











 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
1. Introduction
The personality model developed by H. J. Eysenck is one of the most fruitful models with empirical support and continues eliciting a large research corpus Bowden et al., 2018; (Revelle, 2016). Eysenck argued that three main personality dimensions (neuroticism ENT#091;NENT#093;, extraver sion ENT#091;EENT#093;, and psychoticism ENT#091;PENT#093;) could capture most of the variance of the personality (Eysenck & Eysenck, 1975). Eysenck developed different measurement instruments to precisely assess his personality model following this model. Although the first antecedents of PEN model measures can be found since the early 1950s (Eysenck, 1952, 1958, 1959; Eysenck & Eysenck, 1964), the in clusion of the P scale was not made until 1975 in the Eysenck Personality Questionnaire (EPQ; Eysenck & Eysenck, 1975). Nevertheless, the poor psychometric properties of the P dimension were hardly criticized, and a revised version of the EPQ (EPQ-R; Eysenck et al., 1985) was developed.
As Maragakis (2020) pointed out, the evolution to the EPQ-R is characterized by an increasing number of items (100 in the EPQ-R). This progressive increase in the length of instruments can be accounted for by the introduction of an additional dimension of person ality (P dimension) and by the psychometric principle that greater length enhances reliability. However, this increase in the length of the EPQ-R also made it barely useful for applied research and clinical settings (Maragakis, 2020). For example, it is usual that a research project would benefit from including a personality mea sure, but an additional 100 items would increase the overall questionnaire to an unacceptable length, which in turn would increase the fatigue, frustration, and bore dom of participants (Villarejo & Puertas-Martín, 2011; Gosling et al., 2003).
To overcome these limitations, brief or short ver sions of the EPQ were created to obtain a valid, reli able, and easy-to-apply personality measure instrument: the EPQ-R Short (EPQ-RS; Eysenck & Eysenck, 1991). The EPQ-RS was originally composed of 48 items (twelve for each dimension of the PEN model and twelve for sin cerity or Lie scale ENT#091;LENT#093;), making it easier to use because of the lower time required for its application and inherent lower cognitive demand for participants. Despite the de creasing item numbers and doubts about the psychome tric properties (Maragakis, 2020), different researchers have pointed out the appropriateness of the scale, but with some limitations in the P dimension (e.g., Alexopoulos & Kalaitzidis, 2004; Francis et al., 2006; Tiwari et al., 2009). In the same way, the efforts to develop brief and valid versions of the EPQ-R continued, and a briefer version of 24 items was also proposed (six for each dimen sion of the PEN model and six for L): The Abbreviated form of the EPQ-R (EPQ-RA; Francis et al., 1992). As in previous versions, all the dimensions of the EPQ-RA, except the P dimension, showed acceptable-to-good re liabilities, and it has been proposed as equivalent to the EPQ-RS (Bouvard, 2010; Francis et al., 1992; Ibáñez et al., 1999; Karanci et al., 2007) despite the lower number of items.
1.1 The Spanish context
As in many other contexts, the PEN model has also pro moted a large research corpus in the Spanish context, and different researchers have aimed to test the psycho metric properties of the EPQ-RA to obtain an appro priate personality measure instrument for this context (e.g., García-González et al., 2021; Ibáñez et al., 1999; Sandín et al., 2002a, 2002b; Vázquez et al., 2019) From these attempts, two Spanish versions of the EPQ-RA have been proposed by Ibáñez et al. (1999) and Sandin et al. (2002a, 2002b), with the general tendency to select the second version.
The version of the EPQ-RA proposed by Sandin et al. (2002a, 2002 b) is an adaptation of the version of Francis et al. (1992). Following this approach, Sandin et al. (2002a) analyzed the structure of the EPQ-RA through principal component analyses using the data of 263 university students. These authors identified four dimensions of P, E, N, and L, but indicated low factor weights in the P dimension and thus poor identification of the dimension. To obtain a more robust structure, the authors replaced two items of P dimensions present in the original EPQ-RA with another two items of the EPQ based on theoretical criteria. Using this modified version, Sandin et al. (2002b) redid the analyses using the data of another 199 university students and obtained similar results. Regarding the reliability of the dimen sions, they were only calculated for the slightly modified version, obtaining low to acceptable indexes (ap = .63; a E = .74; a N = .78; a L = .54).
