tale of tails: an empirical analysis of loss distribution models for estimating operational risk capital," http://papers.ssrn.com/sol3/papers.cfm?abstract_id=918880, 2006]. [ Links ]
9. A. Frachot, P. Georges, and T. Roncalli, "Loss distribution approach for operational risk. Credit Lyonnais," http://papers.ssrn.com/sol3/papers.cfm?abstract_id=1032523, 2001]. [ Links ]
10. A. Frachot, O. Moudoulaud, M. Olivier et al., "Loss distribution approach in practice. Paris: Crédit Lyonnais," http://papers.ssrn.com/sol3/papers.cfm?abstract_id=1032592, 2003]. [ Links ]
11. C. Lee, Measuring and managing operational risk in financial institutions, New York: John Wiley & Sons, 2001. [ Links ]
12. J. Nešlehová, P. Embrechts, and V. Chavez, "Quantitative models for operational risk: extremes, dependence and aggregation," http://www.sciencedirect.com/science?_ob=ArticleURL&_udi=B6VCY–4JT3S3H–1&_user=10&_rdoc=1&_fmt=&_orig=search&_sort=d&_docanchor=&view=c&_searchStrId=996168640&_rerunOrigin=scholar.google&_acct=C000050221&_version=1&_urlVersion=0&_userid=10&md5=8dad51c73ac74104f9df8c9d3eb36841, 2005]. [ Links ]
13. P. Shevchenko, and J. Donnelly, "Validation of the operational risk LDA model for capital allocation and AMA accreditation under Basel II," CMIS Confidential report prepared for Basel II programme ANZ bank, 2005. [ Links ]
14. O. Velandia, "Comportamiento asintótico del var como medida de valor extremo," http://www.matematicas.unal.edu.co/academia/programas/documentos_tesis/1–2007/4.pdf, 2007]. [ Links ]
15. B. V. Gnedenko, "Sur la distribution limite du terme maximum d'une serie aleatoire," Annals of Mathematics, vol. 44, pp. 423–453, 1943. [ Links ]
16. R. A. Fisher, and L. H. C. Tippet, "Limiting forms of the frequency distribution of the largest or smallest member of a sample," Mathematical Proceedings of the Cambridge Philosophical Society, vol. 24, no. 2, pp. 180–190, 1928. [ Links ]
17. B. M. Hill, "A simple general approach to inference about the tail of a distribution," Annals of statistics, vol. 3, no. 5, pp. 1163–1174, 1975. [ Links ]
1 El nombre de la entidad se omite por compromisos de ética y confidencialidad.
Recibido: 31/08/2009
Aceptado: 05/10/2009

