Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
INTRODUCCIÓN
Las matrices insumo-producto (MIP) del Sistema de Cuentas Nacionales (SCN) son empleadas para analizar las interacciones entre las diferentes ramas de actividad económica de una economía. Estas matrices registran cómo la producción de una rama es utilizada como insumo por otra, creando así una red de relaciones económicas. Desde los estudios pioneros como los de Rasmussen (1956), Laumas (1975), Schultz (1977) y Hewings (1982) se ha empleado el álgebra matricial y herramientas como los multiplicadores de Leontief para analizar los datos de estas matrices. Algunos autores como Baumol (2000a) han afirmado que el análisis tradicional basado en las MIP puede ser considerado como una de las contribuciones más importantes a la ciencia económica del siglo XX, ya que ha facilitado una fuerte interdependencia entre teoría, datos y aplicación.
Estas herramientas se han convertido en un estándar de la medición económica (Lora & Prada, 2023). Las aplicaciones del análisis tradicional de las MIP son variadas; van desde determinar el impacto de cambios en la demanda final en la economía (por ejemplo Baumol, 2000b), hasta encontrar los efectos de cambios en la producción de una rama en el resto de la economía (ver capítulo 6 de Miller & Blair, 2009) o el calcular multiplicadores que llevan al análisis de encadenamientos productivos (por ejemplo Hirschman, 1958) o detección de cambios estructurales (Guo & Planting, 2000). En la actualidad, estas herramientas siguen siendo relevantes, a pesar de la aparición de enfoques que implican el modelado de la economía como los modelos de equilibrio general (Jorgenson, 2016). Por otro lado, existe una metodología relativamente nueva para examinar la estructura productiva representada en la MIP: la teoría de redes.
La teoría de redes surge de diversas áreas del conocimiento que buscan resolver problemas con estructuras de datos que presentan interrelaciones entre individuos (Alonso & Carabali, 2019). Desde los años treinta, los sociólogos han valorado la importancia de los patrones de conexión entre las personas para comprender cómo funciona una sociedad (Wasserman & Faust, 1994). Los investigadores han utilizado las redes para analizar diversos fenómenos, como la propagación de enfermedades, la formación de grupos y comunidades, y la difusión de información (Graham & De Paula, 2020). La teoría de redes analiza las características y propiedades de las redes, y su visualización a través de grafos.
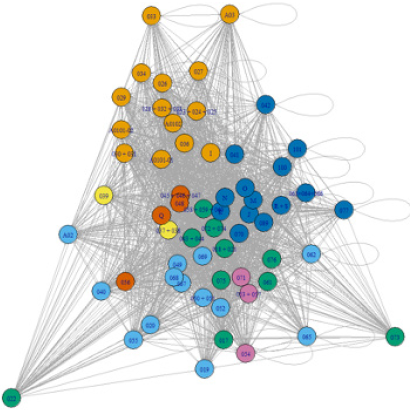
En la Figura 1 podemos ver un ejemplo de un grafo que muestra la MIP (las compras de productos que se emplean en el consumo intermedio para producir) de las 61 ramas de actividad económica en 2015 en Colombia. Los círculos (nodos) representan a cada una de las ramas de actividad y las líneas que conectan a los puntos (aristas) representan las transacciones entre las ramas.
Fuente: elaboración de los autores.
Figura 1 Ejemplo de un grafo paras ¡as 61 ramas de actividad presentes en la matriz insumo-producto para el año 2015
Las herramientas de la teoría de redes permiten detectar conjuntos (comunidades) de nodos que están más estrechamente relacionados entre sí que con el resto de los nodos en la red. Las comunidades se pueden armar empleando criterios como la densidad de conexiones internas y una menor cantidad de conexiones con los nodos fuera de la comunidad (Araújo & Faustino, 2017). En últimas, la detección de comunidades corresponde a un ejercicio de encontrar clústeres (en el sentido estadístico) de ramas de actividad económica que están más densamente conectadas entre sí que con el resto de la red. Las ramas de actividad económica en una comunidad presentan relaciones más fuertes o más frecuentes, compartiendo características comunes (Araújo & Faustino, 2017). En la Figura 1 las comunidades se representan por el color de los nodos. Se encontraron siete comunidades (más adelante se explicará cómo se llega a este número).
Nota: cada nodo (círculo) representa una rama de actividad económica de acuerdo con la clasificación CIIU Revisión 4 Armonizada para Colombia (Rev. 4 A.C.). En la Tabla 2 se puede ver el código de cada rama y su respectivo nombre. El color de cada nodo representa la comunidad a la que pertenece (esto se discutirá más adelante en detalle).
Es interesante detectar comunidades en una red creada a partir de una MIP porque proporciona información valiosa sobre la estructura y las interrelaciones de la economía (Xu & Liang, 2019). Al identificar comunidades podemos entender a partir de los datos, y no de las preconcepciones de los analistas, cómo se agrupan y relacionan las diferentes ramas de actividad económica en términos de sus interdependencias y flujos de insumos. Esto permite identificar patrones de especialización, interconexiones económicas sectoriales, y la existencia de ramas de actividad económica altamente dependientes (clústeres industriales).
El objetivo de este documento es estudiar la evolución de las interrelaciones del aparato productivo colombiano que se reflejan en las comunidades de ramas de actividad económica implícitas en la MIP entre los años 2005 y 2021. Para lograr este objetivo se emplean herramientas de la teoría de redes para analizar las MIP a nivel actividad-actividad de Colombia. Además, se prueban diferentes opciones para crear comunidades de ramas de actividad económica. Posteriormente, se presenta un análisis de estabilidad de las comunidades que es común en la literatura de clústering (en el sentido estadístico) para evidenciar si las comunidades cambian o no de un año a otro. Adicionalmente, para este estudio fue necesario construir las MIP de Colombia para 17 años (de 2005 a 2021) a partir de los cuadros oferta y utilización (COU) publicados por el Departamento Administrativo Nacional de Estadística (DANE).