Nevertheless, recent research has shown barely ac ceptable fitting of the model even when the P dimension was omitted (see García-González et al., 2021; Vázquez et al., 2019). These results are congruent with previous research, indicating the potential limitations of ignoring cultural influence on personality measurement. Differ ent researchers have indicated that some of the origi nal items considered appropriate in the United King dom were not appropriate in other contexts (Eysenck & Barrett, 2013), emphasizing the potential lack of cross- cultural invariance of the model (Dong & Dumas, 2020; McLarnon & Romero, 2020). Considering the potential cultural bias of the measurement instrument, Ibáñez et al. (1999) developed the Spanish version of the EPQ-RA from the EPQ-R, instead of adapting English EPQ-RA. Using the data of 1269 participants aged between 16 and 73 years and applying empirical (exploratory factor analysis and item discrimination) and theoretical (item content analysis) criteria, Ibáñez et al. (1999) proposed a 24-item (six per dimension) EPQ-RA from the Span ish EPQ-R (Ortet et al., 1999). This version has the same number of items, but it differed from the version proposed by Francis et al. (1992), adapted by Sandin et al. (2002a), 2002b), in the items composing each dimen sion: only 13 of the 24 are equal (one for P, three for E, four for N, and five for L). The authors obtained good reliability indexes for N (a = .77), E (a = .83), and L (a = .81), higher than other studies for P (a = .62) (e.g., Francis et al., 1992, 2006), and generally higher than Sandin et al. (2002a, 2002b).
1.2 Reconsidering the role of the lie dimension
The low reliability of the P dimension is not a unique problem related to the EPQs and their validation. Twen ty-five percent of the items are oriented for measuring sincerity (Lie ENT#091;LENT#093; scale) but not personality. The L scale has been traditionally ignored or questionably included in the PEN model. This scale was originally added not as part of the personality model but as a measure of the untrusty response style of the participants, as far as this dimension measures the tendency to participants to deceive (Eysenck & Eysenck, 1964) and thus as a social desirability measure. In this line, it has also been de fined as a measure of symptom minimization (Bowden et al., 2018) At this point, a question about the place of the L scale inside the PEN mo del arises. It has some times been omitted when testing the model (e.g., Sato, 2005; Shevlin et al., 2002), and other times, it has been included as another dimension of the PEN model, cre ating a four-factor model (e.g., Colledani et al., 2019; Vázquez et al., 2019). Nevertheless, to the best of our knowledge, the L scale has not been used before as a control for testing the PEN model.
It is usual in applied research and clinical settings to use measures of potential bias responses such as so cial desirability. The purpose of the researchers is to know when the participants are responding sincerely and exclude the data of participants who give untrusty re sponses. In other cases, these kinds of measures are not used to exclude cases but to control the responses, and they are included as covariables. Undoubtedly, this point represents the limitations that are still present in the validation of the PEN model. As Bowden et al. (2018) pointed out, there is still the necessity to use mod ern factor analytic techniques for further validations of the instruments, which can include the consideration of covariables in the estimation of the PEN model.
1.3 The current research
The current research aimed to analyze the factor va lidity and reliability of the Spanish EPQ-RA proposed in the Spanish young-adult population. As mentioned above, the EPQ-RA proposed by Ibáñez et al. (1999) is unique and has taken into account the cultural influ ence in its development as far as it was developed from the EPQ-RA based on Spanish participants’ responses. Nevertheless, the validity and reliability of this EPQ- RA version have been less studied due to the general tendency to use the version of Francis et al. (1992), adapted by Sandin et al. (2002a, 2002b) to the Span ish population. Unfortunately, the version proposed by them has shown significant limitations and did not show good psychometric properties (e.g., García-González et al., 2021; Vázquez et al., 2019), and the loss of inappro priate items has been a significant limitation due to the low number of items.
The current research also includes innovation in the analysis of the PEN measurement model by including the L scale as a covariable and thus controlling the ef fect of potential response bias instead of including it as the fourth personality dimension or even ignoring it. As mentioned above, the inclusion of the L scale implies a theoretical and practical problem. Although the di mension was originally thought of as a (in)sincerity mea sure, it has been included as the fourth personality trait. Nonetheless, it has also been proposed to omit it for the model considering that in case of necessity, other social desirability scales could be used with the EPQ (Sato, 2005). The inclusion of other sincerity indexes (e.g., so cial desirability) in applied research is made to control biased responses, so following this premise and the rec ommendation of Sato (2005), it was considered more appropriate to use the L scale for control proposals.
Considering all these limitations, the current research aimed to test the validity and reliability of an alterna tive version proposed by Ibáñez et al. (1999) through the following specific aims: (1) test the fitting of the two-correlated dimensions (N-E) and one orthogonal di mension (P) model, three-correlated dimensions model, and two-correlated dimension model (N-E) fitting to the data; (2) analyze the configural, metric, and scalar invariance of the best-fitted model across sexes (male female); (3) estimate the reliability of the neuroticism, extraversion, psychoticism dimensions; and (4) examine the sex differences.
2. Method
2.1 Participants
The sample included 2962 young adult participants, aged 18 to 26 years old (M = 19.63, SD = 1.77). A total of 63.2% (n = 1872) were women and 36.8% (n = 1090) were men. The majority of participants perceived them selves as middle socioeconomic level 94.9% (n = 2796) and only 5.1% (n = 150) perceived belonging to the low (3%, n = 89) or high (2.1%, n = 61) socioeconomic levels. Participants belonged to five categories regarding their educational level: 39.7% (n = 1171) were university stu dents, 16.9% (n = 498) were higher education students, 20% (n = 591) were vocational education and training students, 20.7% (n = 612) were GCE students, and 2.6% (n = 78) were students from GCSE.
