











 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink1. Introduction
Currently, the amount de data produced globally is quite high. Companies, governments, universities, and - in general - all organizations produce data at large scale, related to their business. Said data is collected in big repositories, mainly in relational databases that permit structured storage of information. Added to these data, more information is generated daily from the biggest source of all: Internet. It produces millions of data due to the mass use of social networks, messaging services, blogs, wikis, and e-commerce, among others.
This amount of data has required much attention from the scientific community regarding to the production, processing, storage, retrieval, and extraction of information. Just the Web moves millions of non-structured data whose most effective sources are those that offer collaborative environments, like: wikis, social networks, messaging, blogs, and micro blogs among others. This whole range of data is attractive for different commercial, industrial, and academic entities, but extraction and its respective processing makes this task quite complex and difficult if done manually.
To confront this, it is necessary for the extraction, storage and processing of data to be automatic and it is where disciplines, like extraction of information, information retrieval, and natural language processing (NLP) techniques play an important role in managing these large volumes of non-structured data generated daily. The academic community has big work fronts from the vast amount of data from the Web. In it, regular people participate actively in different cloud tools by leaving their comments, opinions and even reviews on all types of themes, using their native language.
Added to this, computers are already starting to acquire the capacity of expressing and recognizing affection, and soon to will have the capacity of “having emotions” [1]. This is has been under construction since the emergence of affective computing, which seeks for computers to interpret the emotional state of humans and adapt to their behavior, providing them an adequate response to these emotions. This theme has received attention from researchers in information technology, especially in the field of analysis of emotions where progress has been achieved from the analysis of emotions based on facial expressions [2], recognition of emotions through sensors [3] to the identification of emotions in written texts [4].
The aforementioned would not have been possible without the constant search for new and better models, techniques, tools that allow computers to confront this challenge automatically. For example, one of the current trends in research related to affective computing is sentiment analysis (SA). Sentiment analysis seeks to analyze opinions, sentiments, judgments, attitudes, and emotions of people toward entities, like products, services, organizations, individuals, problems, events, themes, and their attributes [5].
This article sought to show the current state of this topic through a literature review, specifically, progress in the Spanish language. First, a complete review was conducted of SA in general, addressing the basic concepts of the theme. Thereafter, the methodology is discussed and then sentiment analysis in Spanish is addressed by showing the results found. Finally, the conclusions and recommendations are presented.
2. Sentiment analysis or opinion mining
2.1 Definition
In literature, SA receives different denominations or terms. Within these common terms, we find opinion mining, subjectivity analysis, emotion analysis, affective computing, and extraction of the evaluation, among others.
The most-often used in literature are sentiment analysis and opinion mining (OM). According to [6], these are two similar concepts that denote the same field of study, which itself can be considered a sub-field of subjectivity analysis. For [7], these have different origins; OM comes from the information retrieval community whose aim is to extract and elaborate opinions from users about products, films, or other entities.
Sentiment analysis, in turn, was formulated initially as a natural language processing (NLP) task of retrieval of sentiments expressed in texts. Reference [8] states that SA is an area of research in the field of text mining and defines it as the computational treatment of opinions, sentiments, and text subjectivity. Considering the aforementioned, it is noted that most of the terms used are quite similar. Thus, this proposal will address SA differently with OM as an area of NLP work for retrieval of texts, extraction of entities, analysis of opinions, polarity identification (positive or negative), la computational linguistics y all those additional characteristics that permit identifying and extracting subjective information and opinions from textual resources
2.2 Level
Three levels exist to analyze sentiments according to [8] and [9]: at document, phrase, and aspect levels. Analysis at document level classifies the sentiment of a whole document into positive or negative [6]. At phrase level, its objective is to classify the sentiment expressed in each sentence. Sentiment analysis at aspect level seeks to classify sentiment with respect to the specific characteristics of an entity found in each phrase. According to [9], both the document level and phrase level do not discover what it is that people like or do not like, contrary to SA at aspect level, which performs a more profound and detailed analysis. That is, instead of looking at language constructions (documents, paragraphs, sentences, clauses o phrases), SA at aspect level looks directly at the opinion expressed.
