











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
1. Introducción
El propósito de las revisiones sistemáticas de literatura (RS), se puede enmarcar en los siguientes puntos: i) identificar la producción acumulada sobre una temática específica, ii) identificar los patrones y tendencias que se revelan en un área de investigación o en una temática dada, iii) ampliar la base de información a partir de nuevos hallazgos o nuevas reflexiones y iv) identificar vacíos de conocimiento a partir de los cuales se puedan plantear nuevas investigaciones (Rethlefsen et al., 2021). El primer desafío que se presenta para el logro de estos objetivos es el poder seleccionar los registros relevantes de entre los miles, incluso cientos de miles, que resultan de la combinación de las palabras clave en las bases de datos (Rodríguez-Jiménez & Pérez-Jacinto, 2017).
Las mismas bases ofrecen algunas herramientas para realizar análisis básicos de los resultados de búsqueda, como los filtros y los análisis descriptivos por áreas, autores, revistas, entre otros. Otras estrategias se enfocan en el análisis de ciertas métricas asociadas tanto a los autores como a las revistas, como el índice H, muy usado en la cienciometría (Millán et al., 2017). La literatura también hace referencia a estrategias como el método PRISMA, que describe una serie de pasos para seleccionar documentos relevantes en una SR (Moher et al., 2014; Urrútia & Bonfill, 2010). También se dispone de tecnologías para visualizar estos resultados y profundizar en los indicadores cienciométricos, con herramientas de uso frecuente como VOSwiever (Guler et al., 2021) y bibliometrix (Aria & Cuccurullo, 2017).
También vale la pena destacar estrategias como la de Tree of Science (ToS) en donde se hace uso de la red de cocitaciones y en donde, por medio de la teoría de grafos, se logra identificar aquellos trabajos con mayor cantidad de citaciones (raíz); los más recientes (hojas) y los estructurales (tronco), metodología que se ha usado con muy buenos resultados en campos como las ciencias económicas, la psicología y en revisiones generales de las ciencias sociales e ingenierías (Marín et al., 2017; Ramírez-Carvajal et al., 2021; Ramos-Enríquez et al., 2021; Valencia-Hernández et al., 2020; Zuluaga et al., 2016).
El principal desafío que se presenta para el uso de estas metodologías es el creciente volumen de publicaciones que surge cada año en cualquier área del conocimiento. Una de las soluciones consiste en semiautomatizar las RS haciendo uso de técnicas de aprendizaje automático, técnicas de Procesamiento de Lenguaje Natural y técnicas de aprendizaje profundo (ML, NLP y DL, por sus siglas en inglés, respectivamente) (Khamparia & Singh, 2019; Robledo et al., 2021). Las ventajas del uso de estas tecnologías van desde la reducción de la carga de trabajo por parte de revisores humanos, hasta el cubrimiento de grandes volúmenes de información (Marshall & Wallace, 2019).
El ML ha sido utilizado de distintas formas de acuerdo con los objetivos de las SR (Jonnalagadda et al., 2015; O’Mara-Eves et al., 2015). En Marshall y Wallace (2019), se presenta una estructuración de estas tareas en cuatro grandes grupos: búsqueda, selección o screening, extracción de datos y síntesis. El avance en la aplicación de estas tareas ha llevado al diseño de herramientas como Rayyan, Abastrackr, ExaCT y RobotReviewer, entre muchas otras, a través de las cuales, usuarios no informáticos pueden hacer uso de estas estrategias sin tener que trabajar con los algoritmos de base que soportan estos recursos (Sutton., & Marshall, 2017).
El NLP y el DL han sido los campos de la inteligencia artificial que mayor aporte le han hecho a las tareas de extracción de datos y síntesis, siendo el DL uno de los campos con muy buenos resultados en los casos en donde la cantidad de datos es muy grande. El NLP se define como el conjunto de técnicas y estrategias que permiten que los sistemas interpreten y procesen el lenguaje humano (hablado, simbólico y escrito), complejo por naturaleza y fuente universal de gran parte del conocimiento disponible en la actualidad (Jurafsky & Martin, 2008); dentro de este campo surge el modelado de tópicos, siendo una de las técnicas que permite analizar de manera más eficiente la estructura oculta en una colección de documentos (Gorunescu, 2011; Kowsari et al., 2019).