Este estudio amplía la literatura en tres sentidos. Primero, analiza la evolución de la estructura productiva colombiana implícita en MIP empleando métricas de la teoría de redes. Segundo, explora un conjunto de técnicas de detección de comunidades para encontrar las comunidades formadas en cada año. Tercero, aplica el análisis de estabilidad para clústeres tradicionales a las comunidades resultantes del ejercicio. Hasta donde llega el conocimiento de los autores, este análisis de estabilidad no se ha intentado anteriormente en el contexto del análisis de redes. Finalmente, se construyen las MIP para el periodo 2005-20211.
Este documento está dividido en cuatro apartados. En el primer apartado se hace una breve revisión de literatura sobre el uso de la teoría de redes en el ámbito económico; en el segundo apartado de expone la metodología empleada; en el tercero se discute cómo se construyen los datos utilizados y, en el cuarto, se muestran los resultados obtenidos. El documento concluye con unos comentarios finales.
REVISIÓN DE LA LITERATURA
La teoría de redes se ha convertido en una herramienta cada vez más valiosa en el análisis de problemas económicos. En el ámbito del comercio internacional, se han empleado los grafos y las herramientas de la teoría de redes para representar las relaciones comerciales entre países, con el fin de identificar los principales actores de la red, los flujos comerciales más importantes y las relaciones entre los distintos sectores económicos (ver, por ejemplo, Beaton et al., 2017; Zhou et al., 2016; Hidalgo & Hausmann, 2010; Fagiolo et al., 2008). En Colombia, Borda-Blanco (2017) compara diferentes metodologías, que incluyen la teoría de redes, para analizar la complejidad del comercio exterior a nivel departamental y mundial entre los años 2012 y 2015.
En la literatura que estudia el mercado laboral también se han empleado estas herramientas para analizar cómo los trabajadores encuentran trabajo a través de sus contactos personales, en lugar de hacerlo mediante los canales tradicionales de anuncios de empleo (Myers & Shultz, 1951; Granovetter, 1978). Recientemente, O'Clery et al. (2019) presentan una aplicación al caso colombiano para comprender cómo se relacionan los empleadores y los empleados, y cómo la estructura de la red laboral puede afectar la movilidad, integración y dinámica del mercado para 62 municipios.
Otros ejemplos del uso de las herramientas de redes en problemas económicos y de los negocios se presentan en el análisis de redes de innovación (König et al., 2008; Montresor & Marzetti, 2009), el flujo de miembros de juntas directivas entre empresas (Clemente & Cornaro, 2019), las relaciones entre productos y su especialización en el comercio exterior (Hidalgo et al., 2007; Jankowska et al., 2012), las redes de propiedad de negocios (Ding & Lu, 2015), los préstamos interbancarios (Iori et al., 2008), la inversiones en acciones (Battiston et al., 2005) y el riesgo sistemático (Lorenz et al., 2009).
En términos de herramientas econométricas, también se han realizado grandes adelantos; por ejemplo, Graham y De Paula (2020) presentan una amplia variedad de modelos econométricos con sus fortalezas y debilidades en el análisis de este tipo de datos.
Una corriente adicional de las aplicaciones de redes en economía es el estudio de las MIP. Las MIP se componen de ramas de actividad y vínculos intersectoriales que son similares a los nodos y bordes del sistema de redes, esto llevó rápidamente a los investigadores a emplear herramientas de la teoría de redes.
Uno de los trabajos pioneros en emplear estas herramientas para el análisis de MIP fue el de Slater (1977). El autor creó agrupaciones de ramas de actividad para Estados Unidos empleando análisis de clústeres a partir de métricas de los nodos. Slater (1978) incorporó más elementos del análisis de redes sociales para investigar la estructura económica. Desde entonces aparecen diferentes estudios que incorporan las herramientas de redes al análisis de la estructura económica implícita en la MIP (Sonis & Hewings, 1998; Acemoglu et al., 2012). Paralelo al análisis cuantitativo de las redes implícitas en la MIP, se ha desarrollado otra área conocida como el análisis cualitativo input-output (QIOA). El QIOA emplea las herramientas desarrolladas en la teoría de grafos dirigidos de tal manera que solo se tiene en cuenta la dirección de las interconexiones y no la magnitud del flujo entre sectores (por ejemplo, Drejer, 2000; Ghosh & Roy, 1998; Aroche-Reyes, 2003; Schnabl, 1994).
Regresando al análisis cuantitativo de la redes, se encuentran trabajos como los de McNerney et al. (2013) que estudian la estructura de las relaciones entre industrias para 45 economías nacionales. Los autores emplean datos de MIP para 2002 y 2006 producidas por la Organización para la Cooperación y el Desarrollo Económicos (OCDE) y métricas tradicionales. Sun et al. (2018) analizan los sectores y conexiones más importantes de la economía china para comprender el efecto sobre la economía global. Este estudio se centró en las redes provinciales y en la red interprovincial, siguiendo una línea de investigación que estudia las estructuras de las economías regionales con herramientas de redes (por ejemplo Giuliani, 2013; García et al., 2008; García, 2013).
Por su parte, Xing et al. (2018) estudian el grado de globalización de los sectores industriales en la cadena de valor global construyendo MIP entre los países a partir de datos del World Input-Output Database (WIOD) para el año 2016. Los autores consideraron el flujo de productos intermedios en la cadena de valor global como un proceso de Markov para encontrar la cantidad adicional de trabajo que se realiza en un sistema de producción específico cuando la demanda final a nivel global aumenta.
Araújo y Faustino (2017) emplean la teoría de redes para estudiar el efecto de la crisis financiera de 1998 y posterior programa de ajuste económico en la estructura productiva de Portugal. Los autores centran su atención en analizar el periodo 2000 a 2014 y emplear métricas de la teoría de redes para estudiar las relaciones interindustriales. La evolución de estas métricas les permitió evidenciar el cambio estructural para el periodo 2011-2014 y demostrar la utilidad de las herramientas de la teoría de redes para el análisis de las relaciones interindustriales. Este trabajo no presenta una comparación formal de las métricas para establecer el cambio estructural.
Xu y Liang (2019) emplean análisis de redes y construcción de comunidades para estudiar una MIP construida para 41 economías empleando datos del WIOD para el año 2019. Los autores encuentran que la industria de minas y canteras del resto del mundo es el sector más central de la economía mundial. Así mismo, identifican a los servicios gubernamentales de Estados Unidos como el motor de la economía mundial, mientras que la industria de servicios estadounidense es el proveedor más importante. Los autores no presentan un análisis formal de los cambios en las comunidades para establecer cambio estructural.