2.2 Measures
The present study was conducted using the Spanish Ab breviated version of the Eysenck Personality Question naire-Revised (EPQ-RA; Ibáñez et al., 1999). This is a 24-item inventory consisting of four subscales of six items each. Three of these four subscales are personal ity dimensions: extraversion (E) -assess positive emo tivity, sociability, spontaneity, vitality, and surgent-, neuroticism (N) -includes negative emotivity, anxiety, sensibility, concern, and self-awareness-, and psychoticism (P) -aggressive, impulsivity, low socialization, non conformity, irresponsibility, and schizoids or antisocial behavior-. The fourth scale is the relative to Lie (L) to validate the test. The questionnaire was scored on a dichotomic response format of 0 (= No) and 1 (= Yes). The scores were summed to obtain the score of each di mension, which ranged from 0 to 6, indicating lower and higher levels of each personality trait.
2.3 Procedure
The data used in the current research are the product of a broader research project: authors were invited to take part in the study to previous collaborators of dif ferent Spanish provinces who shared the questionnaire in educational centers based in La Coruña, Pontevedra, and Principado de Asturias in the north and Huelva and Sevilla in the south. The final sample consists of data collected from educational centers that agreed to partic ipate in the research. The study employed convenience sampling approach, as participants were selected based on their accessibility and willingness to take part in the research. Prior to data collection, all participants re ceived comprehensive information about the research ob jectives and the assurance of data collection and analysis anonymity. Additionally, participants were explicitly in formed of their right to withdraw from the study at any point without facing penalties or consequences. Before responding to the questionnaire, participants were re quired to provide informed consent for the use of their data in various research proposals.
2.4 Statistical Analyses
Confirmatory factor analysis (CFA) was carried out to test the fitting of different models to the data. First, the model proposed by Eysenck (1952) of three dimen sions with neuroticism and extraversion correlated and psychoticism independent (model 1) was tested. Second, the generally tested mo del of four correlated factors, in cluding the L scale (model 2), was tested. Third, an alternative mo del with the three dimensions correlated (model 3) was estimated. Fourth and finally, an alterna tive model of two correlated factors of neuroticism and extraversion (model 4) was tested. Models 1, 3 and 4 were estimated controlling for the L score, including it as a covariable. The x 2 statistic, the comparative fit in dex (CFI > .95), and root mean square error of approxi mation (RMSEA < .05) and its 90% confidence interval (CI) were considered to test the assessment of the model to the data (Hu & Bentler, 1999). Once the best-fitting model was obtained, multiple-group analyses were car ried out to assess the invariance of the model across sexes (male and female). Three invariance configura tions were tested: configural, metric, and scalar. Con- figural invariance refers to the invariance of mo del form and means that the organization of the tested constructs is supported in both sexes. Metric invariance refers to the contribution of the items to the latent construct, and it is obtained if these contributions are similar in both sexes. Finally, scalar invariance means that differences in the latent construct capture all mean differences in the shared variance of the items. The △ x 2 test and its associated probability, △CFI (< .010) and △RMSEA (< .015), were considered to test the invariance across groups (Rutkowski & Svetina, 2017; Svetina et al., 2019). All estimations were carried out using the weighted least squares mean and variance adjusted (WLSMV) estima tor with MPlus 8.6 software (Muthén & Muthén, 1998, 2021). Theta parameterization for multigroup analysis was also used. Considering that when the item response scale is ordinal, the tendency of coefficients based on the covariance matrix to underestimate the real reliability was estimated based on the polychoric correlation ma trix (Dueber, 2017; Elosua & Zumbo, 2008; Gadermann et al., 2012; Viladrich et al., 2017). Finally, the differ ences between males’ and females’ scores on P, E, and N were tested. Multivariate analysis of covariance (MAN- COVA) included the L score as a covariable. Although the differences in the three dimensions are usually tested by using a series of t tests, the MANCOVA allows us to test multiple related independent variables, better con trolling the type I error and better accounting for the related nature of the P, E, and N dimensions. Effect sizes were examined using partial eta squared (n2), con sidering effect sizes between .01 and .059 small, between .60 and .13 medium and equal or higher than .14 large. The IBM SPSS 22 was used for these analyses.
3. Results
Confirmatory factor analysis of the measurement model. The results displayed in Table 1 show poor fitting for model 1 (P independent and E N correlated) and model 2 (four correlated factors) and barely acceptable fitting of model 3 (P E N correlated and L covariable) and model 4 (P E correlated and L covariable).
A deep analysis of the results revealed some particu lar and common potential modifications that could im prove the model fitting. Regarding the common limi tations of the models, item 5 did not significantly load on the E dimension in any model, and freely estimating the covariation among items 14 and 22 of the N dimen sions would significantly improve the model. Additionnally, item 15 showed extremely low factor loading (< .10) for the P dimension in models 1 to 3 (the P dimension was not present in model 4), 19 did not significantly load (p > .05) on the P dimension for models 2 and 3, and its factor weight was significant but extremely low (< .10) in model 1 (the P dimension was not present in model 4). Finally, the results of model 1 also show the necessity of considering the relation of P with N and E.