El propósito de la presente investigación es el de aplicar el enfoque de modelado de tópicos, específicamente la técnica de Asignación Latente de Dirichlet (LDA), a un registro de búsqueda relacionado con el papel y aplicaciones del ML en las revisiones sistemáticas de literatura. A continuación se describe la metodología empleada, junto con las generalidades del modelado LDA. Luego se describen los principales resultados junto con algunas discusiones y, finalmente, se presentan las conclusiones de este trabajo.
2. Metodología
2.1. Modelado de tópicos mediante LDA
El modelado de tópicos es una técnica dentro del campo del NLP, que permite descubrir y comprender las temáticas subyacentes en una colección de documentos. El propósito central de este método es reducir un conjunto de documentos en un marco de datos discretos, usualmente mediante una representación en vectores de dichos documentos, donde cada uno corresponde a un conteo de palabras. Una de las suposiciones básicas del modelado de tópicos es que cada documento es una mezcla aleatoria de temáticas y estas, una mezcla de palabras (Kherwa., & Bansal, 2018).
Uno de los modelos algebraicos mediante los cuales se representa un conjunto de documentos (corpus) es el de la frecuencia de término - frecuencia inversa de documento (tf − idf). La premisa de este modelo es que cuanto mayor sea la frecuencia de un término en un documento, más relevante va a ser dicho término para la definición de la temática del respectivo documento (𝑡𝑓). En complemento, la 𝑖𝑑𝑓 establece que, si un término aparece con mucha frecuencia en muchos documentos, menor será el valor discriminativo de dicho término para la definición de un tópico latente (Asmussen & Møller, 2019). La ecuación 1 muestra la forma de calcular esta frecuencia.
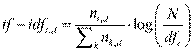 (1)
(1)El modelo de asignación latente de Dirichlet (LDA), se basa en el supuesto de que las palabras en un documento son intercambiables y cada documento se puede representar como una secuencia de palabras individuales (Blei et al., 2003). Este modelo es generativo, lo que significa que analiza, en primer lugar, cómo se producen los datos y posteriormente se analiza qué variable objetivo los ha generado; las características de los tópicos y documentos se extraen de una distribución de Dirichlet, la cual corresponde a una generalización multivariada de una distribución Beta (Jelodar et al., 2019). La aplicación de este modelo tiene como propósito estimar las variables latentes, es decir, los tópicos o temáticas, como una distribución condicionada a los documentos a partir de la distribución conjunta que se presenta en la ecuación 2 (Blei et al., 2003).
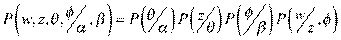 (2)
(2)En la ecuación 2 se tiene que 𝑝 𝜃 𝛼 calcula la distribución de tópicos por documento a partir del parámetro de Dirichlet, el cual es un vector
 de componentes positivas. El cálculo de esta estimación se da mediante la ecuación 3 (Blei et al., 2003).
de componentes positivas. El cálculo de esta estimación se da mediante la ecuación 3 (Blei et al., 2003).
 (3)
(3)El operador 𝛼 definido en la ecuación 3, corresponde a la suma de todos los valores presentes en las variables.
También se tiene la distribución 𝑝 𝑧 𝜃 que estima la distribución del tópico 𝑧 en el corpus, esta estimación se logra mediante la ecuación 4 (Blei et al., 2003).
 (4)
(4)En este caso se estima la probabilidad para los tópicos 𝑧 en todos los documentos en función del número de palabras 𝑛 𝑑,𝑘 , siendo este último el valor asociado a la cantidad de veces que se ha asignado la temática 𝑘 a cualquier palabra del documento 𝑑.
La ecuación 2 también relaciona la probabilidad 𝑝 𝜙 𝛽 la cual se asocia a la distribución de términos por cada temática en el corpus. Esta estimación se obtiene de una distribución de Dirichlet con parámetro 𝛽 y se halla con la ecuación 5 (Blei et al., 2003).
 (5)
(5)En esta ecuación el parámetro 𝜙 𝑘,𝑣 establece la probabilidad de que el término v sea obtenido cuando el tópico fuese determinado.
Finalmente, a partir de la ecuación 2 se tiene la probabilidad condicional del corpus 𝑤 dado el tópico 𝑧 y la distribución de las palabras 𝜙. Esta probabilidad se calcula mediante la ecuación 6.