DePaolis et al. (2022) emplean datos de MIP a nivel de condado, área metropolitana y estado para Estados Unidos, y medidas de centralidad basadas en caminos aleatorios para identificar los principales sectores.
Por otro lado, Domínguez et al. (2021) investigan la convergencia de la productividad de 106 sectores productivos en Japón durante el periodo 2003-2012. Los autores emplean un análisis de comunidades para encontrar dos grupos que están altamente intercomunicados. Una vez establecidas las comunidades encuentran que la membrecía de los sectores a las comunidades no varía mucho. Los autores no realizan un análisis formal de estabilidad de las comunidades. Con las comunidades establecidas, se realiza un análisis tradicional de series de tiempo de convergencia de productividad de los sectores relacionados como el sugerido por Barro y Sala-i-Martin (1992).
En la literatura que emplea las herramientas de redes para analizar las MIP se encuentra otra vertiente de estudios que no se interesan por la estructura de la economías per se, sino por la propagación de diferentes fenómenos por la red. Por ejemplo, Blöchl et al. (2011) emplean medidas de centralidad basadas en caminos aleatorios para detectar, en 37 países de la OCDE, cuáles de las ramas de actividad de las que nacen los choques se propagan para generar los ciclos económicos. Contreras y Fagiolo (2014) investigan cómo se propagaron los choques para varios países europeos antes de la Gran Depresión de 1929.
Dotta (2021) estudia el impacto de los impactos tecnológicos y de demanda para diez países suramericanos (Argentina, Brasil, Bolivia, Chile, Colombia, Ecuador, Perú, Paraguay, Uruguay y Venezuela).
Hasta donde llega nuestro conocimiento, para la economía colombiana no se han publicado estudios que caractericen la estructura productiva del país con herramientas de la teoría de redes; no solo en términos de métricas que describan y caractericen las ramas de actividad económica, sino también en cuanto a las comunidades que se forman entre ellas y cómo esas composiciones cambian a lo largo de un periodo de tiempo prolongado. Respecto a la estabilidad de las comunidades, solo se identificó el trabajo reciente de Domínguez et al. (2021) que emplea las comunidades para detectar cambios estructurales, pero los autores no presentan una aproximación formal para probar la estabilidad de la membrecía a las comunidades de las ramas de actividad.
METODOLOGÍA PARA EL ANÁLISIS DE LAS REDES
La teoría de redes provee métricas para analizar la estructura del sistema de producción de un país reflejado en las MIP. Por ejemplo, se pueden emplear métricas globales para caracterizar aspectos como la conectividad, la robustez y la eficiencia de la estructura económica implícita en la MIP (Alonso & Carabali, 2019; Tsekeris, 2017). Dos de las métricas globales más utilizadas son la densidad y el diámetro (para una mayor discusión ver Niño, 2020). La densidad mide la cantidad de conexiones existentes en un grafo, mientras que el diámetro representa la longitud del camino más largo entre dos nodos.
Una red con una alta densidad indica una mayor interconexión entre los nodos. Por otro lado, un diámetro alto indica que los caminos más largos entre pares de nodos en la red son relativamente extensos. Esto significa que hay una distancia geodésica considerable entre los nodos más alejados. Es decir, una ausencia de conexiones directas o rutas más cortas entre ciertos nodos, lo que resulta en la necesidad de recorrer caminos más largos para alcanzar otros nodos en la red.
Además de las métricas están los algoritmos de la teoría de redes que se utilizan para encontrar comunidades de nodos en la red (grupos de ramas de actividad) y los criterios para evaluar dicha selección.
Antes de entrar en el detalle, definamos un grafo como:
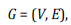
Donde: V es un conjunto de n nodos y E es un conjunto de m aristas. Este grafo se construye a partir de la matriz de adyacencia A, donde cada entrada α ij es el peso de la arista que va desde el nodo i hasta el nodo j. En nuestro caso, las entradas de la matriz de adyacencia serán las celdas de la MIP.
En el contexto de las redes, las comunidades corresponden a conjuntos de nodos que están intercomunicados entre sí, más que con los miembros de otras comunidades. Al final, encontrar comunidades implica realizar un ejercicio de agrupamiento (clústering). La construcción de clústeres implica elegir un algoritmo de agrupamiento y una métrica para determinar el número de clústeres.
La métrica que convencionalmente se emplea para seleccionar el número de comunidades en la literatura de teoría de redes es la modularidad2, propuesta por Newman & Girvan (2002). La modularidad calcula las densidades dentro y fuera de cada clúster y las compara con la densidad general que tendrían si la red fuera construida de manera aleatoria. En otras palabras, evalúa la estructura de una red en términos de cómo se agrupan los nodos en módulos o comunidades, midiendo la calidad de la división. Cuanto mayor sea la modularidad de una red, mayor será su estructura modular, lo que significa que los nodos tienden a formar comunidades densamente conectadas.
De manera formal, la modularidad se define como:
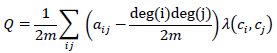
Donde:
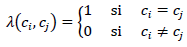
deg(i) es el grado del nodo i y c i es el clúster i.
Los valores de modularidad cercanos a cero indican que el número de enlaces dentro del clúster es menor al valor que se esperaría en una red aleatoria. El valor máximo de esta métrica tiende a 1. Valores muy cercanos a uno indican que el clúster está altamente conectado. En la práctica está ampliamente documentado que la modularidad típicamente se encuentra entre 0,3 a 0,7 (Niño, 2020).
La modularidad es tanto un criterio de evaluación de la calidad de las comunidades resultantes de un proceso de detección de comunidades, como una métrica que se optimiza en los diferentes algoritmos de detección de comunidades.
El segundo elemento que se requiere para construir comunidades es un algoritmo para agrupar. En el contexto de las redes existen algoritmos específicos para generar clústeres diferentes a los empleados en la literatura tradicional del clústering3. Estos algoritmos utilizan la modularidad, bien sea como función objetivo (clústering de modularidad óptima y Spin glass) o como forma de decidir el número de clústeres una vez generado un dendrograma (clústering con intermediación de aristas y Walktrap) (Niño, 2020).