Table 1 Fitting indexes of the 1 to 4 measurement models with L covariable
| Model | X2 (df) | P | CFI | RMSEA ENT#091;90% C.I.ENT#093; |
|---|---|---|---|---|
| P independent and E N correlated | 1114.705 (134) | ≤ .001 | .874 | .050 ENT#091;.047,.052ENT#093; |
| P, E, N, and L correlated | 2362.360 (149) | ≤ .001 | .802 | .050 ENT#091;.052,.056ENT#093; |
| P, E, and N correlated | 793.270 (132) | ≤ .001 | .915 | .041 ENT#091;.038,.044ENT#093; |
| E N correlated | 510.149 (53) | ≤ .001 | .933 | .054 ENT#091;.050,.058ENT#093; |
Note. Only 1, 3 and 4 included L as covariable. The fourth model included the L dimension as the fourth correlated dimension.
Table 2 Standardized effects of L on P, E, and N dimensions’ items
| Covariable L | |||
|---|---|---|---|
| Item | Model 1 | Model 3 | Model 4 |
| P | |||
| 3 | .010*** | .010*** | N/A |
| 7 | .032* | .032* | N/A |
| 11 | .003 | .004 | N/A |
| 15 | -.025 | -.025 | N/A |
| 19 | -.067*** | -.067*** | N/A |
| 23 | -.012 | -.012 | N/A |
| E | |||
| 1 | .029 | .029 | .039 |
| 5 | -.114*** | -.114*** | -.181*** |
| 9 | .034 | .034 | .035 |
| 13 | .050* | .050* | .057* |
| 17 | -.025 | -.026 | -.039 |
| 21 | .019 | .019 | .017 |
| N | |||
| 2 | -.083*** | -.083*** | -.081*** |
| 6 | -.083*** | -.082*** | -.095*** |
| 10 | -.062*** | -.062*** | -.075*** |
| 14 | -.020 | -.020 | -.028 |
| 18 | -.035 | -.035 | -.037 |
| 22 | -.045* | -.045* | -.057* |
Table 3 Fitting indexes of the 1 to 4 modified measurement models
| Model | X2(df) | p | CFI | RMSEA ENT#091;90% C.I.ENT#093; |
| 1.A. P independent and E N correlated | 658.425 (88) | ≤ .001 | .924 | .047 ENT#091;.043,.050ENT#093; |
| 1.B. P / EN without L covariable | 654.571 (88) | ≤ .001 | .924 | .047 ENT#091;.043,.050ENT#093; |
| 2. P, E, N, and L correlated | 1170.354 (182) | ≤ .001 | .901 | .043 ENT#091;.040,.045ENT#093; |
| 3.A. P, E, and N correlated | 280.178 (86) | ≤ .001 | .974 | .028 ENT#091;.024, .031ENT#093; |
| 3.B. PEN without L covariable | 280.204 (86) | ≤ .001 | .974 | .028 ENT#091;.024,.031ENT#093; |
| 4.A. E N correlated | 133.901 (42) | ≤ .001 | .986 | .030 ENT#091;.022,.032ENT#093; |
| 4.B. EN without L covariable | 135.242 (42) | ≤ .001 | .986 | .027 ENT#091;.022,.033ENT#093; |
Table 4 Set of models to test configural, metric, and scalar invariance of models 3 and 4 across females and males omitting the L covariable
| X 2( df) | p | △ X 2(A df) | p | CFI | △CFI | RMSEA (C.I.) | △RMSEA | |
| Model 3 - PEN | ||||||||
| Configural | 409.616 (172) | ≤ .001 | N/A | N/A | .968 | N/A | .031 (.027,.034) | N/A |
| WOM | 185.713 | |||||||
| MEN | 223.902 | |||||||
| Metric | 406.210 (185) | ≤ .001 | 10.014 (13) | .693 | .970 | .002 | .028 (.025,.032) | .003 |
| WOM | 182.212 | |||||||
| MEN | 223.998 | |||||||
| Scalar | 534.501 | ≤ .001 | 151.269 (12) | ≤ .001 | .954 | .016 | .034 (.031,.037) | .006 |
| WOM | 218.199 | |||||||
| MEN | 273.899 | |||||||
| Model 4 - EN | ||||||||
| Configural | 197.159 (84) | ≤ .001 | N/A | N/A | .983 | N/A | .030 (.025,.036) | N/A |
| WOM | 101.357 | |||||||
| MEN | 95.802 | |||||||
| Metric | 194.751 (94) | ≤ .001 | 6.548 (10) | .767 | .985 | .002 | .027 (.022,.032) | .003 |
| WOM | 98.351 | |||||||
| MEN | 96.400 | |||||||
| Scalar | 302.908 (103) | ≤ .001 | (9) | ≤ .001 | .970 | .015 | .036 (.036,.041) | .009 |
| WOM | 127.298 | |||||||
| MEN | 139.444 | |||||||
Note. *p < .05; **p < .01; ***p < .001.