 (6)
(6)La ecuación 3 se evalúa utilizando el cálculo marginal de las variables latentes, buscando establecer un modelo de probabilidad específico, el corpus 𝑤 y los hiperparámetros, todo esto con el fin de realizar una estimación por el método de Máxima Verosimilitud de los parámetros del modelo y la inferencia sobre los tópicos (Blei et al., 2003). Lo que se ha reportado en la literatura, es que la suma sobre todas las posibles combinaciones de asignación de temáticas conlleva a que el cálculo de esta probabilidad sea computacionalmente muy costoso. Por tanto, las aproximaciones de estas probabilidades marginales se logran utilizando algoritmos de ML (Asuncion et al., 2009; Porteous et al., 2008; Wang et al., 2011). La evaluación de los modelos se hace utilizando métricas como la perplejidad y la coherencia, siendo la última la que más se reporta en la literatura, a partir de la cual se afirma que palabras con significados semejantes coexisten en contextos semejantes (Röder et al., 2015). Esta métrica está basada en Newman et al. (2010) quien propuso el método de información mutua (PMI) a partir de la ecuación 7.
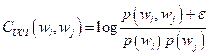 (7)
(7)donde 𝑝 𝑤 representa la probabilidad de que 𝑤 𝑖 esté presente en un documento aleatorio y
 representa la probabilidad de que tanto 𝑤 𝑖 como 𝑤 𝑗 estén presentes en el mismo documento.
representa la probabilidad de que tanto 𝑤 𝑖 como 𝑤 𝑗 estén presentes en el mismo documento.
2.2. Fases de aplicación
La metodología empleada en este trabajo se basa en la aplicación de las siguientes fases: pre - procesado de los datos, construcción del modelo, etiquetado de tópicos y síntesis de la información. Estas tareas se implementaron mediante el lenguaje de programación Python, utilizando la librería Gensim (Prabhakaran, 2018).
La ecuación de búsqueda utilizada para recopilar los documentos iniciales fue: (TITLE-ABS-KEY (machine AND learning) AND ABS (for “systematic review”) AND NOT TITLE-ABS-KEY (“a systematic review”)). Con esta estructura se asegura que los resultados se relacionen directamente con las aplicaciones del ML en las revisiones sistemáticas, en lugar de tener revisiones sistemáticas de la aplicación del ML en otras áreas. El total de registros encontrados fue de 1007 documentos, entre artículos, capítulos de libro y Reviews.
A estos registros se les aplicó una revisión preliminar para identificar los documentos directamente relacionados con la aplicación del ML en las revisiones de literatura y no en otros campos. Esta revisión se hizo utilizando la herramienta Rayyan (Ouzzani et al., 2016). Esto redujo el conjunto de documentos a 202 los que se procesaron directamente con Python y la librería gensin.
3. Resultados y discusión
3.1 Preproceso de los datos
En esta etapa se realiza la limpieza del corpus y se aplican los procesos de reducción del vocabulario (lematización, derivado o stemming, eliminación de stowords, tokenización y definición de bigramas) (Maier et al., 2018). En el presente estudio se logró reducir de 52650 términos del corpus inicial, a 35853 términos en el corpus preprocesado. El siguiente paso en el modelado de tópicos es identificar la cantidad óptima de temáticas, lo cual se evalúa a partir de los índices de coherencia. La Figura 1 muestra que con 10 tópicos se alcanza una coherencia óptima. Para esta cantidad de temáticas, el puntaje de coherencia fue de 0,4828.

La Tabla 1 presenta la identificación de los tópicos estimados por el modelo con sus respectivas palabras clave, el tamaño del tópico en relación al porcentaje de documentos que abarca y la etiqueta asociada al respectivo tópico. Se presentan los tópicos que recogen la mayor proporción de documentos.
Tabla 1 Distribución de documentos por tópico y documento representativo.