El algoritmo de clústering con intermediación de aristas (Edge betweenness clustering) encuentra comunidades identificando las aristas que tienen el mayor valor de intermediación; es decir, las aristas que se encuentran en muchos caminos más cortos entre pares de nodos. Encontrar comunidades de esta manera se basa en la idea de que, si en una red existen dos comunidades claramente distinguidas, es probable que la arista con la mayor intermediación sea aquella que las une.
En otras palabras, los caminos geodésicos entre los nodos que hacen parte de una de las comunidades y los nodos que hacen parte de otra deberán pasar obligatoriamente por una arista, lo cual hace que esta tenga una alta centralidad de intermediación (para un detalle del algoritmo ver Newman & Girvan, 2004).
Luego de generada la estructura jerárquica, es posible elegir el número de comunidades de tal manera que se maximice una métrica de calidad de la partición como la modularidad.
Brandes et al. (2008) propusieron el algoritmo de clústering de modularidad óptima (Optimal clustering) que convierte la modularidad en la función objetivo de un problema de programación lineal de enteros. En especial, para la expresión λ(c i , c j ) se prueban todas las particiones posibles y se elige la que maximiza la modularidad.
El algoritmo Walktrap (Pons & Latapy, 2005) se basa en la idea de que un proceso de camino aleatorio puede identificar comunidades, pues la probabilidad de pasar de un nodo a otro que está en la misma comunidad es más alta que la probabilidad de pasar a un nodo que no está en la comunidad, teniendo en cuenta que el grado intraclúster es más alto que el grado interclústeres.
Para lograr este objetivo, se define una medida de la distancia entre dos comunidades basada en la probabilidad de que el camino aleatorio pase de un nodo i en la comunidad c 1 a un nodo v en la comunidad c 2 en t pasos
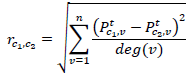
donde: P t c,v es la probabilidad de ir de una comunidad c al nodo v en t pasos y está definida como
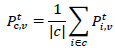
Con esto expresado, se define un algoritmo aglomerativo para encontrar una estructura jerárquica (dendrograma) y se elige el número de comunidades que maximice la modularidad.
De acuerdo con Reichardt y Bornholdt (2006), el problema de encontrar comunidades puede ser interpretado como la configuración de spin que minimiza la energía de un sistema Spin Glass (algoritmo Spin Glass). Es importante mencionar que el spin es una forma de momento angular en física de partículas (un vector de movimiento de partículas fundamentales) y un Spin Glass es una colección de partículas con spin caracterizada por la aleatoriedad. Además, los enlaces en un Spin Glass son una mezcla de enlaces ferromagnéticos, donde los enlaces atómicos adyacentes tienen la misma orientación, y enlaces antiferromagnéticos, donde los enlaces atómicos adyacentes tienen orientaciones opuestas.
En el caso de las redes, las partículas serían los nodos y su conjunto sería el spin glass. Cuando dos nodos están conectados se considera un enlace ferromagnético, y cuando no están conectados se considera un enlace antiferromagnético. De esta manera, los estados de spin son los índices de las comunidades, por lo que si se encuentran los estados que minimizan la energía del sistema, se estaría hallando un estado en el que las comunidades son estables.
Como el objetivo final es crear grupos coherentes (bastantes aristas intraclúster) y separados (pocas aristas interclúster), se plantea una función que premia que existan aristas entre nodos del mismo grupo (mismo estado de spin), penaliza la falta de aristas en nodos del mismo grupo, penaliza la existencia de aristas entre nodos de distintos grupos (diferente estado de spin) y premia que haya aristas inexistentes entre grupos distintos. Matemáticamente
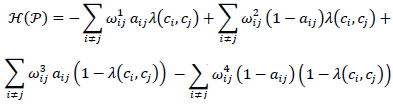
donde: ci ∈ {1,2,…,k} denota el estado de spin (comunidad) del nodo i y ω 1 ij ω 2 ij , ω ij 3, ω 4 ij son los pesos que se les quiera dar a cada criterio. Así, el primer término mide los enlaces internos, el segundo los enlaces no existentes internos, el tercero los enlaces externos y el cuarto los enlaces externos no existentes. Reichardt y Bornholdt (2006) muestran que, si se minimiza el anterior hamiltoniano, se está maximizando la modularidad. En este sentido, este método determina automáticamente el número de clústeres, de manera similar al algoritmo de clúster de modularidad óptima.
Los algoritmos de intermediación de aristas (Edge betweenness clustering), clústering de modularidad óptima (Optimal clustering), Walktrap y spin glass permiten identificar el número óptimo de comunidades, así como la membrecía a cada comunidad de cada nodo. Así, estos algoritmos nos permitirán encontrar las comunidades para cada red (año) y la membrecía a una comunidad de cada una de las ramas de actividad.
Finalmente, en nuestro análisis de las MIP es importante determinar si las comunidades han cambiado o no de un año a otro, es decir, analizar su estabilidad. Para determinar los cambios en las comunidades emplearemos medidas de estabilidad de los clústeres provenientes de la literatura "tradicional" de clústering.
En la literatura de ciencia de datos se han diseñado métricas que tienen como objetivo evaluar si los grupos de individuos asignados a cada clúster han experimentado cambios significativos a lo largo de los periodos bajo estudio. Estas medidas de estabilidad describen el grado de superposición en la intersección de grupos entre dos conjuntos de datos diferentes. Las medidas incluyen la homogeneidad (H), completitud (C), medida V (VM), índice de Rand (RI) e índice de Rand ajustado (ARI). En general, si la superposición entre los grupos es alta, la estabilidad también será alta.
La métrica de homogeneidad (H) entre dos poblaciones o muestras clusteriza-das es una medida de similitud basada en la entropía. La escala de homogeneidad va de 0 a 1, donde 1 indica completa homogeneidad y cero heterogeneidad total4. Otra métrica popular basada en la entropía es la completitud (C). Esta métrica será igual a 1 si todos los miembros de una clase dada en el agrupamiento están asignados al mismo grupo en el siguiente periodo (Rosenberg & Hirschberg, 2007).