The effects of the L covariable on the items for each model (except model 2, where L is the fourth dimension) are displayed in Table 2. As seen, there is no signifi cant effect on all the items, but there are some items significantly affected by social desirability, with the N dimension being the more affected.
Considering the results obtained in the first analyses and the transversality through different models of the same limitations, items 5 (E), 15 (P) and 19 (P) were omitted, and the covariation between items 14 (N) and 22 (N) was freely estimated. Additionally, based on the poor effect of the L covariable, the models were also tested omitting the covariable. After the modifications, all the models improved their fitting to the data, but differentially. Model 1 still showed poor fitting to the data, while model 3 was equivalent to model 1, although including the correlation between the P dimension and the E and N dimensions showed good fitting to the data. Model 2 of the four correlated dimensions also improved. The fitting, however, was barely acceptable. Finally, model 4 of two correlated dimensions showed, as model 3, good fitting to the data.
Regarding the L covariable, the fitting of the models with and without the covariable L did not differ signifi cantly, so the subsequent analyses were carried out con sidering the L covariable because of its significant effect on some items, but also omitting the L covariable due to the higher parsimony of the model. This decision was made considering the potential influence of social desirability bias on invariance.
As seen, only models 3 (three correlated dimensions: P E N) and 4 (two correlated dimensions: E N) showed good fitting to the data. Considering previous results, only these two models were considered for further anal yses. Standardized factor loadings of models 3 with (A) and without covariables (B) and 4 with (C) and without covariables (D) are displayed in Figure 1.
Sex invariance. After the best-fitting model was ob tained for models 3 and 4, multigroup analyses were car ried out to determine the configural, metric, and scalar invariance across sexes. Considering the higher parsi mony of the models without covariables, the invariance of models B and D was tested first. As seen in Table 3, configural and metric invariance can be assumed in both models. In contrast, the scalar model seems to be sig nificantly worse. Despite the practical fit indexes (CFI and RMSEA) indicating good fitting of the model to the data, the ACFI (> .010) indicates poor invariance across sexes for both models.
Table 4 shows goodness-of-fit indexes for the mod els and their differences from the baseline (configural) model. Contrary to previous findings omitting the co-variable, configural, metric, and scalar invariance can be assumed in both models. Configural and metric in variance are clear, and although the scalar model seems to be significantly worse, the practical fit indexes (CFI and RMSEA) were similar. Briefly, the differences in practical fit indexes were minimal: less than .01 for the CFI, which is considered the most severe criterion. In this regard, the EPQ-RA can be considered equivalent for females and males.
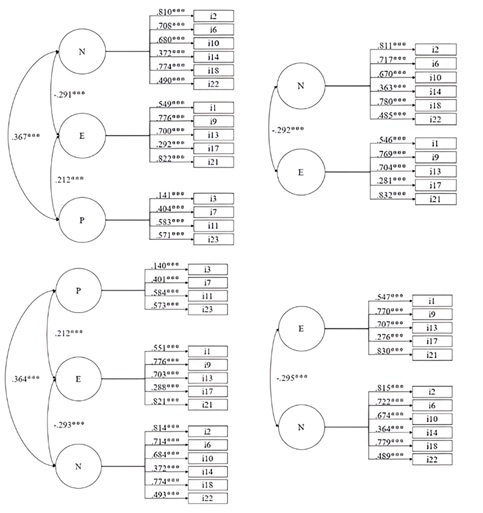
Note. ***p ≤ .001. The covariable (Figures A and C) and covariation between items 14 and 22 were omitted in the Figure for simplification.
Figure 1 Standardized factor loadings for models 3 and 4 with and without covariable
Finally, the reliability of the dimensions was esti mated. The E (ω = .78) and N (ω = .81) dimensions showed good reliability, while the reliability of the L scale (ω = .69) was barely acceptable, and the psychoti- cism dimension (ω = .48) showed poor reliability. Differ ential analysis. The MANCOVA carried out revealed a small significant effect of the covariable L (F (3, 2957) = 4.331, p = .005; Wilk’s λ = .996, η 2 = .004), but the ulte rior ANCOVA indicated that it only significantly influenced N (F(1) = 11.488, p < .001; η 2 = .004). The MAN- COVA also revealed statistically significant but small differences between females and males in P, E, and N at the multivariate level: F(3, 2957) = 37.050, p < .001; Wilk’s A = .964, η 2 = .036. The results of the ANCOVA for each of the three dimensions are presented in Table 6. Males showed higher levels of P than females, but the difference was small (η 2 < .06). In contrast, females showed higher levels of N than males, and the difference was also small (η 2 < .06). No significant difference was found in the extraversion dimension.