| Tópico | Palabras clave | Tamaño del tópico (%) | Etiqueta |
|---|---|---|---|
| 1 | machine, systematic, review, study, use, relevant, identify, learning, approach, datum | 50 | Clasificación automática |
| 4 | visual, screening, review, study, screen, citation, network, use, varied, separately | 14 | Priorización |
| 3 | review, systematic, evidence, decision_make, update, research, automation, challenge, synthesis, base | 14 | Medicina basada en la evidencia |
| 5 | clinical, risk, bert, bias, trial, assessment, text, rct, patient, reviewer | 10 | NLP y modelado de tópicos aplicado |
| 2 | review, use, method, main, analytic, scoping, technique, objective, health, literature | 6 | Revisión de métodos |
| 6 | ensemble, model, article, use, high, recall, task, scientific, criterion, performance | 3 | Componentes de conjunto |
El tópico más relevante es el número 1, al estar conformado por el 50% de los documentos del corpus. Los documentos agrupados en este conjunto están relacionados con las tareas de clasificación de documentos, particularmente resúmenes y reportes cortos, en su mayoría relacionados con el campo de las ciencias médicas (Genc et al., 2020; Weißer et al., 2020; Zimmerman et al., 2021). En este tópico se destacan trabajos como el de Cohen et al. (2009), quienes determinan cómo los métodos automatizados de RS se pueden mejorar utilizando datos de entrenamiento de los modelos de otras revisiones. En el trabajo de Klymenko et al. (2020), se presenta una revisión de los métodos de ML utilizados en el proceso de síntesis de texto. Otro trabajo relevante es el de Walker et al. (2022), donde se presentan los resultados de la aplicación de la herramienta Dextr, diseñada para extracción semiautomatizada de texto en publicaciones clínicas.
En el segundo tópico destacado, etiquetado con el número 4, asociado al proceso de priorización de documentos o screening, se encuentran trabajos que evalúan el desempeño de herramientas como: DistillerSR (Hamel et al., 2020), Abstrackr (Gates, Johnson, et al., 2018) o Research Screener (Chai et al., 2021). También se tienen trabajos que contrastan el desempeño de estas herramientas para las mismas tareas (Gates et al., 2019; Robledo et al., 2021; Tsou et al., 2020) y aquellos que son clave para aplicar las técnicas de ML en las revisiones sistemáticas (Hamel et al., 2021; Waffenschmidt et al., 2018).
En el clúster 3 se resaltan trabajos que plantean desafíos en el uso de ML en las revisiones sistemáticas de literatura. Algunos de estos trabajos plantean una estrategia que denominan Living systematic review (LSR), a través de la cual se puede garantizar que se mantenga la información más reciente y actualizada. Esta estrategia se ha aplicado con mayor frecuencia en revisiones sobre la síntesis de la evidencia biomédica (EBM), donde se busca tener la mayor disponibilidad de información sobre el cuidado de pacientes (Wallace, 2018). Asimismo, se destacan trabajos como el de Elliott et al. (2017), quienes dan algunas indicaciones generales para el desarrollo de esta estrategia, así como en Millard et al. (2019) donde se pone a prueba esta estrategia en un análisis de literatura biomédica publicada en PubMed. Hablando también de la EBM, en Arno et al. (2021) se ponen a prueba los métodos de ML para las tareas de recuperación de registros clínicos; y en Marshall et al. (2020) se dan a conocer los retos para analizar la base de evidencia médica en el campo de la psicología.
En el tópico 5 se resaltan aplicaciones de NLP y modelamiento de tópicos en revisiones de literatura médica relacionada con el dolor (Tighe et al., 2020), con la evaluación de la fiabilidad de los juicios de riesgo de sesgo (Gates, Vandermeer, et al., 2018) y con los ensayos aleatorios controlados (RCT) (Vinkers et al., 2021). El análisis de estas aplicaciones se complementa con trabajos en donde se contrasta la eficiencia de los métodos automatizados o semiautomatizados con revisiones manuales (Soboczenski et al., 2019) o con el uso de herramientas como RobotReviewer aplicadas al análisis de ensayos clínicos (Marshall et al., 2016).
En el tópico 2 se destacan trabajos como el de Chishtie et al. ( 2019), donde se explora y sintetiza la literatura relacionada con la analítica visual aplicada en los servicios de investigación clínica, o el de Sangwan & Bhatnagar (2020) en donde se analizan los distintos métodos de ML que han sido aplicados en la analítica de textos. También se destaca el trabajo de Antons et al. (2021), donde se definen los métodos automatizados de revisión de literatura, como el de revisión computacional de literatura, y se amplía el concepto con varios ejemplos.
En el tópico 6 se tienen trabajos relacionados con métodos que combinan ML y DL, como los modelos BERT, que son arquitecturas de redes neuronales complejas y a los cuales se les pueden agregar conjuntos de características para las tareas de clasificación de documentos (Ambalavanan & Devarakonda, 2020). También se destacan trabajos en donde se ponen a prueba distintas estrategias de búsqueda con el fín de mejorar los resultados de predicción (Alamri., & Stevensony, 2015) o trabajos en donde se evalúa en términos generales el uso de herramientas de ML en las revisiones sistemáticas (Robledo et al., 2021).