Por su parte, la medida V (VM) combina la homogeneidad y la completitud calculando una media armónica ponderada entre esas dos métricas. En este caso también se tiene que un valor de 1 corresponde a una coincidencia perfecta entre los agrupamientos de los dos periodos.
El índice de Rand (RI) presenta un enfoque diferente para comparar agrupa-mientos. Emplea comparaciones pareadas para determinar si ambos agrupamien-tos etiquetan cada punto de datos en el mismo grupo. Un valor de 1 representa un acuerdo exacto entre los agrupamientos de dos periodos, mientras que 0 representa desacuerdo en todos los pares de elementos (Santos & Embrechts, 2009).
Por lo general, las medidas de estabilidad de los clústeres o las medidas de evaluación para un agrupamiento predictivo se basan en un agrupamiento de referencia considerado como la "verdad absoluta". En nuestro caso, utilizaremos estas medidas empleando la pertenencia a una comunidad el año anterior (t-1) como la referencia absoluta para evaluar si la estructura en del año t es similar o no.
Para resumir, nuestra aproximación empírica implica los siguientes pasos:
Calcular para cada año (t) las métricas globales para caracterizar las ramas de actividad económica y la red en su conjunto, donde t= 2015, 2016, ... , 2021.
Para cada año (t), encontrar el número óptimo de comunidades para cada uno de los siguientes algoritmos: intermediación de aristas, clústering de modularidad óptima, Walktrap y Spin Glass.
Para cada año (t) seleccionar la mejor aproximación para construir las comunidades; i. e., el número de comunidades y respectivo método que maximiza la modularidad.
Conformar las comunidades para cada año (t) y registrar la membrecía de cada rama de actividad económica a las respectivas comunidades.
Comparar la composición de las comunidades del año t con respecto al año t-1 empleando las métricas de homogeneidad (H), completitud (C), medida V (VM), índice de Rand (RI) e índice de Rand ajustado (ARI).
Los anteriores pasos se realizan en el lenguaje estadístico R (R Core Team, 2022) empleando los paquetes tidyverse (Wickham et al., 2019), igraph (Csardi & Nepusz, 2006), cluster (Maechler et al., 2022), NbClust (Charrad et al., 2014), parameters (Lüdecke et al., 2020), dendextend, (Galili, 2015), FNN (Beygelzimer et al., 2023) y keyplayer (An & Liu, 2023).
DATOS
La MIP es una de las matrices del conjunto del SCN. La MIP muestra las interacciones que existen entre los insumos necesarios para la producción de bienes finales o intermedios, de tal forma que se pueda estudiar el flujo de bienes y servicios dentro de la economía, independientemente del destino (producción de otros bienes y servicios, consumo final de hogares o inversión).
La MIP requiere que los consumos intermedios se clasifiquen de manera idéntica, ya sea en términos de productos o de actividades. Su cálculo proviene de los COU, que para Colombia tienen en las filas los productos5 y en las columnas las ramas de actividad económica6. En la actualidad, el DANE no publica con frecuencia anual la MIP. Esta no hace parte de los cuadros de salida convencionales de las Cuentas Nacionales.
Por esto, es necesario realizar transformaciones en los COU y hacer un tratamiento a las producciones secundarias a través de la aplicación de diferentes modelos teóricos que dependen del tipo de MIP que se quiere analizar (nacional, importaciones y total de la economía) y así encontrar la respectiva producción y generación de ingreso (DANE, 2013).
Para nuestro análisis emplearemos las MIP en su versión actividad-actividad y nacional siguiendo a Sun et al. (2018), Xing et al. (2018), Araújo y Faustino (2017) y McNerney et al. (2013). La MIP actividad-actividad nacional la calculamos para un nivel de desagregación de 61 ramas de actividad.
Las revisiones más recientes de las clasificaciones internacionales de las actividades iniciaron un nuevo ciclo de publicación de las MIP con base en el año 2015 por parte del DANE, quien publicó las MIP para los años 2015 y 2017. No obstante, dada la disponibilidad de solo 2 años de MIP actividad-actividad, el presente trabajo implicó el cálculo de la MIP para los años 2005 a 2021 siguiendo la metodología propuesta por el DANE (2013).
La construcción de la MIP actividad-actividad se fundamenta en un modelo matemático que permite transformar la matriz de consumo intermedio (Ud) del COU sustituyendo las filas que representan productos por actividades. En particular, el modelo que propone el DANE supone que cada producto tiene su propia estructura de ventas7, independientemente de la industria que lo produce (supuesto de estructura de ventas de producto fijo). Lo anterior implica que las proporciones que aporta cada actividad económica en la producción de un producto se mantienen constantes sin importar qué industria lo produzca. Este supuesto permite derivar la MIP directamente de la COU sin hacer definiciones adicionales sobre la producción primaria o secundaria de cada industria (DANE, 2013).
Matricialmente, la matriz de transformación (T) será la matriz de participación de mercado de cada producto
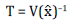
donde: V es la matriz de producción industria-producto que viene del cuadro de oferta y
 =
diag(x)
es una matriz en la que la diagonal es la producción por producto que viene del cuadro de utilización.
=
diag(x)
es una matriz en la que la diagonal es la producción por producto que viene del cuadro de utilización.
Finalmente, la MIP actividad-actividad se obtiene multiplicando la matriz de transformación por la matriz de consumo intermedio.
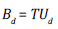
Este proceso fue implementado en R para cada uno de los años en el periodo de estudio (2005 a 2021). En el Anexo 1 se muestran las 61 ramas de actividad económica según el CIIU Rev. 4 A.C que se emplearán en el análisis de este documento.
RESULTADOS
En la Figura 2 se reporta la evolución del diámetro y la densidad de la red implícita en las MIP colombianas de 2005 a 2021. El diámetro creció en el periodo de estudio, lo que implica una mayor cohesión o relación entre las ramas de actividades. El diámetro también aumenta en el periodo de estudio, y muestra una mayor distancia entre las ramas de actividad más alejadas.