Table 5 Set of models to test configural, metric, and scalar invariance of models 3 and 4 across females and males considering the L covariable
| X 2( df) | p | △ X 2(A df) | p | CFI | △CFI | RMSEA (C.I.) | △RMSEA | |
| Model 3 - PEN | ||||||||
| Configural | 439.619 (196) | ≤ .001 | N/A | N/A | .967 | N/A | .029 (.025,.033) | N/A |
| WOM | 201.227 | |||||||
| MEN | 238.392 | |||||||
| Metric | 446.407 (212) | ≤ .001 | 21.381 (16) | .164 | .968 | .001 | .027 (.024,.031) | .002 |
| WOM | 201.881 | |||||||
| MEN | 244.526 | |||||||
| Scalar | 492.098 (224) | ≤ .001 | 60.992 (12) | ≤ .001 | .964 | .004 | .028(.025,.032) | .001 |
| WOM | 218.199 | |||||||
| MEN | 273.899 | |||||||
| Model 4 - EN | ||||||||
| Configural | 220.450***(102) | ≤ .001 | N/A | N/A | .982 | N/A | .028 (.023,.033) | N/A |
| WOM | 112.907 | |||||||
| MEN | 107.543 | |||||||
| Metric | 225.924 (114) | ≤ .001 | 15.553 (12) | .213 | .983 | .001 | .026 (.021,.031) | .002 |
| WOM | 112.737 | |||||||
| MEN | 113.187 | |||||||
| Scalar | 266.742 (123) | ≤ .001 | 53.871 (9) | ≤ .001 | .978 | .005 | .028 (.023,.033) | .002 |
| WOM | 127.298 | |||||||
| MEN | 139.444 | |||||||
Note. *p < .05; **p < .01; ***p < .001.
Discussion
The current research aimed to test the psychometric properties of the Spanish EPQ-RA version proposed by Ibáñez et al. (1999) by testing two classic (Eysenck’s orig inal PEN model and four correlated dimensions model) and two alternative models, involving an innovative ap proach, which included L scale as a control for testing three correlated dimensions PEN model and two corre lated dimension E - N model. To achieve this aim, a total of 2962 Spanish young adults were used.
Overall, the Spanish version of the EPQ-RA pro posed by Ibáñez et al. (1999) shows more promising psychometric properties than the adaptation made by Sandin et al. (2002a, 2002b). Unfortunately, this ver sion is free from limitations previously recognized in the literature. Regarding the measurement models tested in the current research, the results are congruent with pre vious research. Of the four models tested, one showed poor fitting, one showed barely acceptable fitting, and two showed good fitting to the data. As expected, the original model of two correlated dimensions (E - N) and one orthogonal dimension (P), as originally proposed by Eysenck, had the same limitations as the rest of the mod els with the additional gap of nonconsidered relation be tween the three dimensions (including P). As seen in model 2 (four correlated factors PEN-L) and model 3 (PEN model with L as covariable), when the correlation of the P dimension with the other dimensions was in cluded, the fitting of the model improved. Nonetheless, only the PEN model with covariable L showed good fit ting to the data.
Congruent with previous research (García-González, 2021; Vázquez et al., 2019) using the Spanish adapta tion made by Sandin et al. (2002a, 2002b), the four correlated dimensions PEN-L model only showed barely acceptable fitting to the data. These results support the lack of appropriateness of the four-dimension PEN- L model congruent with the proposal made in the cur rent research -do not include the L dimension or social desirability as the fourth personality trait, but as control variable- especially considering the same results were obtained with two different versions of the Span ish EPQ-RA. Nevertheless, there are some differences between the results obtained with the version of Sandin et al. (2002a, 2002b), García-Gozález et al. (2021) and Vázquez et al. (2019). In the previous research, the au thors found the reason for the weak fitting of the model in the P dimension, opting for (1) omitting four of the six items of the P dimension (García-González et al., 2021) or (2) omitting the entire P dimension for testing a three-dimensional ENL model (Vázquez et al., 2019). Unfortunately, these two alternatives present empirical and theoretical limitations. First, by using a two-item dimension, García-González et al. (2021) oversaturated the P dimension, with the lowest number of items rec ommended per dimension four. Second, the proposal of a three-dimensional ENL model proposed by Vázquez et al. (2019) implies theoretical limitations regarding the interpretability of the model as long as the L dimen sion is not originally a personality trait in the same way as the P, E, and N dimensions (Sandin et al., 2002a, 2002b; Sato, 2005). Furthermore, the results obtained here differ significantly from those obtained in the pre vious research in the Spanish context because of the higher robustness of the P dimension. This difference also supports the necessity of taking into account the cultural influence of the measurement instruments. As pointed out by Dong and Dumas (2020) and McLarnon & Romero (2020), the cross-cultural invariance of per sonality models is still questionable, which limits the comparison across countries, but also makes it necessary to consider the potential differences in brief version be cause of the differential appropriateness of items across countries (see Eysenck & Barrett, 2013). These previous findings are congruent and can explain the differences found with different Spanish versions of the EPQ-RA, considering that the version of Sandin et al. (2002a, 2002b) is a Spanish translation of the English version proposed by Francis et al. (1992), while Ibáñez et al. (1999) proposed an EPQ-RA version developed from the largest version EPQ-R in the Spanish context and, thus, taking into account the potential influence of the con text. These findings support that personality could not be invariant across cultures and the necessity of devel oping measures considering context influence (Dong & Dumas, 2020; Ibáñez et al., 1999; McLarnon & Romero, 2020; van Hermet et al., 2002).