2.3 Application
Sentiment analysis is widely used in companies for reputation analysis, that is, how are the organizations positioned in the market according to their clients’ opinions in social networks. For this, they use social networks, like Twitter and Facebook as sources to review written texts in form of comments, which contain opinions about their registered brand. This literature review found different types of works framed within different applications; in tourism [10] [11], movie reviews [12] [13], sports [14] politics [15] [16] education[17], health[18], finance[19], and opinion reviews on automobiles[20].
4. Steps to perform a sentiment analysis system
According to [6], the goal of an SA system is extraction and classification of the sentiment. Diverse forms of focusing SA exist in literature: [5] [6] [7] [8] [21], and[22]; some are more common than others are. The majority of systems created in literature adopt this series of steps (Figure 1):

Extract the information or opinion from a data set,
Apply natural language processing techniques, like pre-processing to reduce data noise,
Identify the sentiments by locating the characteristics present in the data
Classify the sentiment within a polarity scale (positive or negative).
The following describe the last three steps.
2.4.1 Pre-processing
According to [23], pre-processing techniques consist of a text cleaning and preparation process prior to classification. On-line texts generally contain much noise and parts with limited information, like HTML tags, scripts, and notices.
A new trend exists in research on the use of NLP as a preprocessing stage prior to the analysis of sentiments [8]. Different works have been specifically dedicated to this area [23] [24], and [25], which considers that a data preprocessing step is important in sentiment analysis and that with the appropriate selection of techniques, classification precision can be improved.
What takes place in this pre-text processing is, basically, identification of spelling errors, elimination of arbitrary sequences of spaces, stop words, detection of phrase limits, elimination of arbitrary use of punctuation marks, and capitalization among others.
For example, [26] applies different types of pre-processing of NLP in tasks, like: spelling errors, normalization, segmentation, stop words, lemmatization, and name recognition, among others.
2.4.2 Selection of characteristics
Identifying sentiments is a task of great importance for SA; due to this, many works focus only on identifying sentiments, that is, on selecting characteristics or location in the text of words or phrases that indicate a possible sentiment. For [6], converting a portion of text into a vector of characteristics or another type of representation enables its more outstanding and important traits to be available for data-based systems for text processing. This task comes after data cleaning and seeks to identify where the sentiment is. To address this problem, literature has used distinct approaches [5] [8] [22], like use of terms of presence and frequency, parts of speech (POS), use of opinion words and phrases, and use of denial. In addition, rules [27], syntactic dependence [28], and generic algorithms [29] are used, among others.
2.4.3 Classification of sentiments
Classification of sentiments (CS) is the task of offering a positive or negative judgment to a comment, opinion, phrase, or document. This task is also known as classification of polarity or as classification of the sentiment of polarity [6]. This is no more than assigning a positive, negative, or neutral value to an opinion. Generally, in literature we find two big approaches for classification of sentiments, according to [7] [8] [30]: based on machine learning and based on lexicon.
For the first approach, a subdivision is made into supervised learning and unsupervised learning. For the lexicon-based approach, it is subdivided based on corpus and based on dictionaries.
The fundamental differences lie in that the first uses algorithms or strategies to learn from texts or determined corpus and the second model uses dictionaries, lexicons and corpus of words, phrases, or their combination already catalogued with some sentiment.
For a perspective on the research according to the approach used in the literature reviewed, Figure 2 shows the behavior for each of these, finding machine-based learning with 47% and lexicon-based with 32%. This means that works on machine learning are still used frequently in the last six years.

Many types of classifiers exist in literature based on machine learning, like: those based on support vector machines (SVM)[14][29] [31] [32] [33] [34] Bayesian classifier [35] [36] [37], neural network [16] [38] and those combining several approaches [16] [38]. With regard to works based on a dictionary or corpus, the following are found: [39][40] [41] [42] [43] and[44]. In addition, some works are focused on creating, modifying, or improving lexicons for sentiment analysis in different languages [45] [46] [47] [48], and[49].