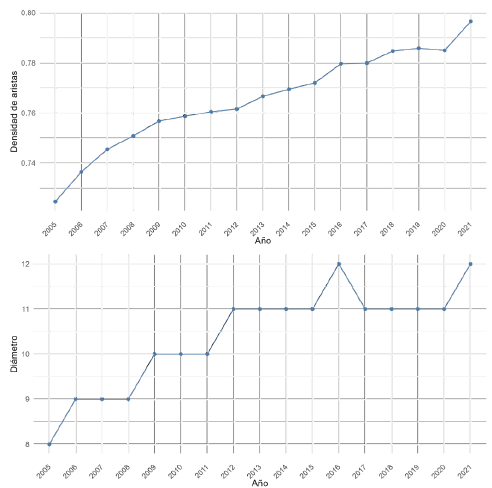
Estas dos métricas muestran una red cada vez más interconectada; al mismo tiempo, con distancias más largas entre actividades. Esto podría ser una señal de que la economía colombiana es cada vez más sofisticada, pues cuenta con cadenas de valor cada vez más largas y que incorporan los productos y servicios de más sectores económicos.
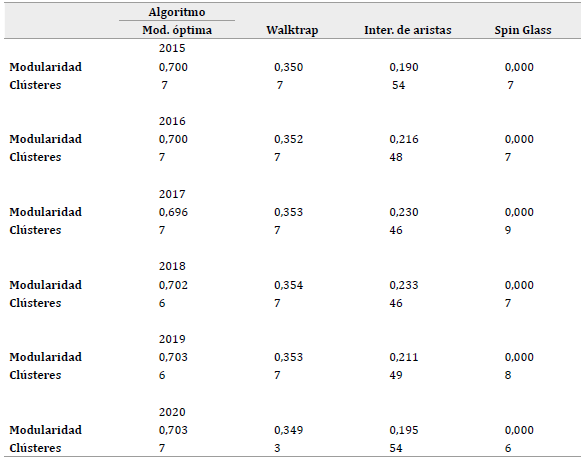
Para determinar la estructura inherente a la MIP de la economía colombiana y sus cambios, es necesario identificar las comunidades de actividades para cada año. Empleando los algoritmos intermediación de aristas, modularidad óptima, Walktrap y Spin Glass, encontramos el número de clústeres sugeridos por cada algoritmo y su respectiva modularidad. En la Tabla 1 se reportan los resultados para 2015 y 2021 y en el Anexo 1 y 2 se reportan los resultados para los otros años.
Tabla 1 Modularidad y número de clústeres para cada uno de los algoritmos de detección de comunidades para los años 2005y 2021
| Algoritmo | 2005 | 2021 | ||
|---|---|---|---|---|
| Modularidad | Número de clústeres | Modularidad | Número de clústeres | |
| Modularidad óptima | 0,708 | 7 | 0,700 | 7 |
| Walktrap | 0,344 | 6 | 0,359 | 4 |
| Intermediación de aristas | 0,196 | 49 | 0,223 | 48 |
| Spin Glass | 0,001 | 8 | 0,000 | 9 |
Fuente: elaboración de los autores.
Tanto para 2005 como para 2021, el algoritmo de modularidad óptima es el que presenta la modularidad más alta. Este algoritmo sugiere la existencia de 7 comunidades para ambos años. Es más, para los otros 15 años, este mismo algoritmo es el que genera la mayor estructura modular en la red (Anexo 1 y 2). Para la mayoría de los años este algoritmo sugiere 7 comunidades, a excepción de 2013, 2018 y 2019, para los que sugiere 6 comunidades. Para cada uno de los años la modularidad que se alcanza es relativamente alta, rondando valores de 0,7; es decir, se logra una partición de la red en comunidades relativamente buena. Los trabajos de Araújo y Faustino (2017), y Xu y Liang (2019) no reportan si se emplea la modularidad para la selección del número de comunidades. Domínguez et al. (2021) emplean dos algoritmos basados en la modularidad, pero no reportan la modularidad para sus ejercicios.
Los resultados muestran que en la economía colombiana existieron entre 6 y 7 comunidades a lo largo de los años estudiados. En la Figura 3 se muestran cuántas ramas de actividad se asignaron a cada una de las comunidades encontradas por año. Se observa que la distribución es relativamente estable en términos del número de ramas por comunidad de un año a otro; sin embargo, las comunidades 4, 5 y 6 son las que experimentan el mayor cambio en el número de membresías. Por ejemplo, en los años 2018 y 2019 la comunidad 5 no tenía ninguna actividad.
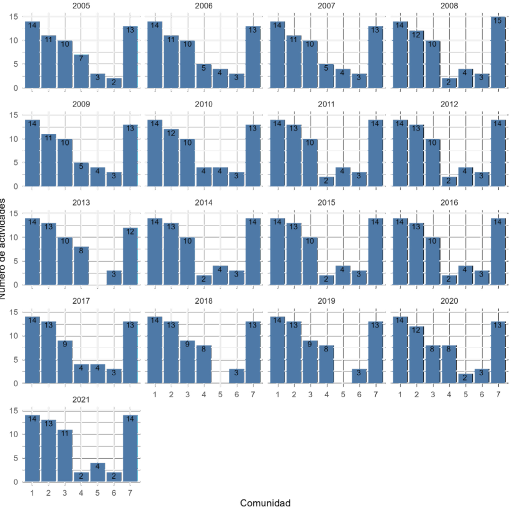
En la Tabla 2 se muestra la lista de las actividades con sus respectivas comunidades para los años 2005, 2010, 2015 y 20218. Los resultados de cada año pueden visualizarse en grafos como la Figura 1, que representa las comunidades de 2015, en donde los colores indican la membresía de las actividades.