Table 6 Descriptive statistics and ANOVAs of neuroticism, extraversion, and psychoticism scores across sexes
| Females (n = 1872) | Males (n = 1090) | F | p | η2p | |
| Psychoticism | 29.873 | ≤ .001 | .010 | ||
| M | 1.65 | 1.89 | |||
| SD | 1.13 | 1.09 | |||
| Extraversion | 2.109 | .147 | .001 | ||
| M | 3.20 | 3.28 | |||
| SD | 1.43 | 1.34 | |||
| Neuroticism | 58.242 | ≤ .001 | .019 | ||
| M | 2.61 | 2.06 | |||
| SD | 1.83 | 1.73 |
In this regard, there was no empirical or theoreti cal reason a priori for omitting the entire P dimension. Following this theoretical approach and based on previ ous empirical results, the three-dimensional PEN model with the covariable L was tested and showed good fitting of the model to the data supporting this proposal. The PEN model with L as a covariable is theoretically con gruent and includes the control of social desirability, as it was originally thought and usually included in the ap plied research (e.g., MANCOVA instead of MANOVA). Despite the results obtained here showing a more robust P dimension compared to previous research (see García- González et al., 2021; Vázquez et al., 2019), it is not free from limitations. As seen, only three of the six items of the P dimension showed appropriate factorial weight (> .30), while one (item 3) showed poor (> .10). How ever, significant weight and two items (15 and 19) must be omitted due to lack of significance and extremely low (< .10) factorial weight. Considering the factorial weights, it would be reasonable to omit item 3, despite it significantly loaded in the P dimension. Nevertheless, omitting an additional item would make the P dimen sion oversaturated (three items), biasing the results of the model. Considering this limitation of the P dimen sion and problems found in previous research, it was considered more appropriate to test an alternative two-dimensional EN model with a covariable L that showed the best fitting of the model to the data. This is also supported by the reliabilities of the dimensions. As in previous research (e.g., Alexopoulos & Kalaitzidis 2004; Almiro & Ferreira, 2020; Almiro et al., 2016; Forrest et al., 2000; Francis et al., 1992, 2006; Karanci et al., 2007; Sato et al., 2005; Vázquez et al., 2019), only the E and N dimensions obtained good reliabilities, while the P di mension was poorly reliable. The better performance of the two-dimensional EN model and the poor indexes of the P dimension confirmed that the most relevant problem of the PEN model is the P dimension. These findings support the necessity of improving psychoticism measures by developing new items or even reviewing the definition of the construct (Knezevic et al., 2019), which is determinant for appropriate measures development.
The analysis of the covariable also showed relevant results for future research. As seen, some items of the EPQ-RA were significantly influenced by social desir ability, but others did not. Following the general ten dency, considering that the fitting of the model did not differ with and without the covariable, the more parsi monious model (without covariable) should be chosen. Nevertheless, to guarantee that the influence of covari ables could be insignificant in ulterior invariance analy ses, both options were tested. From this approach, and as far as the invariance of the personality measurement model across groups is a requisite for considering the model appropriate, and taking into account that mod els 3 and 4 showed good fitting, their sex invariance was tested including and omitting the covariable L. Contrary to the previous findings on model fitting, different re sults were obtained when the invariance of the models was tested, including or omitting the covariable. While the covariable was omitted from the model, only the con- figural and metric invariance of the three-dimensional PEN model and two-dimensional EN mo del was sup ported. In contrast, configural, metric, and scalar in variance was confirmed when social desirability was con trolled. These results are almost in part congruent with previous research. Dong and Dumas (2020) showed in their review of personality measure studies that the ma jority of the researchers found at least metric invariance across sexes, but less than half (44.83%) reached scalar invariance. More specifically, two of the reviewed stud ies analyzed the measurement invariance of PEN model- based questionnaires using CFA. In the first one, carried out by Picconi et al. (2018), the Eysenck Personality Profiler Short was used, including only P, E, and N di mensions, and partial scalar invariance was found. In the second study, carried out by Bowden et al. (2018), the Eysenck Personality Questionnaire was used, includ ing P, E, N and L dimensions, and partial scalar in variance was demonstrated. As in the current research, the traditional approaches of PEN measurement model testing only allow the confirmation of complete metric invariances across sexes.
On the contrary, complete scalar invariance was also reached in the current study when the effect of social desirability on participants’ responses was controlled, opening an alternative for future research. This result has important implications not for model fitting testing but for comparison across sexes. As seen, the model showed good fitting to the data, even though social de sirability was not controlled, but the appropriateness of the scale to precisely compare males’ and females’ scores on P, E, and N was conditioned by social desirability control. Contrary to previous research, this finding sup ports the main proposal made in the current research of including the L scale as a covariable to control the potential biased responses, instead of including it as the fourth dimension or omitting it from the model.