Of the two approaches presented (Table 1), machine learning techniques have proven extremely useful, not only in the field of sentiment analysis, but also in most text mining and information retrieval applications. In turn, lexicon-based approach is different from approaches based on machine learning in that these are based on lexicon resources generated previously and that store information on the polarity of the elements, which are then identified in the texts and are assigned a polarity. These lexicon-based systems have an advantage over the others by not requiring a training set. Using a given approach will depend on the type of text analysis that will be conducted and if we have training data or sentiment lexicons available. The hybrid approach strategy is also an excellent option.
2.5 Evaluation metrics for sentiment analysis systems
Evaluation of these types of systems is conducted from a set of metrics already defined, within which we find the classic performance measurements: precision, recall, and F-score. Precision is the number of positive examples classified correctly divided by the number of examples labeled by the system as positive. Recall is the number of positive examples classified correctly divided by the number of positive examples in the data [50]. The last serves to correct the distance error in cases where recall and precision are compensated [51]. Table 2 shows the measurements that depend on confusion matrix in Table 3.
Table 2 Performance measurements for CS systems
| Measurement | Formula |
|---|---|
| Precision | tp/(tp+fp) |
| Recall | tp/(tp+fn) |
| F-score | (B2 +1)tp /((B2+1)tp+B2fn+fp) |
Taken from[52]
Table 3 Confusion matrix
| Class | Classified as pos | Classified as neg |
| pos | True positive (tp) | False negative(fn) |
| neg | False positive (fp) | True negative (tn) |
Taken from [52]
3. Methodology
To carry out the review, 32 articles were used focused on themes related to sentiment analysis in the Spanish language. The following base references were chosen: [10] [13] [31] [33] [39] [47] [48] [49] [53] [54] [55] [56] [57] [58] [59] [60] [61] [62] [63] [64] [65] [66] [67] [68] [69] [70] [71] [72] [73] [74] [75] and [76].
Table 4 illustrates a summary of the articles reviewed. The table has six columns. The first shows the article reference and the second column, the year of publication. The third column shows the type of text as AC, which is a scientific article, and ACTA, which is the result of a scientific event. The fourth column has the data set on which the SA is performed. The following column displays the technique used for the classification, which can be based on LEX (lexicon), ML (machine learning), HI (hybrid), OTHER and NA (not applicable). The last column presents the level of analysis that can be document, aspect, phrase and not applicable.

4. Results and Discussion
Based on the review, some interesting contributions have been found in literature and which are addressed below.
With respect to works on SA under the LEX approach, we found: [49] proposes a new resource for the Spanish research community in sentiment analysis, which generates a new lexicon when translating into Spanish an existing lexicon in English; to evaluate the validity of the lexicon, a series of experiments is proposed. In [61], the authors analyze the opinions of hotel users by employing a system known as Sentitext that permits a sentiment analysis system independent of the domain. In [10], although its focus is not computational, analysis is performed of the relations that exist among image, knowledge, brand loyalty, brand quality, and customer value measured through the opinions of tourists in the Trip Advisor virtual community. Reference [39] proposes a method to quantify a user’s interest in a theme (at global level) by using SA techniques in Spanish in Twitter. Said work develops a tool called Tom that uses a lexicon created semi-automatically by translating from an existing lexicon in English.
With respect to the contributions in SA under ML approach, we find that reference [13] addresses the use of meta-classifiers that combine supervised and unsupervised learning to develop a polarity classification system. This proposal uses a Spanish corpus (Muchocine) of movie reviews along with its parallel corpus translated into English. Reference [33] exposes how to combine supervised machine learning algorithms and unsupervised learning techniques for automatic detection of different opinion trends. The proposal has been tested in real textual data available from the comments introduced in a weblog connected to administrative issues in a public education institution.
In addition, the work shows the potential of SA for public organizations and governments to obtain valuable knowledge of opinion trends. Reference [66] presents experiments to study the efficiency of classifying opinions into five categories: very positive, very negative, positive, negative and neutral by using the combination of the psychological and linguistic characteristics of LIWC. LIWC is an analysis software that permits extracting different psychological and linguistic characteristics of text in natural language.