Tabla 2 Membrecía a las comunidades de las ramas de actividad económica para los años 2005, 2010, 2015 y 2021
| Código | 2005 | 2010 | 2015 | 2021 | Nombre de la rama de actividad económica |
|---|---|---|---|---|---|
| A0101-01 | 1 | 1 | 1 | 1 | Agricultura y actividades de servicios conexas |
| A0101-02 | 1 | 1 | 1 | 1 | Cultivo permanente de café |
| A0102 | 1 | 1 | 1 | 1 | Ganadería, caza y actividades de servicios conexas |
| A03 | 1 | 1 | 1 | 1 |
Pesca y acuicultura Procesamiento y conservación de carne y productos cárnicos de bovinos, bufalinos, porcinos y otras carnes |
| 023 + 024 + 025 | 1 | 1 | 1 | 1 | n.c.p.; procesamiento y conservación de carne y productos cárnicos de aves de corral y procesamiento y conservación de pescados, crustáceos y moluscos |
| 026 | 1 | 1 | 1 | 1 | Elaboración de aceites y grasas de origen vegetal y animal |
| 027 | 1 | 1 | 1 | 1 |
Elaboración de productos lácteos Elaboración de productos de molinería, almidones y productos derivados del almidón; elaboración de productos |
| 028 + 032 + 035 | 1 | 1 | 1 | 1 | de panadería; elaboración de macarrones, fideos, alcuzcuz y productos farináceos similares, y elaboración de alimentos preparados para animales |
| 029 | 1 | 1 | 1 | 1 | Elaboración de productos de café |
| 030+031 | 1 | 1 | 1 | 1 | Elaboración de azúcar y elaboración de panela |
| 033 | 1 | 1 | 1 | 1 | Elaboración de cacao, chocolate y productos de confitería Procesamiento y conservación de frutas, legumbres, hortalizas y tubérculos; elaboración de otros productos |
| 034 | 1 | 1 | 1 | 1 | alimenticios (platos preparados y conservados mediante enlatado o congelado, elaboración de sopas y caldos en estado sólidos, polvo o instantáneas entre otros) |
| 036 | 1 | 1 | 1 | 1 | Elaboración de bebidas (incluido el hielo) y elaboración de productos de tabaco |
| I | 1 | 1 | 1 | 1 | Alojamiento y servicios de comida |
Fuente: elaboración de los autores.
Tabla 2A Asignación de las ramas de actividad económica a las comunidades encontradas con el algoritmo de mayor modularidad para los años 2005, 2010,2015y 2021

Fuente: cálculos de los autores.
La comunidad 1 corresponde principalmente a actividades agrícolas; la comunidad 2 corresponde a actividades extractivas de madera, minerales metálicos, junto a actividades de fabricación de productos metalúrgicos básicos, muebles de madera y edificaciones; la comunidad 3 corresponde a la extracción, refinación y distribución de fuentes de energía y el transporte aéreo y terrestre. Estas tres comunidades se mantienen entre los años.
Por otra parte, en 2005 la comunidad 4 correspondía a actividades manufactureras del sector textil, curtido de cueros, fabricación de papel, plásticos y sustancias químicas; la comunidad 5 contiene actividades de fabricación de vehículos y maquinaria; la comunidad 6 corresponde a otras industrias manufactureras y actividades de salud; la comunidad 7 está constituida por actividades de servicios. La mayoría de estas actividades se ubican en la comunidad 5 en el 2021, por lo que siguen estando juntas.
En la Figura 4 se pueden visualizar los cambios de membresías de las ramas de actividad año tras año. Las comunidades 1, 2 y 3 son muy estables, mientras que las comunidades 4, 5, 6 y 7 tienen cambios. Los mayores cambios se presentan en 2020, lo cual coincide con la emergencia sanitaria por covid-19; sin embargo, en 2021 las comunidades se configuran de manera similar a 2019. Además de esto, entre 2013 y 2014 se presentan movimientos entre las comunidades 4 y 7, específicamente las actividades de fabricación de papel y actividades de impesión, cambio que se revirtió el año siguiente.
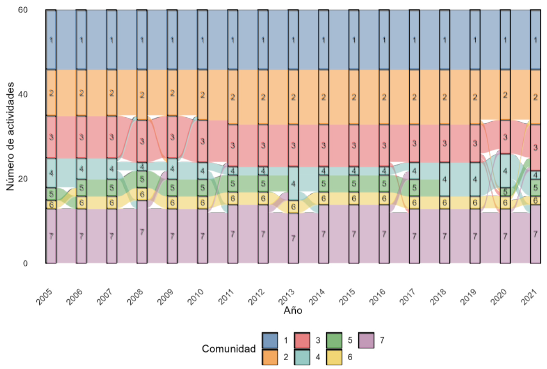
Nota: el tamaño de flujo de una caja a otra representa el número de ramas que cambiaron de una comunidad a otra en un año. Por ejemplo, la línea azul clara que pasa de la caja cuatro de la columna de 2013 a la caja siete de la columna 2014, representa un desplazamiento de ramas de la comunidad 4 a la 7 entre 2013 y 2014.
Fuente: cálculos de los autores.
Figura 4 Cambios de actividades entre comunidades de un año a otro (2005-2021)
Según las métricas de estabilidad de un año a otro de la comunidades (H, C, VM, RI y ARI) no se presentan grandes cambios en la estructura de la red (Figura 5); todas las medidas se mantienen por encima de 0,90, lo que indica una alta estabilidad en el corto plazo. Se evidencia un cambio sustancial entre los años 2020 y 2021, probablemente debido al choque de la emergencia sanitaria del covid-19. No obstante la caída en los indicadores, estos siguen tomando valores relativamente altos entre 2021 y 2020, lo cual no permite afirmar que existan fuertes cambios en la estructura de las membresías a las comunidades.

Nota: se compara un año con respecto al año inmediatamente anterior; por ejemplo, las membrecías a las comunidades de 2006 se comparan con respecto a 2005, y la métrica de estabilidad resultante se registra para 2006.
Fuente: cálculos de los autores.
Figura 5 Métricas de estabilidad de las comunidades año a año (2006-2021)
Las métricas que se presentan en la Figura 5 están midiendo el cambio en las comunidades de un año a otro. Es decir, estas medidas son de cambio en el corto plazo. Para capturar cambios que ocurren en periodos más largos, procedemos a comparar los años 2010, 2015 y 2020 con el año que corresponda a 5 años atrás (Figura 6). Al comparar estas redes en el mediano plazo (5 años) se encuentra un cambio levemente más grande al comparar 2010 y 2020 con respecto a 2015. Las métricas calculadas bajan de 0,9, indicando un cambio relativamente bajo en las membresías de las actividades durante estos periodos. El valor de estos indicadores no es suficientemente bajo para afirmar que exista un cambio estructural en la economía colombiana en esos periodos de 5 años.