3.2 Visualización de los tópicos
Para completar el análisis del modelado de temáticas se utiliza el complemento de la librería Gensim, que permite visualizar la distribución de los tópicos en un plano bidimensional. Este resultado se basa en la aplicación de la técnica de Multidimensional Scaling (MDS), la cual se aplica a la matriz de distancias entre los tópicos (ver Figura 2).

La visualización de los tópicos mediante este diagrama permite identificar patrones de distribución de probabilidades que se asemejan, en relación a las palabras de las temáticas identificadas. El tamaño de los círculos da una idea de la prevalencia del tópico, mientras que la distancia entre ellos da una idea de la similitud de la temática asociada.
En este caso, se observa que los tópicos identificados con los números 1, 3, 4 y 5 comparten cierta similitud entre ellos, conformando un clúster temático en relación a los sistemas de clasificación automática, su desempeño y casos de aplicación. Lo anterior se pudo concluir a partir del análisis de palabras clave y de los documentos representativos en estas temáticas. Los tópicos 2 y 6 son los que permiten definir temáticas independientes entre sí.
4. Conclusiones
La primera conclusión es la posibilidad que se da de entender el protagonismo que ha venido ganando el ML en las revisiones de grandes volúmenes de registros escritos. La revisión de literatura ha sido un campo de estudio que ha madurado mucho, por un lado, debido a la necesidad latente que se tiene en cualquier proyecto de investigación de identificar el camino recorrido en el área de interés para así poder plantear futuras investigaciones, desde una base mucho más objetiva y precisa. Por otro lado, el gran volumen de información que día a día se produce en materia de literatura científica y el desafío que se le presenta a los investigadores de contar con herramientas que les permita cubrir de manera eficiente estos grandes volúmenes de datos, ha permitido que el ML juegue un papel muy importante al desarrollar técnicas y herramientas para realizar estas tareas de revisión (Tranfield et al., 2003).
El uso de la técnica LDA permitió identificar los autores y revistas más relevantes en lo referente a la revisión de literatura científica. Esta situación es de gran relevancia para aquellas investigaciones que se desarrollen en esta misma línea o que quieran profundizar algún aspecto particular, ya que teniendo claros estos aspectos será mucho más fácil buscar directamente en estos recursos o los trabajos desarrollados por estos investigadores.
En este trabajo también se hace manifiesta la importancia y utilidad del modelado de tópicos, en particular de la técnica LDA para la revisión exploratoria de literatura científica. Se trata de una estrategia fácil de aplicar y cuyos resultados permiten abordar una amplia colección de documentos, de manera sistemática y coherente, reduciendo notablemente el tiempo utilizado para la revisión. Si bien en este trabajo no se hizo evaluación del ahorro en carga de trabajo, varias de las referencias obtenidas dan cuenta de este aspecto (Kherwa & Bansal, 2018; Qiang et al., 2020; Zhao et al., 2021).
Otro hallazgo importante fue el poder identificar en los registros de búsqueda una serie de temáticas que agrupan dichos registros, a partir de lo cual fue posible establecer cuáles son las áreas en donde se ha dado mayor demanda de este tipo de tecnologías, siendo las ciencias médicas el área en donde se encuentra mayor cantidad de evidencia empírica. Aun así, se pudo recopilar evidencia importante de aplicación de estas estrategias en otras áreas del conocimiento, donde se brindan recomendaciones valiosas para una aplicación óptima de estas estrategias (Bertolini et al., 2021; Kang et al., 2020; Kumeno, 2020).
También se observa la utilidad de la visualización de los resultados del modelado de tópicos, lo cual permite identificar temáticas en un nivel general. Para este ejercicio, la técnica de MDS resulta apropiada y los resultados de su aplicación complementan muy bien la tarea de identificar la distribución de los documentos en temáticas y las relaciones que se puedan dar entre estas (Sami, 2020; Wei et al., 2020; Xie et al., 2018; Zhang et al., 2018).
Finalmente, se plantea como trabajo futuro el contraste de los resultados aquí reportados, limitados a Scopus, con los que se puedan obtener en otras bases de datos de alto impacto como Web of Science.