Another modality worked in SA in Spanish is to combine LEX and ML techniques. Reference [70] introduces a hybrid approach that uses a lexicon of words tagged according to their polarity, besides automatic learning. The lexicon is generated automatically from a tagged corpus, and a score is assigned to each term from the text for each polarity.
With respect to Table 4, concerning the data source, it is shown that in most works Twitter appears with 60%. This is largely due to the NLP community in Spain [26] that has permitted confronting these new challenges by proposing new challenges for SA in Spanish, like [31] [53] [54] [55] [56] [60] [64] and [67].
With regard to the classification techniques used, it was found that: 42% of the works use lexicon techniques, followed by machine learning with 35%, while hybrid techniques were used in 15% of the works; finally, 8% of the works used another classification technique (Figure 3).
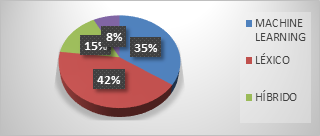
Paradoxically, the works in Spanish use mostly classification techniques with lexicon, although resources and research are still insufficient in this language [8], compared to the rest of the works in other languages, which mostly use machine learning techniques.
Undoubtedly, linguistic resources used in Spanish for SA tasks are scarce. Some do exist, like Sentitext, which has been tested in some SA systems, like [61] and [65], but which is still incomplete because it has some deficiencies in the process of determining polarities, specifically in the middle of the scale (N) and in the very positive (P++) scale. However, some resources exist - as shown in Table 4, which can be a good basis for SA works in Spanish.

In synthesis, with regard to the classification of sentiments in Spanish, most often traditional techniques are used, like machine learning (ML) and those based on lexicon (LEX). However, LEX techniques tend to lose the battle against ML techniques because they depend largely on quality linguistic resources, especially dictionaries of sentiments [8]. Supervised ML techniques achieve more reasonable efficiency, but the construction of tagging data, that is opinions with sentiment associated, is costly and needs much human work [79]. Contrary to the aforementioned, ML techniques of unsupervised learning do not require tagged training data and can be applicable to other languages and/or domains [27]
With respect to the level of analysis, it was found that most, with 77%, conduct the analysis at document level; the remaining 23% corresponds to 15% at aspect level or characteristic and 8% at phrase level, as noted in Figure 4.

According to the prior result, the big difference is seen between the types of analyses performed. Although SA at document level provides a total perspective of that expressed in the opinion, a more detailed analysis is required to extract the most important characteristics of that addressed and find its respective sentiment. It is clear that the quality and rigor of an SA at aspect levels is more complex and difficult.
With regard to the use of SA, it was found that it is widely used in companies to conduct reputation analysis, that is, how the organizations are positioned in the market according the opinions of their customers in social networks. For this, social networks, like Twitter and Facebook were used as sources to review written texts in form of comments that contain opinions about their brand. Besides these, those Web sites where on-line opinions are found, like Trip Advisor and MuchoCine, are in good use.
5. Conclusions
This article presents a review in the area of sentiment analysis on contributions made in Spanish since 2012 to 2015. It shows the distinct approaches, levels, data set, and techniques used until now for SA in Spanish.
Initially, it was found that the current state of research on SA in Spanish is scarce compared to other languages, like English. This is probably due to the large amount of linguistic resources existing in this language. From the works reviewed, a large amount of them use these resources in English for their SA systems through automatic translation.
Regarding the techniques used for classification, in SA these are practically distributed between LEX and ML, with a slight advantage of works under the LEX approach, which is somewhat strange due to the scarcity of resources in Spanish.
With respect to the level of analysis, it was found that the vast majority performs it at document level in comparison to aspect level. This is inconvenient when the texts have diverse characteristics with distinct polarities of a product. Hence, new proposals are needed, focused on conducting SA at aspect level, which permit retrieving essential characteristics of a complete document and, thus, perform a more detailed and precise analysis of a product or service.
As a final recommendation, from this article’s reflexion, further efforts are encouraged for research on SA in Spanish to potentiate existing linguistic resources. This will permit the construction of new general-purpose models that can analyze different types of written texts with high precision levels.