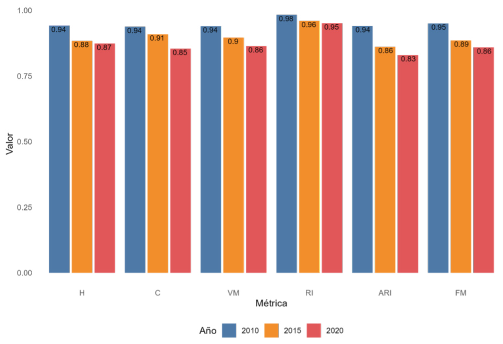
Nota: se compara un año con respecto a cinco años atrás; por ejemplo, las membrecías a las comunidades de 2010 se comparan con respecto al 2005 y la métrica de estabilidad resultante se registra para el 2010.
Fuente: cálculos de los autores.
Figura 6 Métricas de estabilidad con respecto a 5 años atrás (2010, 2015,2020)
Así como en el ejercicio anterior, en la Figura 7 se puede visualizar el flujo de sectores para estos periodos de 5 años. Los resultados evidencian que sí hay cambios en las comunidades de la red que refleja las interconexiones implícitas en las MIP de la economía colombiana durante el periodo 2005-2020; pero estos cambios no son sustanciales, de manera que no se puede afirmar que existan fuertes cambios estructurales; al menos desde un punto de vista de comunidades.
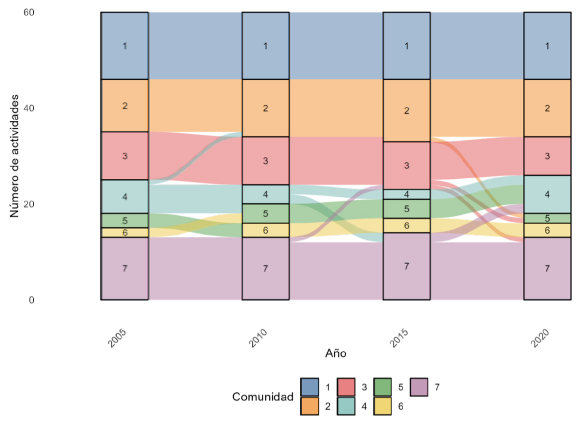
Nota: el tamaño de un flujo de una caja a otra representa el número de ramas que cambiaron de una comunidad a otra. Por ejemplo, la línea azul clara que pasa de la caja 4 de la columna de 2005 a la caja 2 de la columna de 2010 representa un desplazamiento de ramas de la comunidad 4 a la 2 entre 2005 y 2010.
Fuente: cálculos de los autores.
Figura 7 Flujo de ramas de actividad económica entre comunidades cada 5 años (2005, 2010,2015, 2020)
COMENTARIOS FINALES
Las MIP del SCN implican una red de interconexiones entre las ramas de actividad económica que pueden ser analizadas con herramientas de la teoría de redes. Empleando estas herramientas y una base de datos de MIP para los años de 2005 a 2022, construida por los autores de este estudio, se encuentran resultados interesantes para Colombia.
El análisis de la evolución de la densidad y el diámetro de la red muestra que la economía colombiana está cada vez más interconectada y presenta cadenas de valor más largas, lo cual sugiere una mayor sofisticación del aparato productivo que incorpora más sectores económicos.
Se encontraron entre 6 y 7 comunidades de ramas de actividad económica para el periodo de estudio. Estas son actividades agrícolas; actividades extractivas y construcción, extracción, refinación y distribución de fuentes de energía; actividades manufactureras; actividades de fabricación de vehículos y maquinaria; otras industrias manufactureras; actividades de salud, y actividades de servicios como información y comunicaciones.
En el análisis de corto plazo se evidenciaron cambios leves en la estructura de la economía colombiana especialmente en el año 2008, 2013, 2017 y 2020. Estos cambios parecen coincidir con choques exógenos en la economía, la posible causalidad entre estos debería ser estudiada en una futura investigación. Los cambios en la estructura de la economía colombiana son un poco más evidentes en un análisis de mediano plazo (periodos de 5 años), donde se ven cambios del año 2010 al 2015 y del 2015 al 2020.
Los resultados evidencian que sí hay cambios en la red de interconexiones que se reflejan en la MIP de la economía colombiana durante el periodo 2005-2021, pero no son sustanciales, de manera que no se puede afirmar que existan fuertes cambios estructurales, al menos desde un punto de vista de comunidades.
Además del análisis de la economía colombiana, este trabajo aporta a la literatura en varios frentes. En primer lugar, se construyeron las MIP para el periodo 2005-2021 a partir de los cuadros oferta-utilización publicados por el DANE9.
En segundo lugar, este documento presenta una aproximación metodológica que puede aplicarse para analizar las cuentas nacionales de otros países, ningún aspecto de la metodología empleada aquí es específico para el caso colombiano. Además, los resultados de los análisis de redes podrían no solo emplearse para caracterizar las relaciones entre las ramas de actividad de la estructura productiva de un país, sino también para predecir sus tendencias y cambios futuros. Por ejemplo, para los inversionistas en un país, la identificación de la tendencia de una rama de actividad en términos de su puntaje de autoridad puede representar una oportunidad de crecimiento, ya sea porque está comprando o vendiendo más. Asimismo, para las políticas económicas, el reconocimiento de cuáles son las actividades más críticas para mantener la estabilidad de la red económica permite tomar medidas para proteger y fomentar su desarrollo.
Finalmente, hasta donde llega el conocimiento de los autores, los análisis de estabilidad no se han intentado anteriormente en el contexto del análisis de redes. Todo lo anterior fue aplicado por primera vez al caso colombiano en un periodo de estudio extenso. En esta línea, se sugiere que futuras investigaciones analicen la causalidad entre eventos y los cambios coyunturales encontrados en la estructura económica colombiana, la exploración de otros periodos de estudio y otras metodologías para detectar cambios estructurales en redes. Así mismo, es importante explorar otro tipo de técnicas para detectar comportamiento anómalos en redes que podrían ser útiles para detectar cambios estructurales en las redes implícitas de las MIP.