Finally, differential analyses were carried out. Con trary to previous research where multiple t tests were generally used for this analysis (see, for example, Alexopoulos & Kalaitzidis, 2004; Almiro & Ferreira, 2020; Almiro et al., 2016; Colledani et al.; 2018; Cruise et al., 2007; Francis et al., 2006; García-González, 2021; Lewis et al., 2002; Picconi et al., 2018; Sandin et al., 2002b; Sato et al., 2005; Vázquez et al., 2019), MAN-COVA analyses were carried out in the current research to avoid increasing the type I error derived from multi ple comparisons made by multiple univariate analyses. The results obtained here revealed a significant effect of social desirability (covariable) on N but not on P and E. This analysis also revealed significantly higher levels of P in men and N in women, but the difference was small in both cases. These results are congruent with some previous results but not with others because of the mix ture shown in previous research on the intersexual differ ences on P, E, and N. For example, using Spanish sam ple, García-González et al. (2021) also found that men scored significantly higher on P and lower on N while Vázquez et al. (2019) only found significantly higher lev els of N on women and Sandin et al. (2002b) did not find significant differences on P, E, nor N dimensions’ scores. Nonetheless, the mixture of results is not specific to the Spanish context and can be found in other contexts even with longer versions of the questionnaire (e.g., EPQ-R).
In some cases, previous research is congruent with the results obtained by García-González (2021) and the ones obtained here (e.g., Almiro et al., 2016), but in other cases, only partial congruence was found, as in the Spanish context. For example, Alcázar-Córcoles et al. (2017), Almiro et al. (2020), and (Sato, 2005) only found significantly higher levels of N in women. In contrast, (Cruise et al., 2007) and Forrest (2000) did not show significant differences in N, but ob served that men scored significantly higher on P and lower on E than women.
Finally, some researchers have found significant dif ferences in P, E and N, while others did not find dif ferences across sexes. For example, Alexopoulos and Kalaitzidis (2004) found that women scored significantly lower than men on P and higher on N, as in the current research, but they also detected that women scored sig nificantly higher on E. Similarly, Shevlin et al. (2002) showed significant differences between males and females on P (higher for males), E (higher for males), and N (higher for females), but the differences on P and N were due to sex roles (masculinity-femineity) and dif ferences on E (higher for males) due to sex roles and biological sex. Using the Eysenck Personality Profiler Short (EPP-S), Picconi et al. (2018) found similar re sults: men scored significantly higher on P and lower on N, but in this case, men also scored significantly higher on E. In contrast, Bouvard et al. (2010) and Karanci et al. (2007) did not find significant differences in P, E, or N across sexes. The mixed results obtained to date do not allow us to effectively conclude that the same differences across sexes are present in all the samples, and more research is still required considering alterna tive models (e.g., L dimension as covariable). Nonethe less, the invariance observed in the current research does not support the idea of the sexual-biased items hypoth esis proposed in previous research (e.g., Francis, 1992; Lajunen, 2018), which seems to be different among dis tinct contexts (Lajunen, 2018), explaining the lack of sex bias in the Spanish context.
4. Strengths and limitations
The current research presents different strengths and limitations. The strengths of the current research in clude the innovation in the model testing and the sample. The proposal made here of including the L scale as a con trol and not as a personality trait represents innovation and improvement in the PEN model estimation by being more faithful to the original theory. To the best of our knowledge, the model has not been previously tested, including the L dimension, as it was thought to control biased responses due to social desirability. In contrast, it has been generally omitted or controversially included as the fourth personality dimension. The sample size is significantly larger than the samples used in previous research on the PEN model in the Spanish context, per mitting more accurate estimations of the model due to the requirements of the technique. Although the sam ple used in the current research is also an improvement compared to previous research, it is important to note that it is not representative, and generalizations must be done cautiously.
5. Conclusion
Currently, Eysenck’s work continues eliciting investiga tion and monographic numbers (Bowden et al., 2018; Revelle, 2016), and it has become an instrument widely used in research as a measure of personality in differ ent populations (Abdel-Khalek, 2013; Abad & Forns, 2008; Hurlburt et al., 1982). Its relevance makes it necessary to investigate the validity of the model to ensure the precise evaluation of personality across dif ferent populations. Considering the results obtained here, where the PEN and EN models with L as a co variable resulted in valid models to test and compare personality across sexes, the two correlated dimension model has been shown to be more appropriate consid ering that it shows the best fitting to the data and its higher parsimony. Undoubtedly, the limitations of the three correlated dimension model are inherent to the limitations of the P dimension. Based on previous and current findings, the inclusion of social desirability con trol and improving the items or even the definition of the psychoticism construct seem to be prudent recommen dations, because if the major problem of personality is its measurement (Revelle, 2016), the basis for good item development is a precise conceptualization.

